Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Распределенные СУБД и автоматические обновления в службе каталогов
Аннотация:
Abstract:
| Авторы: Аладышев О.С. (aladyshev@jscc.ru) - Межведомственный суперкомпьютерный центр РАН, г. Москва, кандидат технических наук, Шульга Н.Ю. () - , Овсянников А.П. (ovsyannikov@jscc.ru) - Межведомственный суперкомпьютерный центр РАН (ведущий научный сотрудник), Москва, Россия | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 14259 |
Версия для печати Выпуск в формате PDF (1.83Мб) |
Единая система аутентификации и авторизации пользователей – один из компонентов программного обеспечения для высокопроизводительных кластерных установок и один из ключевых элементов информационной системы GRID. На узлах кластера или GRID, работающих под управлением операционной системы с открытыми исходными кодами Linux, доступ к подобной базе данных осуществляется через программные интерфейсы управления службами имен NSS и встраиваемых модулей аутентификации PAM по сетевому протоколу LDAP [1] к серверам службы каталогов. Для гарантированной передачи неискаженной информации от сервера к узлу, протокол LDAP часто инкапсулируется в протоколы SSL/TLS. С ростом количества узлов в кластере требования к производительности и отказоустойчивости службы каталогов также возрастают. При проектировании программно-аппаратного комплекса, реализующего службу каталогов, необходимо также учитывать специфический профиль нагрузки на серверы, а именно: во время запуска новой расчетной задачи количество поступающих за минуту запросов к службе каталогов может на несколько порядков отличаться от среднего количества запросов. Для оценки пиковой нагрузки можно воспользоваться следующей формулой:
Количество запросов в подсистеме NSS зависит от общего количества пользователей в системе и от количества групп управления и доступа к файлам, в которые входит пользователь, от имени которого запускается задача. Для оценки можно считать, что количество запросов к службе каталогов через программный интерфейс NSS в среднем составляет 40 на процесс. Среднее количество запросов к подсистеме PAM не превышает 10 на процесс. Время запуска является варьируемым параметром, редко превышающим порог в несколько десятков секунд. Таким образом, при запуске задачи использующей порядка 100 вычислительных процессов, пиковая нагрузка на службу каталогов составляет десятки тысяч запросов в секунду. Подобную пиковую нагрузку имеет смысл распределить между несколькими серверами, на которых реализован сервис службы каталогов. Информация, получаемая от службы каталогов, необходима для запуска новой задачи и для нормальной работы некоторых системных процессов, выполняющихся на вычислительном узле. Поэтому обеспечение бесперебойного функционирования службы каталогов очень важно для нормального функционирования кластерной установки. В силу того, что вычислительные узлы стараются поддерживать постоянное соединение со службой каталогов, простое увеличение количества серверов, реализующих службу каталогов, является явно недостаточным, так как программный или аппаратный сбой на одном из этих серверов приводит к длительным простоям заранее недетерминированной части вычислительного клас- тера. Рассмотрим более подробно, как вычислительный узел находит сервер службы каталогов. Для этого узел посылает запрос к распределенной иерархической системе серверов службы имен. В результате этого запроса один из серверов возвращает IP-адрес сервера службы каталогов. Если в службе имен зарегистрировано более одного сервера службы каталогов, то в ответе от сервера службы имен в качестве главного сервера будет указан тот IP-адрес, который реже всего указывался в последних ответах от сервера службы имен. Такая реализация оказывается очень эффективной, например, для распределения HTTP-нагрузки при наличии одного сервера имен и нескольких web-серверов. Но в случае с несколькими серверами службы имен такая балансировка приводит к невозможности определения на этапе проектирования того, какой из серверов службы каталогов будет использоваться данным вычислительным узлом, а также какой усложнит процедуру выведения отказавшего сервера из группы серверов службы каталогов. Более правильным является использование протокола динамических обновлений в службе имен [2], а также введение понятия приоритета сервера. Другая особенность, которую необходимо учитывать при использовании службы каталогов в больших кластерных установках или GRID-системах, состоит в том, что протокол LDAP по умолчанию реализован над протоколом транспортного уровня сети Интернет TCP. Количество одновременно доступных соединений по протоколу TCP/IP ограничено 65 тысячами соединений, притом что программный интерфейс select из широко используемого в программном обеспечении с отрытыми исходными кодами стандарта POSIX [3], предназначенный для одновременного опроса состояния активных сетевых соединений с сервером, ограничен 4096 дескрипторами открытых файлов и сетевых соединений. Таким образом, при возникновении ошибок в сетевой инфраструктуре, а также из-за особенности реализации программных модулей NSS и PAM становится понятным ограничение на взаимодействие более чем 700 вычислительных ядер с сервером службы каталогов по одному сетевому адресу IPv4/v6. Эти ограничения приводят к необходимости выделения службе каталогов более одного IPv4/v6 адреса. По причинам, приведенным выше, служба каталогов должна быть реализована в виде информационного кластера и объединена общим доменным именем в службе имен. Распределение нагрузки и повышение отказоустойчивости может быть реализовано в виде нескольких записей с разными приоритетами в динамически обновляемой зоне службы имен. Решить задачу синхронизации информации между узлами информационного кластера можно различными способами в зависимости от характера и частоты обновления информации в службе каталогов. Традиционной схемой передачи обновлений, унаследованной службой каталогов от YP/NIS [4], является схема ведущий-ведомый, в которой четко задана роль центрального репозитария информации. Все изменения информации, хранимой в каталоге, производятся только через основной сервер, которые затем распространяются на ведомые серверы, либо через команды центрального сервера (push-схема), либо периодическими опросами центрального сервера о наличии изменений (pull-схема). Выбор между pull- или push-схемами зависит от количества вспомогательных серверов и от частоты обновлений каталога. Недостатком обеих схем является зависимость от центрального сервера. Так, в случае программного или аппаратного сбоя на центральном сервере обновление каталога невозможно. Кроме того, при использовании pull-схемы возможны задержки при запуске и работе вспомогательных серверов, так как на время обновления каталога доступ к части записей может блокироваться. Более масштабируемым и независимым от аппаратных сбоев является схема с использованием нескольких ведущих серверов, синхронизированных между собой через LDIF-изменения [5]. Идея протокола состоит в том, что для каждого объекта вводятся дополнительные служебные поля, содержащие ревизию объекта и время изменения. Такой алгоритм позволяет избавиться от единой точки отказа службы, но при этом увеличивает общее количество записей в объекте каталога, а также создает избыточную нагрузку на процессор и сеть. Ключевой проблемой всех алгоритмов синхронизации данных в службе каталогов является отсутствие понятия транзакционности в базовом протоколе взаимодействия со службой каталогов и отсутствие свободных стандартизированных реализаций транзакций через расширение протокола. С другой стороны, стандарт взаимодействия со службой каталогов не описывает принципов хранения информации в каталоге, и поэтому в серверах службы каталогов часто реализован модульный подход к системе хранения информации. В частности, реализация сервера может содержать различные модули хранения информации, предоставляемой службой каталогов. В модулях реализовано хранение информации как в локальных файлах, так, например, и в зонах службы имен, в других серверах службы каталогов (используется для объединения нескольких каталогов в один или для кэширования запросов), а также в реляционной СУБД. Последний модуль совместно с имеющимися в современных СУБД алгоритмах репликации может быть эффективно использован для создания отказоустойчивого кластера службы каталогов. Использование этого модуля позволит избежать существенного падения производительности при большом количестве объектов, хранимых в службе каталогов. Помимо этого, часть информации, хранимой в реляционной базе данных, может не экспортироваться в службу каталогов, что приведет к уменьшению времени, необходимого на пересылку ответа (так количество полей в каждом объекте можно уменьшить до минимально необходимого), и позволит более точно управлять правами доступа к информации. Список литературы 1. Howard L. An approach for Using LDAP as a Network Information Service. RFC 2307, March 1998. 2. Vixie P., Thomson S., Rekhter Y., Bound J. Dynamic Updates in The Domain Name System. Network Working Group RFC-2136, 1997. 3. Gallmeister B. Posix 4: Programming for the Real World. O'Relly, 1995, pp. 217-230. 4. Rhodes D., Butler D. Solaris Operating Environment Bootcamp. Prentice Hall 2002, pp. 277-313. 5. Merrels J., Reed E., Srinivasan U. LDAP Replication Architecture. Network Working Group Draft, March 2000. |
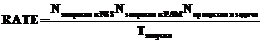 , где Tзапуска – разница между временем запуска задачи через систему очередей и временем окончания инициализации подсистемы передачи сообщений в параллельной программе (для оценки можно использовать время возврата из функции MPI_Init); Nзапросов к NSS – количество запросов к службе каталогов через программный интерфейс NSS; Nзапросов к PAM – количество запросов авторизации на исполняемый в операционной системе процесс, проходящих через программный интерфейс PAM; Nпроцессов в задаче – количество вычислительных процессов (используемых ядер) параллельной задачи.
, где Tзапуска – разница между временем запуска задачи через систему очередей и временем окончания инициализации подсистемы передачи сообщений в параллельной программе (для оценки можно использовать время возврата из функции MPI_Init); Nзапросов к NSS – количество запросов к службе каталогов через программный интерфейс NSS; Nзапросов к PAM – количество запросов авторизации на исполняемый в операционной системе процесс, проходящих через программный интерфейс PAM; Nпроцессов в задаче – количество вычислительных процессов (используемых ядер) параллельной задачи.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=729 |
Версия для печати Выпуск в формате PDF (1.83Мб) |
| Статья опубликована в выпуске журнала № 2 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Информатика – инфраструктура информационного общества
- Анализ отечественного опыта и структуризация механизмов управления оборонным научно-промышленным комплексом
- Разработка загрузчика программного обеспечения встроенной системы управления
- Календарные расчеты на калькуляторе
- Диалоговая система поддержки моделей функционирования
Назад, к списку статей