Journal influence
Bookmark
Next issue
Module for morphological disambiguation: architecture and database organization
Abstract:Corpus data management systems today help to solve a number of urgent problems connected with the computer linguistics. Particularly, this is the source documents processing, automatic morphological markup of them, storage and modification of corpus data with morphological markup, the search in-quiry execution (selecting data), and integration with other applications. In the automatic morphological text markup of the electronic corpus, there is a problem when two or more sets of morphological properties marked out the same word form. It is a morphological ambiguity. The authors developed a module for manual resolution of morphological ambiguity, which can help in solving this problem. This article discusses the architecture of the module for resolving the morpholog-ical ambiguity of the corpus data management system developed for managing the Tatar corpus, and describes the organization of the database based on the transactional approach to data storage. The article proposes in detail the architecture of the rupture modulus of the software morphological ambiguousness of corpus data. It is for the tartaric corpus management. In addition, the author de-scribed the database organization. It relies on the transactional way to the strategy for the data storage. The paper in detail describes the architecture of the module software, which is part of the Tugan Tel corpus data management system. Due to the architecture of the corpus data management system, such modules can quickly integrate into the system and have no effect on the other module operation. The module database organization for the morphological disambiguation described in the paper, al-low going over for solving the other computer linguistic problems, such as automatic morphological disambiguation and improving automatic morphological markup of texts in the electronic corpus.
Аннотация:Системы управления корпусными данными помогают решать целый ряд актуальных задач, связанных с компьютерной лингвистикой. В частности, это обработка исходных документов, их автоматическая морфологическая разметка, хранение и изменение корпусных данных с морфологической разметкой, выполнение поисковых запросов (выборок данных), интеграция с другими приложениями. При автоматической морфологической разметке текстов электронного корпуса часто возникает проблема, когда одна и та же словоформа может быть размечена двумя и более наборами морфологических свойств, что называется морфологической неоднозначностью. Авторами был разработан модуль для ручного снятия морфологической неоднозначности, который может помочь в решении проблемы. В данной статье рассмотрена архитектура модуля разрешения морфологической неоднозначности системы управления корпусными данными, разработанной для управления татарским корпусом, и описана организация БД, основанная на транзакционном подходе к хранению данных. В статье подробно описана архитектура программной части модуля, который является частью системы управления корпусными данными «Туган Тел». Благодаря архитектуре системы управления корпусными данными подобные модули могут быть быстро интегрированы в систему и не влиять на работу других модулей. Описанная в статье организация БД модуля разрешения морфологической неоднозначности позволяет перейти к решению других задач компьютерной лингвистики, таких как автоматическое разрешение морфологической неоднозначности и улучшение автоматической морфологической разметки текстов электронного корпуса.
| Authors: D.R. Mukhamedshin (damirmuh@gmail.com) - Institute of Applied Semiotics of the Tatarstan Academy of Sciences, Kazan, Russia, D.Sh. Sulejmanov (khusainov.aidar@gmail.com) - Institute of Applied Semiotics of the Tatarstan Academy of Sciences, Kazan Federal University (Professor), Kazan, Russia, Ph.D | |
| Keywords: DBMS, database, system architecture, corpus data, morphological ambiguity |
|
| Page views: 6681 |
PDF version article Full issue in PDF (4.91Mb) |
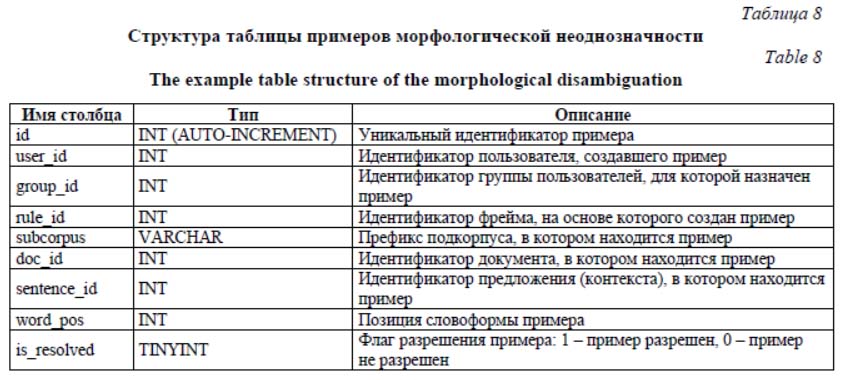
Автоматическая морфологическая разметка достаточно больших объемов текстов неизбежно приводит к появлению примеров морфологической неоднозначности [1]. Одна и та же словоформа может быть размечена алгоритмом различными наборами морфологических свойств. Без информации о семантике контекста при автоматической морфологической разметке невозможно принять решение о корректности того или иного набора морфологических свойств в каждом конкретном случае морфо- логической неоднозначности. Имеется ряд способов, которые могут помочь в снятии проблемы, одним из них является ручное разрешение морфологической неоднозначности экспертом [2, 3]. Разработанный авторами модуль является частью системы управления татарским корпусом (http://tugantel.tatar) [4] и направлен на снятие морфологической неоднозначности в ресурсах татарского национального корпуса [5]. Корректная морфологическая разметка текстов позволяет более качественно выявлять закономерности языка, использовать корпус для различных задач компьютерной лингвистики. Основной функционал модуля Процесс разрешения морфологической неоднозначности делится на несколько этапов, в каждом из которых принимают участие пользователи с различными ролями. Модуль ограничивает права доступа для следующих ролей: «Гость», «Аннотатор», «Главный аннотатор», «Администратор» при помощи модели ShieldModel, являющейся частью системы управления корпусом «Туган Тел», и модели AmbiguityUserModel. Пользователь с правами доступа «Гость» имеет право просматривать страницу авторизации и отправлять данные при помощи формы авторизации, введя в нее свои логин и пароль. При попытке авторизации данные обрабатываются контроллером и моделью авторизации модуля AmbiguityAuthModel. При попытке воспользоваться другим функционалом модуля система сообщит об ошибке – «Доступ запрещен». Пользователь с правами доступа «Аннотатор» имеет право просматривать и производить действия с примерами для разрешения морфологической неоднозначности, назначенными для группы пользователей авторизованного пользователя, а также пропущенныеми в процессе разрешения. При просмотре примеров есть возможность выбрать определенный документ (см. http://www.swsys.ru/uploaded/image/ 2020-1/2020-1-dop/13.jpg), фрейм или просмотреть все примеры. Список документов или фреймов для разрешения морфологической неоднозначности формируется в модели AmbiguitySamplesModel, соответственно, при помощи методов getDocs и getRules. Список примеров для разрешения морфологической неоднозначности также формируется в модели AmbiguitySamplesModel при помощи метода search, который, в свою очередь, возвращает набор экземпляров класса AmbiguitySampleModel. Далее список выводится в браузере пользователя, как это показано на рисунке (см. http://www.swsys.ru/uploaded/image/2020-1/2020-1-dop/17.jpg). Пока пользователь работает над разрешением морфологической неоднозначности, модуль записывает все его действия при помощи модели AmbiguityTrackingModel. · Working – общая работа над примерами; используется для анализа полезного времени, потраченного пользователем на разрешение морфологической неоднозначности, при этом данное действие автоматически останавливается, если пользователь отвлекается (переключается в другое окно, не производит никаких действий на странице продолжительное время). · Choose – выбор корректного, по мнению пользователя, разбора из предложенного списка. · Miss – пропуск примера; к нему в дальнейшем можно вернуться в списке пропущенных примеров. · Remove – удаление примера; необходимо, если в исходном тексте имеются артефактные включения и их нужно удалить. · Correct – корректирование примера, заключающееся в редактировании содержимого словоформы или ручном вводе морфологического разбора; · Copy, Cut, Paste – действия с буфером обмена (записываются в случае копирования, вырезания или вставки текста на странице); · Blur, Focus – действия с окном страницы (записываются в случае переключения на другое окно) и возврат в текущее окно браузера. После завершения работы над контекстом пользователь сохраняет все изменения. Сохраненный контекст исчезает из списка, и, когда в списке остаются пять контекстов, автоматически загружаются следующие контексты. Таким образом, процесс разрешения морфологической неоднозначности реализуется на всем множестве неоднозначных контекстов коллекции текстов. Для удобства модуль также выводит количество оставшихся неразрешенных контекстов. Пользователь с правами «Главный аннотатор», кроме функционала, доступного пользователям с правами «Аннотатор», может также производить проверку результатов разрешения морфологической неоднозначности, выполненного аннотаторами первого уровня. Также пользователю с правами «Главный аннотатор» доступен функционал добавления и редактирования фреймов (см. http://www.swsys.ru/uploaded/image/2020-1/2020-1-dop/14.jpg), которые содержат наборы правил для подбора примеров морфологической неоднозначности. Функции добавления и редактирования фреймов обрабатываются моделью AmbiguityRuleModel. В интерфейсе добавления фрейма можно указать необходимые для сохранения и выборки примеров из корпуса перечисленные далее параметры. · Название фрейма, отражающее содержание примеров или их назначение. · Тип поиска: по словоформе или по лемме. Также поддерживается поиск по списку словоформ или лемм в соответствии с синтаксисом (словоформы или леммы можно перечислить, разделив их знаком «|»). · Формула поискового запроса. Указывается в таком же формате, как в URL результатов поиска поискового модуля системы управления корпусными данными «Туган Тел». · Ограничение – количество примеров, которое необходимо получить в создаваемом фрейме. Может быть любым неотрицательным числом. Ограничение «0» модуль интерпретирует как отсутствие ограничений и добавит максимально возможное количество примеров, соответствующих параметрам, указанным во фрейме. · Включить словоформы без многозначности. Установка данного флажка добавляет в генерируемые примеры словоформы, в которых нет многозначности, то есть при автоматической морфологической разметке алгоритмом предложен один морфологический разбор. · Подкорпус. Чтобы подобрать примеры из определенного подкорпуса, необходимо выбрать его из списка. По умолчанию используется подкорпус для разрешения многозначности. В списке также имеется буферный подкорпус, созданный для безопасной работы с копией основного корпуса в модуле ручного снятия многозначности. · Документ (документы). Чтобы подобрать примеры из определенных документов, необходимо указать их в одном из форматов: - список идентификаторов документа, по одному в строке (идентификаторы показываются в результатах поиска поискового модуля системы управления корпусными данными); - список названий файлов документов, по одному в строке (показываются в результатах поиска поискового модуля системы управления корпусными данными); - начало содержания документа (можно указать первые 20–30 строк из искомого документа, этот способ можно использовать, если идентификатор или название файла документа неизвестны). · Пользователю с правами «Главный аннотатор» и «Администратор» также доступен функционал управления пользователями, включающий функции добавления, редактирования пользователей и групп пользователей. Действия, связанные с пользователями и группами пользователей, обрабатываются моделями AmbiguityUserModel и AmbiguityGroupModel соответственно. Архитектура модуля
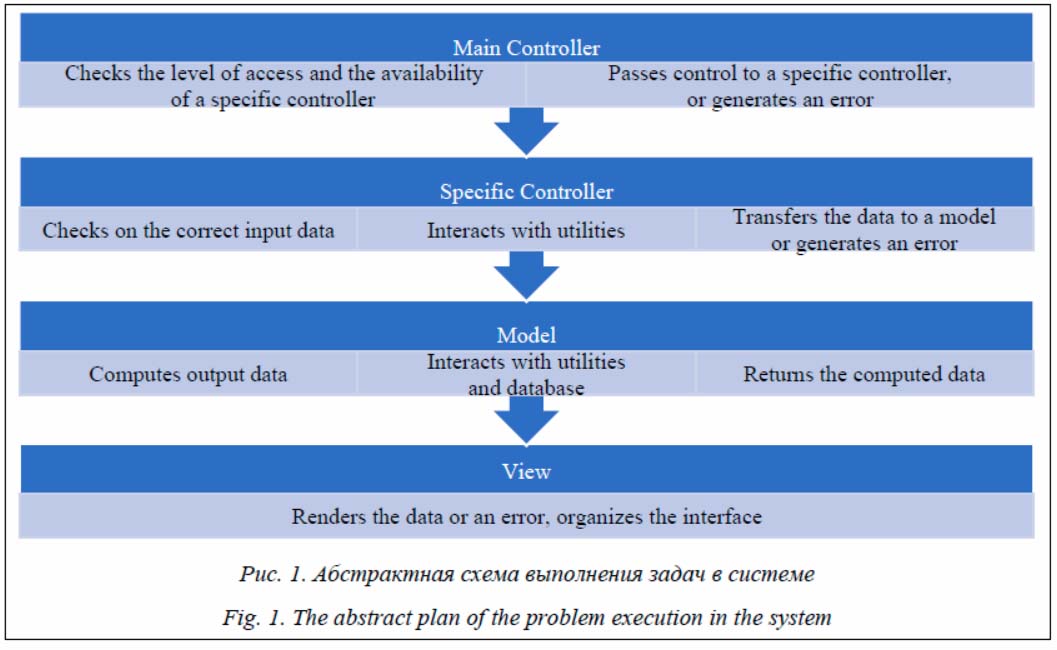
Работа системы начинается с запроса (Request), который приходит в основной контроллер (MainControl). Основной контроллер обеспечивает безопасность при помощи компонента ShieldModel, который, в свою очередь, использует объект очереди (Queue). Если ShieldModel считает запрос безопасным, контроль передается специальному контроллеру в зависимости от типа запрашиваемой задачи. В модуле разрешения морфологической неоднозначности используются 11 специальных контроллеров: AmbiguityDocumentControl – контроллер документов, AmbiguityGroupControl и AmbiguityGroupsControl – контроллеры групп пользователей, AmbiguityHistoryCon- trol – контроллер истории, AmbiguityRule- Control и AmbiguityRulesControl – контроллеры фреймов, AmbiguitySamplesControl – контроллер примеров, AmbiguityStatisticsControl – контроллер статистики, AmbiguityTrackingControl – контроллер отслеживания, AmbiguityUserControl и AmbiguityUsersControl – контроллеры пользователей. После проверки и фильтрации данных система передает контроль в модель, соответствующую запрошенному действию: Ambi- guityDocumentModel, AmbiguityGroupModel, AmbiguityGroupsModel, AmbiguityHistoryModel, AmbiguityRuleModel, AmbiguityRulesModel, AmbiguitySamplesModel, AmbiguityStatisticsModel, AmbiguityTrackingModel, AmbiguityUserModel, AmbiguityUsersModel. Все модели используют модель БД DB, которая, в свою очередь, использует модель Cache для кэширования. После выполнения действия моделью контроль возвращается к контроллеру, откуда данные передаются в Вид (View). Последний использует данные и соответствующие шаблоны страниц для генерации документа HTML или возвращает данные в формате JSON в зависимости от запрошенного формата выходных данных. Архитектура БД Хранение корпусных данных. В системе управления корпусными данными «Туган Тел» основные данные корпусов хранятся в таблицах СУБД MySQL [7]: - Docs – таблица документов электронного корпуса; - Sentences – таблица предложений (контекстов), которые являются частями документов электронного корпуса; - Wordforms – таблица обратного индекса, используемая для быстрого поиска по корпусу, где хранится информация о словоформах и их морфологических разборах. Таблица документов представляется простой структурой для хранения содержимого и главных метаданных документов электронного корпуса. Структура таблицы документов представлена в таблице 1. Таблица 1 Структура таблицы документов электронного корпуса Table 1 The document table structure of the electronic corpus
Структура таблицы предложений (контекстов) предназначена для хранения содержимого предложений (контекстов), которые являются частями документов электронного корпуса, и представлена в таблице 2. Таблица 2 Структура таблицы предложений (контекстов) Table 2 The suggestion table structure (contexts)
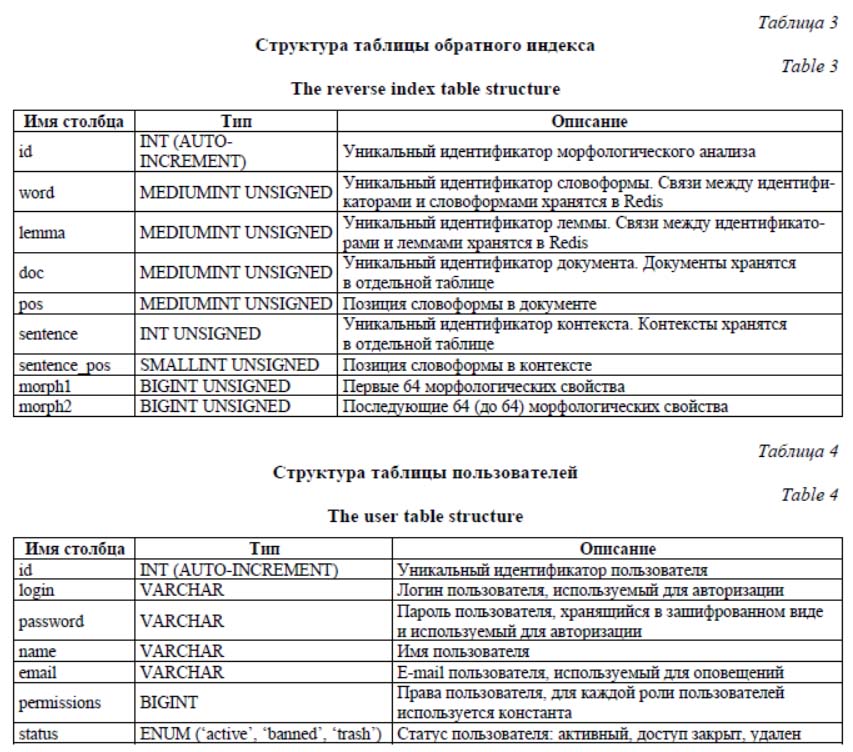
Таблица обратного индекса [8] хранит в себе информацию о всех морфологических разборах каждой словоформы документа электронного корпуса. Структура таблицы обратного индекса показана в таблице 3. БД модуля разрешения морфологической неоднозначности. Данные модуля разрешения морфологической неоднозначности также хра- нятся в таблицах СУБД MySQL. Архитектура БД модуля позволяет хранить все транзакции пользователей, а не конечный результат – документы и предложения со снятой морфоло- гической неоднозначностью. Такой подход позволяет получить результаты на различных
Для реализации функционала групп пользователей используются две таблицы: ‘ambiguity_groups’ для хранения информации о группах пользователей, ‘ambiguity_groups_users’ для хранения связей между пользователями и группами пользователей. Их структуры показаны в таблицах 5 и 6. В таблице связей используется составной индекс типа UNIQUE [9] по обоим столбцам, чтобы исключить возможность дублирования связей. Таблица 5 Структура таблицы групп пользователей Table 5 The group user table structure
Таблица 6 Структура таблицы связей между пользователями и группами пользователей Table 6 The connection table structure between the users and the group users
В таблице фреймов ‘ambiguity_rules’ хранятся правила формирования примеров морфологической неоднозначности. Структура ее и назначение столбцов показаны в таблице 7. Таблица 7 Структура таблицы фреймов Table 7 The frame table structure
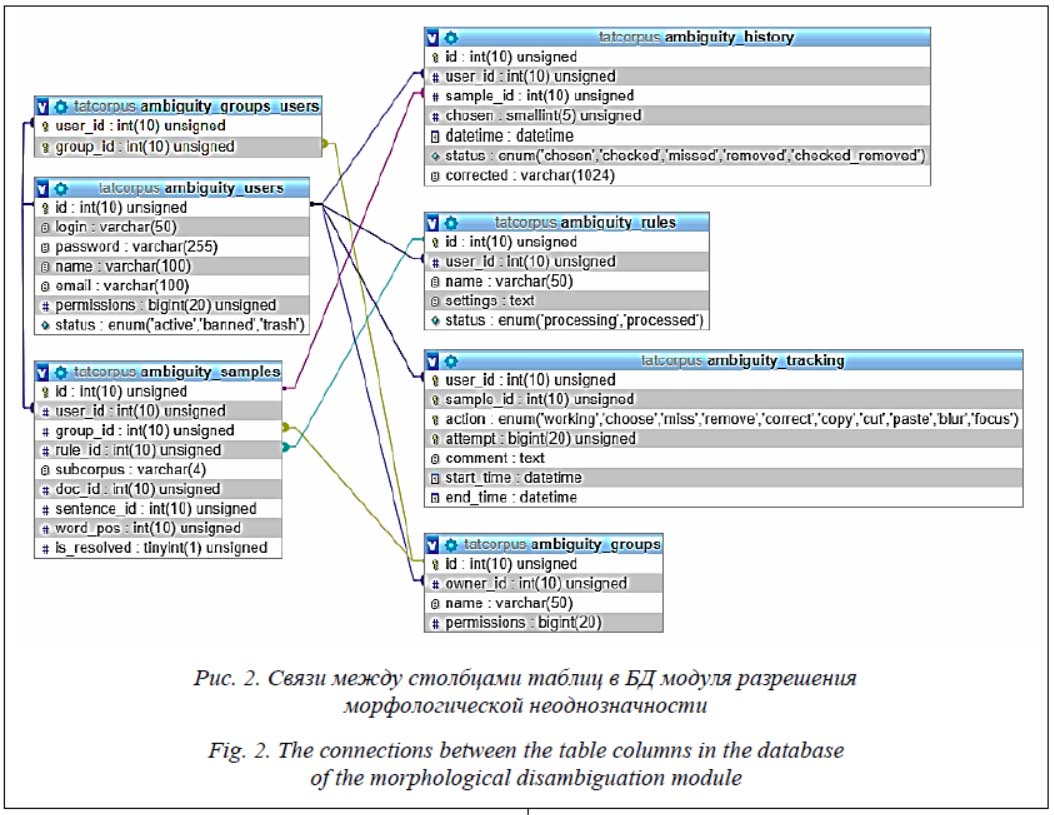
При работе пользователей над примерами модуль записывает каждое действие, произведенное как над примерами морфологической неоднозначности, так и в процессе работы над ними. Такие транзакции хранятся в двух таблицах: в ‘ambiguity_history’ хранятся основные транзакции над примерами, в ‘ambiguity_ tracking’ – другие действия пользователей для анализа процесса работы (см. http://www.swsys. ru/uploaded/image/2020-1/2020-1-dop/18.jpg). Представленные таблицы позволяют полностью реализовать функционал модуля разрешения морфологической неоднозначности. Для обеспечения целостности и согласованности данных в БД также имеются связи [10] между столбцами, которые показаны на рисунке 2.
Заключение Архитектура модуля и организация БД, описанные в данной статье, используются в модуле разрешения морфологической неоднозначности системы управления корпусными данными, который работает совместно с электронным корпусом татарского языка «Туган Тел». Представленные методы хранения данных о разрешении примеров морфологической неоднозначности обеспечивают необходимую полноту данных для дальнейшего сохранения результатов в виде документов со снятой морфологической неоднозначностью. Использование транзакционного подхода к хранению данных позволяет решить целый ряд проблем. В данной статье описаны лишь некоторые из них. В будущем планируется исполь- зовать полученные в процессе работы данные в Представленный подход к решению проблем морфологической неоднозначности для лингвистических корпусов дает возможность использовать разработанный модуль и систему управления корпусными данными в целом не только для Электронного корпуса текстов на татарском языке, но и для корпусов других языков без существенных изменений в системе. Литература 1. Gilmullin R., Gataullin R. Morphological analysis system of the tatar language. Proc. 9th ICCCI, Springer Publ., Nicosia, Cyprus, 2017, pp. 519–528. DOI: 10.1007/978-3-319-67077-5_50. 2. Gataullin R., Suleimanov D., Khakimov B., Gilmullin R. Context-based rules for grammatical disambiguation in the Tatar language. Proc. 9th ICCCI, Springer, Nicosia, Cyprus, 2017, pp. 529–537. DOI: 10.1007/978-3-319-67077-5_51. 3. Хакимов Б.Э., Гильмуллин Р.А., Гатауллин Р.Р. Разрешение грамматической многозначности в корпусе татарского языка // Учен. зап. Казан. ун-та. Сер. Гуманит. науки. 2014. Т. 156. № 5. С. 236–244. 4. «Tugan Tel» Tatar National Corpus Homepage. URL: http://tugantel.tatar/?lang=en (дата обращения: 01.10.2019). 5. Suleimanov D., Gatiatullin A., Khakimov B., Nevzorova O., Gilmullin R. National corpus of the Tatar language “Tugan Tel”: grammatical annotation and implementation. Procedia – Social and Behavioral Sciences, 2013, vol. 95, pp. 68–74. DOI: 10.1016/j.sbspro.2013.10.623. 6. Leff A., Rayfield J.T. Web-application development using the model/view/controller design pattern. Proc. Fifth IEEE Intern. EDOC Conf., 2001, pp. 118–127. DOI: 10.1109/EDOC.2001.950428. 7. DuBois P. MySQL. Pearson Education, 2008, 1224 p. 8. Croft W.B., Metzler D., Strohman T. Search engines: Information retrieval in practice. Addison-Wesley, 2010, vol. 520, pp. 131–141. 9. MySQL 5.6 Reference Manual 19.6.1 Partitioning Keys, Primary Keys, and Unique Keys. URL: https://dev.mysql.com/doc/refman/5.6/en/partitioning-limitations-partitioning-keys-unique-keys.html (дата обращения: 01.10.2019). 10. MySQL 5.6 Reference Manual 13.1.17.6 Using FOREIGN KEY Constraints. URL: https://dev. mysql.com/doc/refman/5.6/en/create-table-foreign-keys.html (дата обращения: 01.10.2019). 11. Gilmullin R., Khakimov B., Gataullin R. A neural network approach to morphological disambiguation based on the lstm architecture in the national corpus of the tatar language. Proc. Intern. Workshop CMLS, 2018, vol. 2303, p. 32. URL: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85060582291&partnerID=40&md5=c4269526b6dae5e311f7c40033a904cb (дата обращения: 01.10. 2019). References
|
| Permanent link: http://swsys.ru/index.php?page=article&id=4675&lang=en |
Print version Full issue in PDF (4.91Mb) |
| The article was published in issue no. № 1, 2020 [ pp. 038-046 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Система корпус-менеджер: архитектура и модели корпусных данных
- Безопасность баз данных: проблемы и перспективы
- Сравнительный анализ СУБД для туристической социальной сети
- Программа для автоматизированной верификации ограничений целостности баз данных
- Технология автоматизированной защиты информационного обслуживания через Интернет
Back to the list of articles