Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Трансдуктивное обучение логистической регрессии в задаче классификации текстов
Аннотация:Во многих задачах текстовой классификации возникают проблемы с получением достаточного количества размеченных документов для обучающей выборки. При этом обычно имеется значительное количество доступных неразмеченных текстов. В данной статье рассматривается метод, используя который, можно значительно улучшить качество классификации, имея довольно малую по сравнению с тестовой выборкой обучающую выборку. Предложен нестандартный способ формирования признакового описания текстов на естественных языках, учитывающий специфику написания новостных текстов. Помимо этого, рассматриваются модификации классического линейного метода решения задачи классификации – логистической регрессии. Для оптимизации параметров логистической регрессии применяется модифицированный метод стохастического градиентного спуска. При обучении регрессии используется модифицированный функционал потерь, увеличивающий зазор между классами. Предлагается также оригинальный метод трансдуктивного обучения логистической регрессии. Для его осуществления вводится специальный функционал качества для неразмеченной коллекции, который позволяет существенно увеличить полноту классификации. Для проверки применимости разработанных модификаций метода логистической регрессии используется процедура обратного скользящего контроля. По результатам приведенных в статье вычисли-тельных экспериментов становится очевидным положительное влияние авторских модификаций метода логистической регрессии и трансдуктивного обучения на качество классификации.
Abstract:In many classification problems there are difficulties with obtaining sufficient amount of labeled documents for train set. At the same time, usually we have many unlabeled documents. This paper describes how to increase the quality of classifier predictions when having relatively small train set in comparison with test set. Non-standard method of forming feature vectors for natural language texts, using peculiar properties of news articles, is described. The paper also describes modifications of a classical linear classifier (logistic regression). We use a modification of st o-chastic gradient descent in order to optimize classifier’s parameters. In addition, we use modified loss functional (enlargin g the margin between classes) to train logistic regression. Apart from that, we suggest original method of transductive learning for logistic regression classifier. To perform transductive learning we define quality functional for unlabeled documents which helps to in crease classification recall sig-nificantly. To test implemented modifications of logistic regression we use “inverse” cross -validation technique. Experi-mental results from using implemented modifications make the positive impact of authors’ modifications of logistic regres-sion classifier and transductive learning on classification quality obvious.
| Авторы: Шаграев А.Г. (alex-shagraev@yandex.ru) - Национальный исследовательский университет «Московский энергетический институт» (аспирант), Москва, Россия, Бочаров И.А. (bocharovia@gmail.com) - Национальный исследовательский университет «Московский энергетический институт», Москва (магистрант), Москва, Россия, Фальк В.Н. (falkvn@yandex.ru) - Национальный исследовательский университет «Московский энергетический институт», Москва, Россия, доктор технических наук | |
| Ключевые слова: трансдуктивное обучение, логистическая регрессия, линейные классификаторы, классификация текстов, машинное обучение |
|
| Keywords: transductive learning, logistic regression, linear classifiers, text categorization, machine learning |
|
| Количество просмотров: 12690 |
Версия для печати Выпуск в формате PDF (6.10Мб) Скачать обложку в формате PDF (0.87Мб) |
Автоматическая классификация текстов– одна из ключевых современных задач информационного поиска, возникающая при разработке поисковых систем, новостных агрегаторов, спам-фильтров и т.д. [1]. Несмотря на огромное количество публикаций, посвященных способам решения этой задачи, вопрос применимости линейных классификаторов до сих пор остается без удовлетворительного ответа: как правило, линейные классификаторы (наивный байесовский классификатор, метод Роккио и др.) значительно уступают в качестве нелинейным [2]. Вместе с тем использование линейных моделей во многих ситуациях является более предпочтительным благодаря таким их свойствам, как компактность, интерпретируемость, высокая скорость применения и т.д. В настоящей работе исследуются возможности улучшения показателей качества классического линейного метода классификации – логистичес- кой регрессии [3] для задачи классификации текстов. Трансдуктивным называется обучение, в процессе которого известно множество объектов, для которых необходимо получить предсказания. Такое обучение применимо на практике и в ситуациях, когда это множество не фиксировано, но изменяется достаточно медленно для того, чтобы при каждом изменении можно было подобрать модель заново. Естественно, что в таких ситуациях может оказаться оправданным применение именно линейных классификаторов в силу высокой скорости их обучения. Кроме того, оказывается, что трансдуктивное обучение является хорошим способом построения более качественных моделей в ситуациях, когда размер обучающей выборки явно недостаточен. Для подтверждения этого факта будем использовать процедуру обратного скользящего контроля [4], заключающегося в том, что размеченная коллекция делится на k приблизительно равных по размеру подмножеств, каждое из которых поочередно является обучающей выборкой, а объеди- нение остальных – тестовой. Такой метод моде- лирует ситуацию, когда тестовый набор сильно превосходит по количеству элементов обучаю- щий в отличие от стандартной процедуры скользящего контроля, в которой каждое подмножест- во поочередно выступает в роли тестовой вы- борки, а объединение остальных – в качестве обучающей. Показатели качества рассматриваемых в настоящей работе методов исследуются на известной новостной коллекции Reuters-21578 [5]. Определения и постановка задачи бинарной классификации В данном разделе в основном приняты такие же терминология и обозначения, как в [6]. Будем считать, что заданы множество объектов X, множество ответов Y={–1, +1} и существует неизвестная целевая функция y*: X→Y, значения которой измерены на некотором конечном подмножестве X¢ÌX. Множество пар Xl={áx, yñïxÎX¢, y=y*(x)}, будем называть обучающей выборкой. Множество объектов для простоты будем считать пространством m-мерных вещественных векторов, то есть X=Rm. Необходимо построить решающую функцию a : X → Y, принадлежащую некоторому классу функций Θ, которая была бы как можно более качественным приближением к целевой функции. Методом обучения µ будем называть функцию, ставящую в соответствие любой обучающей выборке некоторую решающую функцию m(Xl)=a. Для измерения качества приближения целевой функции используем стандартные метрики точности и полноты классификации, измеренные для класса +1:
а в качестве интегральной меры качества – значение F1-меры:
Здесь при помощи квадратных скобок обозначается пороговая функция: Метрики будут измеряться методом многократного стратифицированного скользящего контроля. Задачи мультиклассификации и нечеткой классификации (то есть задачи, в которых |Y|>2, а каждый объект может принадлежать более чем одному классу) будем сводить к нескольким задачам бинарной классификации – по одной на каждый из имеющихся классов. Метрики качества для этих задач вычисляются отдельно по каждому классу, а затем усредняются. Представление текстов на естественных языках Для решения задач классификации текстов на естественных языках необходимо разработать способ представления текста в виде набора вещественных признаков. Другими словами, необходимо иметь возможность составлять признаковое описание произвольного документа. Будем считать, что при определении множества документов, для которых решается задача классификации, задаются непустое множество термов W={w1, w2, …, wm} и множество документов D={d1, d2, …, dN}, каждый из которых является вектором термов: Введем функцию γ: N→[0, 1] и определим с ее помощью функцию ω: D×W→R, значение которой для документа di и слова wj равняется сумме значений функции γ по позициям вхождения слова wj в документ di:
В настоящей работе значения функции γ определяются формулой
где k1 и k2 – параметры алгоритма. Таким образом, всякому документу di ставится в соответствие последовательность
которая и будет являться признаковым описанием документа di. Такой способ получения построения признакового пространства оказывается более адекватным задаче классификации именно новостей, поскольку учитывает специфику их написания: как правило, новости содержат важные для рубрикации слова именно в начале текстов. Значения параметров k1 и k2 можно выбирать по критерию скользящего контроля [4]. Логистическая регрессия В методе логистической регрессии для задачи классификации подбирается вектор коэффициентов b=áw1, w2, …, wmñT, который используется для осуществления предсказаний:
Значения решающей функции в таком случае определяются формулой a(x)=sign(f(x)–τ), где τ – коэффициент, конкретное значение которого выбирается исходя из конкретных требований к показателям качества решающей функции (как правило, с ростом τ увеличивается точность решения, но уменьшается полнота). В частности, коэффициент τ можно выбирать таким образом, чтобы значение F1-меры было максимальным. В методе логистической регрессии параметры модели подбираются оптимизацией величины функционала потерь Выражение для частной производной функционала потерь по k-му компоненту вектора b запишется следующим образом:
Для нахождения величин bk, 1≤k≤m, используется метод градиентного спуска [2]. Впрочем, непосредственное применение метода градиентного спуска на практике оказывается слишком трудоемким, поэтому используются стохастические методы градиентного спуска [7]. В настоящей работе используется модифицированный метод стохастического градиентного спуска, в котором на каждой итерации модификация производится с учетом двух случайно выбранных документов, принадлежащих различным классам [8]. Кроме того, для достижения большего зазора (margin) между классами используется модифицированный функционал потерь [8], в котором аргумент логит-функции смещается на величину o, являющуюся параметром алгоритма, также определяемым методом скользящего контроля:
Трансдуктивное обучение Рассмотрим теперь некоторое конечное множество объектов X¢¢ÌX, на элементах которого значения целевой функции неизвестны. Оптимизация параметров модели с использованием объектов из множества X¢¢ классическим способом, таким образом, невозможна. Введем теперь иной функционал потерь, использующий элементы множества X¢¢:
где λ – параметр алгоритма. Слагаемое Результаты численных экспериментов При проведении экспериментов рассмотрены десять наиболее крупных рубрик. В качестве метрики используется средневзвешенная по рассматриваемым рубрикам величина F1-меры, вычисленная методом многократного стратифицированного скользящего контроля [4]. При этом для демонстрации полезности предлагаемого метода в случае чрезвычайно малой длины обучающей выборки приводятся также результаты «обратного» скользящего контроля, когда только одно из подмножеств выступает в роли обучающего множества, тогда как объединение всех остальных – в качестве тестового.
Из графика видно, что модифицированный метод логистической регрессии (sbLR) значительно превосходит по качеству классический метод (LR) в ситуациях, когда длина обучающей выборки мала по сравнению с длиной тестовой выборки. В ситуации, когда обучающая выборка имеет достаточный размер, показатели методов сравниваются. Таким образом, предлагаемый метод можно использовать в ситуациях, когда получение достаточной по объему обучающей выборки по тем или иным причинам невозможно. Литература 1. Sebastiani F. Machine Learning in Automated Text Categorization. URL: http://nmis.isti.cnr.it/sebastiani/Publications/ ACMCS02.pdf (дата обращения: 05.01.2014). 2. Manning C.D., Raghavan P., Schütze H. Introduction to Information Retrieval. Cambridge, England: Cambridge Univ. Press, 2008. 3. Genkin A., Madigan D., Lewis David D. Sparse logistic regression for text categorization-2005. URL: http://dimacs.rutgers.edu/Research/MMS/loglasso-v3a.pdf (дата обращения: 05.01.2014). 4. Воронцов К.В. Обзор современных исследований по проблеме качества обучения алгоритмов. URL: http://www. ccas.ru/frc/papers/voron04twim.pdf (дата обращения: 05.01.2014). 5. Lewis David D. Representation and Learning in Information Retrieval. PhD Thesis, Department of Computer Science, Univ. of Massachusetts, 1992. 6. Воронцов К.В. Комбинаторные оценки качества обучения по прецедентам // Доклады РАН. 2004. Т. 394. № 2. 7. Bottou L. Large-Scale Machine Learning with Stochastic Gradient Descent. URL: http://leon.bottou.org/publications/pdf/ compstat-2010.pdf (дата обращения: 05.01.2014). 8. Шаграев А.Г., Фальк В.Н. Линейные классификаторы в задаче классификации текстов // Вестн. МЭИ. 2013. № 4. C. 204–209. References 1. Sebastiani F. Machine learning in automated text categorization. Available at: http://nmis.isti.cnr.it/sebastiani/Publications/ ACMCS02.pdf (accessed January 5, 2014). 2. Manning C.D., Raghavan P., Schütze H. Introduction to information retrieval. Cambridge, England, Cambridge Univ. Press, 2008, 496 p. 3. Genkin A., Madigan D., Lewis David D. Sparse logistic regression for text categorization-2005. Available at: http://dimacs.rutgers.edu/Research/MMS/loglasso-v3a.pdf (accessed January 5, 2014). 4. Vorontsov K.V. Obzor sovremennykh issledovaniy po probleme kachestva obucheniya algoritmov [Reviews on modern researches on learning algorithms quality problem]. Available at: http://www.ccas.ru/frc/papers/voron04twim.pdf (accessed January 5, 2014) 5. Lewis David D. Representation and learning in information retrieval. PhD thesis, Department of Computer Science, Univ. of Massachusetts, 1992. 6. Vorontsov K.V. Combinatorical qualitative assessment for use case lerning. Doklady RАN [RAS reports]. 2004, vol. 394, no. 2, pp. 75–178. 7. Bottou L. Large-scale machine learning with stochastic gradient descent. Available at: http://leon.bottou.org/publications/ pdf/compstat-2010.pdf (accessed January 5, 2014). 8. Shagraev A.G., Falk V.N. Linear classifiers for the text classifying problem. Vestnik MEI [The Bulletin of Moscow Power Engineering Institute]. 2013, no. 4, pp. 204–209. |
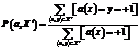 ,
, ,
, .
.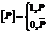 для любого условия P.
для любого условия P.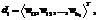 1£i£N (множество всех различных слов, входящих в документ di, будем обозначать b(di)).
1£i£N (множество всех различных слов, входящих в документ di, будем обозначать b(di)).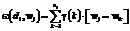 .
.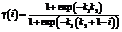 ,
, ,
,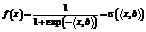 .
.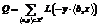 , где L – логит-функция: L(x)=log(1+exp(x)).
, где L – логит-функция: L(x)=log(1+exp(x)). .
.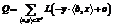 .
.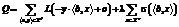 ,
,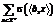 обеспечивает наличие положительных предсказаний на неразмеченной коллекции. Таким образом, потенциальный эффект заключается в повышении полноты классификации на тестовом множестве, что особенно актуально в ситуации недостаточного размера обучающей выборки. При этом присутствие классического функционала потерь не позволяет потерять в точности. Выбором величины коэффициента λ можно регулировать соотношение приобретенной полноты и потерянной точности.
обеспечивает наличие положительных предсказаний на неразмеченной коллекции. Таким образом, потенциальный эффект заключается в повышении полноты классификации на тестовом множестве, что особенно актуально в ситуации недостаточного размера обучающей выборки. При этом присутствие классического функционала потерь не позволяет потерять в точности. Выбором величины коэффициента λ можно регулировать соотношение приобретенной полноты и потерянной точности.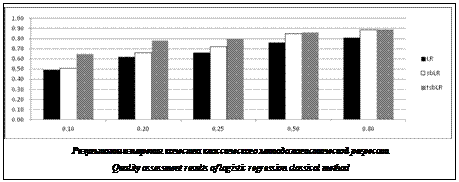 На графике приведены результаты измерения качества классического метода логистической регрессии (LR), стратифицированного метода логистической регрессии со смещениями (sbLR) и трансдуктивного стратифицированного метода логистической регрессии (tsbLR). По горизонтальной оси отложена доля объектов выборки, отбираемых в обучающую коллекцию. Например, если эта доля составляет 0,10, то осуществляется разбиение выборки на десять подмножеств, каждое из которых по очереди выступает в качестве обучающего множества, а объединение остальных – в качестве тестового множества. Значение 0,80 соответствует стандартной процедуре скользящего контроля по пяти подмножествам.
На графике приведены результаты измерения качества классического метода логистической регрессии (LR), стратифицированного метода логистической регрессии со смещениями (sbLR) и трансдуктивного стратифицированного метода логистической регрессии (tsbLR). По горизонтальной оси отложена доля объектов выборки, отбираемых в обучающую коллекцию. Например, если эта доля составляет 0,10, то осуществляется разбиение выборки на десять подмножеств, каждое из которых по очереди выступает в качестве обучающего множества, а объединение остальных – в качестве тестового множества. Значение 0,80 соответствует стандартной процедуре скользящего контроля по пяти подмножествам.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3819&lang=&lang=&like=1 |
Версия для печати Выпуск в формате PDF (6.10Мб) Скачать обложку в формате PDF (0.87Мб) |
| Статья опубликована в выпуске журнала № 2 за 2014 год. [ на стр. 114-118 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Методы автоматической классификации текстов
- Моделирование поведения интеллектуальных агентов на основе методов машинного обучения в моделях конкуренции
- Применение машинного обучения для прогнозирования времени выполнения суперкомпьютерных заданий
- Выделение областей интереса на основе классификации изолиний
- Разработка системы разрешения анафоры на основе методов машинного обучения
Назад, к списку статей