Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Автоматическая локализация ошибок времени выполнения в программном обеспечении с помощью нейронных сетей
Аннотация:Разработан метод автоматической локализации ошибок времени выполнения с помощью нейронной сети по данным трассировки осуществления функций программы. Метод сопоставляет каждой функции вероятность содержания ошибки, которая считается пропорциональной степени влияния значений параметров функции на результат выполнения программы. Влияние параметров определяется численной характеристикой (весом), вычисляемой по алгоритму Хашема. Метод применялся для отладки нескольких программ, различных по типам и причинам возникновения ошибок времени выполнения. Ошибки были расположены во вложенных функциях и проявлялись при определенных значениях входных данных. В каждой программе проведено сопоставление наиболее вероятных мест возникновения ошибок, которые определил метод, с их реальными местоположениями. Особенностями разработанного метода являются возможность работы с вложенными функциями, локализация множественных ошибок, а также ошибок, у которых место возникновения и место проявления в программе не совпадают. Во всех случаях параметры, содержащие ошибку, имели больший вес в сравнении с остальными, даже если ошибок в программе было несколько. При этом метод выделяет в программе полный путь ошибки, включающий в себя все параметры, связанные с ее возникновением. Благодаря этому с помощью предложенного метода можно определять положение логических ошибок в программах. Метод может применяться для отладки как программного, так и аппаратного обеспечения технических систем, поскольку логика его работы не зависит от источника исходных данных.
Abstract:A new automatic runtime error localization method using a neural network was developed. The method determines bug position by program functions tracing data. The method matches an error containing probability for each function. This probability is proportional to the effect of each function parameter on a program execution result. A numerical characteristic calculated by Hashem algorithm determines a parameter effect. The method was applied for debugging several programs with nested functions. The most probable bug locations defined by the method were compared with their real positions. The developed method has some features. It is able to localize multiple bugs, nested function bugs, and bugs with unequal manifestation and location places. In all cases, bugged parameters had more weight in comparison with rest parameters. At the same time, method determines a full error trace for each bug. The trace consists of all program parameters related to a bug. Therefore, the method is able to localize logical errors in program. The method can be used for debugging both technical system software and hardware since method logic does not depend on source data.
| Авторы: Достовалова А.М. (dost.bmstu99@gmail.com) - Концерн «Моринсис-Агат», Федеральный исследовательский центр «Информатика и управление» РАН (техник-программист, инженер-исследователь), Москва, Россия, Шерминская А.А. (SherminskayaAA@yandex.ru) - Концерн «Моринсис-Агат» (начальник сектора), Москва, Россия | |
| Ключевые слова: трассировка, нейронные сети, отладка ПО, ошибки времени выполнения, автоматическая локализация ошибок |
|
| Keywords: tracing, neural network, program debugging, runtime error, automatic bug localization |
|
| Количество просмотров: 1161 |
Статья в формате PDF |
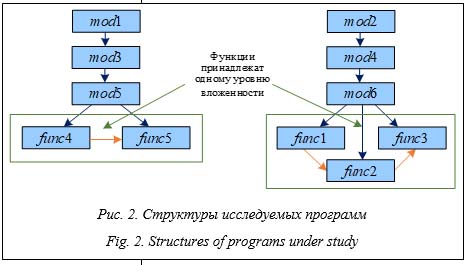
Требования к функциональности современного программного и аппаратного обеспечения сложных технических систем с каждым годом ужесточаются. Это приводит к увеличению числа входящих в них устройств и программ. Усложнение системы ведет к увеличению возможного количества появляющихся в ней неис- правностей, комплексная отладка такой системы становится более трудоемкой. Возникает не- обходимость автоматизации процесса поиска неисправностей, особенно ошибок времени выполнения, определение положения которых наиболее сложно. Для ПО существуют методы автоматической локализации ошибок времени выполнения [1]. Эти методы можно разделить на две группы: параметрические и непараметрические. Первые (например, методы срезки и их модификации [1]) для локализации ошибок используют значения программных переменных. Непараметрические методы, к которым относятся спектральные, статистические и некоторые методы машинного обучения, определяют положение ошибки в коде по данным трассировки (трассам) программы – численным данным о результатах работы отслеживаемых участков кода (функций, инструкций), полученным во время выполнения программы, и по результатам выполнения программы (выполнилась она до конца или завершилась с ошибкой) [2]. При этом в непараметрических методах используются только данные об успешном или неудачном завершении выполнения участков программы. Непараметрические методы обычно более производительные по сравнению с параметрическими, поскольку программист может сам назначить подозрительные на наличие ошибки участки кода, в том числе проводя поиск ошиб- ки в несколько этапов, каждый раз измельчая исследуемые блоки. Но эти методы пригодны для ограниченного круга задач – для программ, в которых нет участков вложенных функций и местоположение ошибки времени выполнения совпадает с местом ее проявления (характерно для спектральных и статистических методов). Непараметрическими методами невозможно локализовать ошибки, проявляющиеся лишь при определенных значениях входных параметров, особенно если программа завершает свое выполнение в момент ее возникновения. Кроме того, при трассировке алгоритм судит о наличии ошибки в функции по тому, соответствуют ли ее выходные параметры заданному диапазону. Такая информация сильно подвержена искажениям, поскольку при определении границ диапазона уже может быть допущена ошибка. Основным затруднением в процессе поиска неисправностей как в ПО, так и в технической системе в целом, является сопоставление большого числа разнородных параметров, неявно связанных между собой. Для выявления подобных закономерностей перспективным представляется использование нейронных сетей. Преимуществом этого подхода является универсальность: нейронная сеть способна искать закономерности в данных независимо от их природы, то есть в общем случае в состав исследуемой системы могут входить как программные, так и аппаратные средства. Была поставлена задача разработать метод автоматической локализации ошибок времени выполнения с помощью нейросети в программах по данным трассировки выполнения функций. Каждой функции метод должен сопоставлять вероятность содержания ошибки, которая считается пропорциональной степени влияния значений параметров функции на результат работы программы. Численная характеристика влияния параметра вычисляется с помощью алгоритма Хашема [3]. Новизна разработанного метода заключается в возможности работы с вложенными функциями и в локализации множественных ошибок, а также ошибок, у которых место возникновения и место проявления в программе не совпадают. Предложенный метод тестировался на наборе программ с заложенными в коде ошибками времени выполнения, находящимися внутри последовательности вложенных функций. Предполагаемые места возникновения ошибок сравнивались с их реальным местоположением. Подходы к автоматизации процесса поиска неисправностей в ПО Задача автоматизации поиска неисправностей в ПО имеет долгую историю. Одной из первых работ по данной тематике является [4], в которой описан метод статической срезки. В нем положение некорректных инструкций в программе определяется среди набора выделенных срезов – строк кода, содержащих переменные, связанные с появлением ошибки. В последние годы методы срезки использовались в гибридных подходах в связке с альтернатив- ными методами автоматической локализации ошибок в программном коде [5, 6]. Кроме методов срезки, существует множество других подходов к локализации ошибок [1, 7]. Среди них можно выделить два активно развивающихся направления – спектральные методы и методы машинного обучения. В спектральных методах программа разбивается на участки, подозрительные на наличие в них ошибок. При отладке для каждого участка отслеживаются правильность его работы и степень покрытия тестами и вычисляется его подозрительность – численное значение, характеризующее вероятность наличия ошибки [1]. Формула для вычисления подозрительности с течением времени претерпела изменения [1], в нее были добавлены вероятностные элементы [8, 9]. Созданы модификации спектральных методов, повышающие для больших программ точность определения участков с ошибкой [10, 11]. Методы машинного обучения для автоматической локализации ошибок разделяются на методы, направленные только на определение положения ошибки, и методы, и локализующие, и исправляющие найденную ошибку. Методы первой группы близки по идее к спектральным. С помощью полносвязной нейронной сети определяются взаимосвязи между покрытием тестами отслеживаемых участков кода и соответствующими им значениями подозрительности [12]. Методы второй группы рассматривают задачу поиска и исправления ошибки как задачу машинного перевода [13]. Такая постановка позволяет использовать архитектуры LLM, например, инструмент ChatGPT [14]. В работе [15] также был продемонстрирован потенциал языковых моделей к исправлению ошибок времени выполнения при дополнении набора для обучения сети данными трассировки программы. Перечисленные подходы различны, но обладают общей чертой – каждый метод накладывает ограничения на обрабатываемые данные. Методы срезки требуют, чтобы в исследуемом участке кода присутствовала только одна ошибка. Спектральные методы не используют данные о значениях программных переменных, из-за чего их способность к локализации ошибок, проявляющихся только при определенных значениях входных данных, ограничена. Кроме того, оценка правильности прохождения участков трасс требует создания критериев оценива- ния, при разработке которых также могут возникнуть ошибки. Соответственно, исходные данные для спектрального метода могут быть недостоверными. Использование большинства языковых моделей для исправления ошибок времени выполнения ограничено случаями, когда ошибки не являются логическими и не проявляются только при определенных значениях входных данных. Добавление к обучающему набору данных трассировки программы расширяет возможности языковых моделей. Однако в работе [15] задача разметки подозрительных участков трасс перед обучением решена не была – разметка проводилась вручную. Кроме того, при отладке программно-аппаратных комплексов часто возникает ситуа- ция, когда исходного кода у программиста нет. Часть функционала может быть доступна толь- ко в формате библиотек с известным интерфейсом, но неизвестной реализацией. В таких библиотеках могут существовать ошибки, проявляющиеся только при их функционировании как части системы, но не отдельного блока. Предложенный в данной работе метод не сталкивается с вышеперечисленными ограничениями. Для локализации ошибок он использует только данные трассировки программы, к которым легко получить доступ при отладке программно-аппаратных комплексов и программ, даже если исходный код последних не известен. Метод использует непосредственно значения переменных, отслеживаемых при отладке программы, поскольку эти данные не искажены дополнительными проверками правильности. Кроме того, применение метода не ограничено случаями, когда в программе присутствует только одна ошибка. Общее описание метода локализации ошибок времени выполнения Представляемый метод локализует ошибки времени выполнения в программе, состоящей из набора функций Если в программе среди fi нет вложенных функций, ее можно однозначно представить в виде одной функции Однако связи между значениями После того как сеть обучена, необходимо определить для каждого входного параметра нейросети степень его влияния на выходное значение метки wi – результат выполнения трассы. Для этого каждому параметру ставится в соответствие численная характеристика – вес параметра, вычисляемый по алгоритму Хаше- ма [3] усреднением по обучающему набору значений градиента Обработка участков вложенных функций Описание метода было сделано только для работы с программами, которые не содержат вложенных функций. Если в программе встречаются вложенные участки (что характерно для многих реальных задач), метод не сможет локализовать в ней ошибку из-за неспособности сформировать полный вектор параметров Чтобы преодолеть ограничение на наличие вложенности в обрабатываемых программах, представляемый метод дополняют еще одним шагом, предшествующим шагу составления вектора параметров f1 É ( f2 É ( f3 ® f4)), (1) где É – вызов из левой функции вложенного правого участка; ® – последовательные вызовы функций. Функции f3, f4 принадлежат нижнему уров- ню вложенности и выполняются на нем последовательно друг за другом. Развернутая трасса этой последовательности имеет вид f1_ f2 ® f2_ f3® f3 ® f4 ® f4_ f2 ® f2_ f1, (2) где функции f1_ f2 и f2_ f3 – части функций f1, f2 до вхождения во вложенный участок; f4_ f2 и f2_ f1 – части f1, f2 после выхода из вложенности (участки между несколькими последовательными уровнями вложенности внутри fi обозначаются fi_ fj_ fk). Различия между схемами вызовов исходной и развернутой трасс представлены на рисунке 1.
Определение параметров с наибольшим влиянием на результат выполнения программы Для установления зависимости между значениями параметров
Для оценки приоритета входных параметров нейросети полученные значения градиента в точках данных усредняются по всему обучающему набору. Для каждого входа Ii нейронной сети вычисляется вес зависимости Dik между ним и каждым выходным узлом Ok (Ndata – число элементов в обучающем наборе) по формуле
Эти значения нормируются и объединяются в матрицу весов DM (NI – число узлов входного слоя, No – число узлов выходного слоя), для вычисления которой используется формула
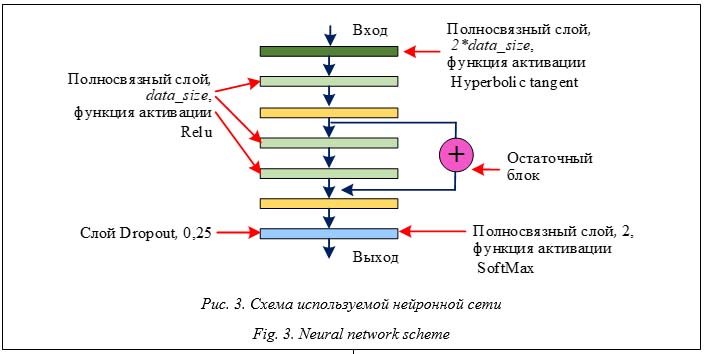
Достоинство алгоритма Хашема в сравнениии с альтернативными методами определения приоритета входных данных [3] в том, что он может работать с глубокими нейросе- тями, которые обычно приближают одну и ту же функцию более эффективно, чем неглубокие, даже если общее число нейронов у них совпадает [17]. Вычисленные с помощью алгоритма Хашема значения весов используют в предложенном методе локализации ошибок времени выполнения, чтобы ранжировать функции, составляющие программу, по вероятности содержания ошибки. Она тем выше, чем больше вес соответствующих функций параметров. Экспериментальная отработка метода Были исследованы пять тестовых программ. При трассировке отслеживались значения входных и выходных параметров функций. Завершение программы с ошибкой происходило, если значение хотя бы одного из параметров выполняемой функции выходило за пределы установленного для него диапазона.
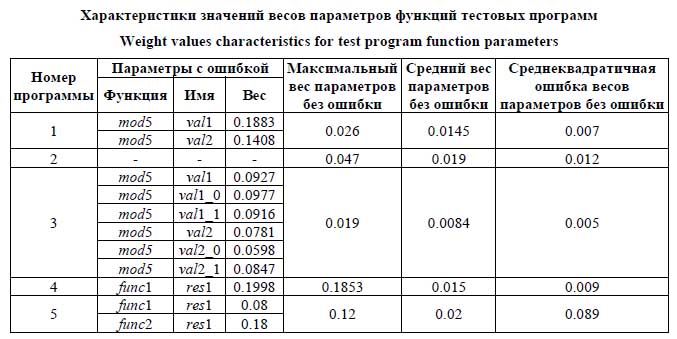
В Программе 1 на вход mod1 подавался вектор длиной 10, состоящий из случайным образом сгенерированных чисел заданного диапазона. В этой функции создавался второй вектор, полученный из элементов первого умножением их значений на 2. В mod3 значения двух векторов еще раз умножались на 2, после чего генерировались два числа – val1 и val2. Первое принимало значения от 0 до 10, второе – 0 или 1. Оба вектора и два числа передавались в mod5. Далее в func4 вычислялся максимум из элементов векторов. В func5 происходила проверка значений val1 и val2: если второе число равнялось 1, а первое принимало любое значение, кроме 5 или 9, считалось, что программа завершилась с ошибкой. Программа 1 моделировала случай распределенной ошибки, проявляющейся при определенной комбинации значений параметров функций. Программа 2 повторяла Программу 1, за исключением того, что в векторе входных па- раметров не было значений val1 и val2. Программа 2 моделировала случай, когда ошибка не зависела от параметров, составляющих вектор параметров Программа 3 тоже повторяла Программу 1, но в векторе параметров val1 и val2 повторялись три раза (названия переменных при этом были разными). Программа 3 моделировала случай, когда в векторе содержащие ошибку параметры повторялись несколько раз. В Программе 4 на вход mod2 подавался вектор длины 10, состоящий из заданных чисел (от 10 до 20). В этой функции создавался второй вектор, полученный из элементов первого умножением их значений на 2. В mod4 для элементов векторов вычислялись сумма значений summVals и максимум maxVals. Полученные значения передавались на вход func1, в которой вычислялся res1 = summVals + maxVals c1 и res2 = res1c2, c2 = 0; 1, res1 и res2 подавались на вход func2, в которой эти числа умножались на 1. В func3 программа завершалась ошибкой, если параметр res2 функции func2, передающийся ей на вход как параметр inp1, был отрицательным: ошибка была заложена в функции func1. Программа 5 повторяла Программу 4 до момента выполнения функции func2. В Программе 5 func2 повторяла func1, за исключением условия, по которому с2 принимала отрицательное значение; func2 принимала на вход maxVals и summVals и возвращала значения res1 и res2; func3 принимала на вход значения и от func1, и от func2. Программа завершалась в этой функции с ошибкой при условии, что или res2 функции func1, или res2 функции func3 отрицательно. Программа 5 моделировала случай, когда в ней присутствовало несколько ошибок. Программы 2 и 3 позволяли оценить влияние ошибок при составлении вектора параметров на результат обработки данных трассировки. В Программах 4 и 5, в отличие от Программ 1–3, ошибки проявлялись неявно: в вектор параметров входили только значения, на которые влияли параметры с ошибкой. Сами эти параметры в векторе Результаты локализации ошибок в исследуемых функциях
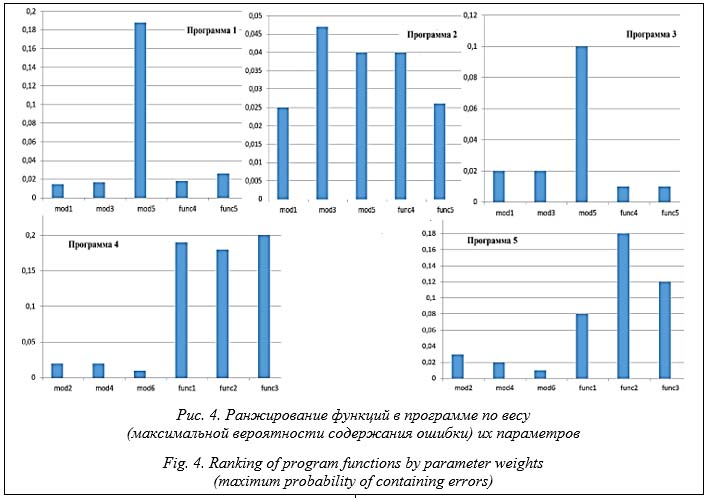
На рисунке 4 каждой функции присвоен номер, определяющийся в соответствии с высо- той столбца функции на графике. Столбцы наибольшей высоты соответствуют функциям, параметры которых обладают наибольшим весом. В четырех из пяти случаев, для Программ 1, 3, 4 и 5, удалось выделить функции, содержащие ошибки. Параметры с ошибкой выделялись в общем множестве значений как пиковые значения: их веса были больше средних значений весов параметров без ошибки в 3–10 раз. У параметров без ошибки разброс значений весов относительно среднего, характеризующийся величиной среднеквадратичной ошибки, невелик. Среди рассмотренных программ выделяется случай Программы 2, когда в векторе Интерес представляет случай Программы 4. В ней, кроме содержащей ошибку функции func1, выделяются еще функции func2 и func3, потому что у параметров res1 и вычисленных с его помощью res1 из func2 и у inp1 из func3 близкие значения весов. Метод может выделять лишние параметры, кроме тех, что действительно содержат ошибку. Однако все вы- деленные параметры оказываются связанными с возникновением ошибки: это параметры, значения которых являются условием появления ошибки, параметры, которым присваивается значение с ошибкой, и т.д. Для каждой ошибки можно проследить ее полный путь в программе – в данном случае от func1 до func3. В случае Программы 4 полный путь ошибки избыточен для определения ее местонахождения. Однако если допущенная ошибка является логической (например, условие, по которому она возникает, не должно выполняться вообще), исследование полного пути является единственным способом определения ее реального положения.
Заключение В результате исследования разработан метод автоматической локализации ошибки времени выполнения с использованием нейронных сетей в программах по данным трассировки выполнения функций. Предложенный метод производителен, как и непараметрические ме- тоды автоматической локализации ошибки времени выполнения, но при этом лишен их главного недостатка: с каждой функцией в трассе связаны неискаженные данные, по значениям которых производится локализация ошибки. Метод применен для обработки данных трассировки пяти тестовых программ, различных по числу и природе возникающих в них ошибок времени выполнения. С его помощью удалось определить параметры, связанные с возникновением ошибки, когда они присутствовали в векторе параметров, подающемся на вход нейросети. Метод способен выделять ошибки в программах с вложенными функциями, в том числе и когда их несколько, а также определять положение ошибок, возникающих только при определенных значениях параметров функций. Он имеет потенциал в качестве средства определения положения логических ошибок в коде. Метод можно применить для отладки как аппаратного обеспечения, так и ПО сложных технических систем, поскольку для него не важна природа исследуемых данных. Список литературы 1. Wong W.E., Gao R., Li Y., Abreu R., Wotawa F. A survey on software fault localization. IEEE Transactions on Software Eng., 2016, vol. 42, no. 8, pp. 707–740. doi: 10.1109/TSE.2016.2521368. 2. Kraft J., Wall A., Kienle H. Trace recording for embedded systems: Lessons learned from five industrial projects. Proc. RV. LNPSE, 2010, vol. 6418, pp. 315–329. doi: 10.1007/978-3-642-16612-9_24. 3. Комаров Я.Б., Шерминская А.А., Николаев А.А. Методы определения приоритета входных параметров функционально-математических библиотек с закрытым исходным кодом // Тр. КГНЦ. 2021. Спец. № 2. C. 91–96. 4. Weiser M. Program slicing. IEEE Trans. Soft. Eng., 1984, vol. SE-10, no. 4, pp. 352–357. doi: 10.1109/TSE.1984.5010248. 5. Reis S., Abreu R., d’Amorim M. Demystifying the combination of dynamic slicing and spectrum-based fault localization. Proc. IJCAI, 2019, pp. 4760–4766. 6. Soremekun E., Kirschner L., Böhme M., Zeller A. Locating faults with program slicing: An empirical analysis. Empirical Software Engineering, 2021, vol. 26, no. 3, art. 51. doi: 10.1007/s10664-020-09931-7. 7. Zakari A., Lee S.P., Alam K.A., Ahmad R. Software fault localisation: A systematic mapping study. IET Software, 2019, vol. 13, no. 1, pp. 60–74. doi: 10.1049/iet-sen.2018.5137. 8. Yang Y., Deng F., Yan Y., Gao F. A fault localization method based on conditional probability. Proc. IEEE 19th Int. Conf. on QRS-C, 2019, pp. 213–218. doi: 10.1109/QRS-C.2019.00050. 9. Landsberg D., Barr Earl T. Doric: Foundations for statistical fault localization. ArXiv, 2018, art. 1810.00798. URL: https://arxiv.org/abs/1810.00798 (дата обращения: 13.07.2023). 10. Keller F., Grunske L., Simon H., Filieri A., van Hoorn A., Lo D. A critical evaluation of spectrum-based fault localization techniques on a large-scale software system. Proc. IEEE Int. Conf. QRS, 2017, pp. 114–125. doi: 10.1109/ 11. Kong L., Wang J., Zhou S., Wang M. A multiple-fault localization method for embedded software with applications in engineering. Math. Problems in Engineering, 2021, vol. 2021, pp. 1–17, art. 7038979. doi: 10.1155/2021/7038979. 12. Heris S.R., Keyvanpour M. Effectiveness of weighted neural network on accuracy of software fault localization. Proc. ICWR, 2019, pp. 100–104. doi: 10.1109/ICWR.2019.8765262. 13. Chalambous Y., Tihanyi N., Jain R., Sun Y. et.al. A new era in software security: Towards self-healing software via large language models and formal verification. ArXiv, 2023, art. 2305.14752. URL: https://arxiv.org/abs/2305.14752 (дата обращения: 13.07.2023). 14. Haque M.A., Li S. The potential use of ChatGPT for debugging and bug fixing. EAI Endorsed Trans AI Robotics, 2023, vol. 2. doi: 10.4108/airo.v2i1.3276. 15. Bouzenia I., Ding Y., Pei K., Ray B., Pradel M. TraceFixer: Execution trace-guided program repair. ArXiv, 2023, art. 2304.12743. URL: https://arxiv.org/abs/2304.12743 (дата обращения: 13.07.2023). 16. Hecht-Nielsen R. Kolmogorov’s mapping neural network existence theorem. Proc. IEEE Int. Conf. on Neural Networks, 1987, vol. 3, pp. 11–14. 17. Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. СПб: Питер, 2018. 480 с. References
1. Wong, W.E., Gao, R., Li, Y., Abreu, R., Wotawa, F. (2016) ‘A survey on software fault localization’, IEEE Transactions on Software Eng., 42(8), pp. 707–740. doi: 10.1109/TSE.2016.2521368. 2. Kraft, J., Wall, A., Kienle, H. (2010) ‘Trace recording for embedded systems: Lessons learned from five industrial projects’, Proc. RV. LNPSE, 6418, pp. 315–329. doi: 10.1007/978-3-642-16612-9_24. 3. Komarov, Ya.B., Sherminskay, A.A., Nikolaev, A.A. (2021) ‘Methods for determining the priority of input parameters of functional-mathematical libraries with a closed source code’, Transactions of KSRC, (spec. 2), pp. 91–96 (in Russ.). 4. Weiser, M. (1984) ‘Program slicing’, IEEE Trans. Soft. Eng., SE-10(4), pp. 352–357. doi: 10.1109/TSE.1984.5010248. 5. Reis, S., Abreu, R., d’Amorim, M. (2019) ‘Demystifying the combination of dynamic slicing and spectrum-based fault localization’, Proc. IJCAI, pp. 4760–4766. 6. Soremekun, E., Kirschner, L., Böhme, M., Zeller, A. (2021) ‘Locating faults with program slicing: An empirical analysis’, Empirical Software Engineering, 26(3), art. 51. doi: 10.1007/s10664-020-09931-7. 7. Zakari, A., Lee, S.P., Alam, K.A., Ahmad, R. (2019) ‘Software fault localisation: A systematic mapping study’, IET Software, 13(1), pp. 60–74. doi: 10.1049/iet-sen.2018.5137. 8. Yang, Y., Deng, F., Yan, Y., Gao, F. (2019) ‘A fault localization method based on conditional probability’, Proc. IEEE 19th Int. Conf. on QRS-C, pp. 213–218. doi: 10.1109/QRS-C.2019.00050. 9. Landsberg, D., Barr E.T. (2018) ‘Doric: Foundations for statistical fault localization’, ArXiv, art. 1810.00798, available at: https://arxiv.org/abs/1810.00798 (accessed July, 2023). 10. Keller, F., Grunske, L., Simon, H., Filieri, A., van Hoorn, A., Lo, D. (2017) ‘A critical evaluation of spectrum-based fault localization techniques on a large-scale software system’, Proc. IEEE Int. Conf. QRS, pp. 114–125. 11. Kong, L., Wang, J., Zhou, S., Wang, M. (2021) ‘A multiple-fault localization method for embedded software with applications in engineering’, Math. Problems in Engineering, 2021, pp. 1–17, art. 7038979. doi: 10.1155/2021/7038979. 12. Heris, S.R., Keyvanpour, M. (2019) ‘Effectiveness of weighted neural network on accuracy of software fault localization’, Proc. ICWR, pp. 100–104. doi: 10.1109/ICWR.2019.8765262. 13. Chalambous, Y., Tihanyi, N., Jain, R., Sun, Y. et.al (2023) ‘A new era in software security: Towards self-healing software via large language models and formal verification’, ArXiv, art. 2305.14752, available at: https://arxiv. 14. Haque, M.A., Li, S. (2023) ‘The potential use of ChatGPT for debugging and bug fixing’, EAI Endorsed Trans AI Robotics, 2. doi: 10.4108/airo.v2i1.3276. 15. Bouzenia, I., Ding, Y., Pei, K., Ray, B., Pradel, M. (2023) ‘TraceFixer: Execution trace-guided program repair’, ArXiv, art. 2304.12743, available at: https://arxiv.org/abs/2304.12743 (accessed July, 2023). 16. Hecht-Nielsen, R. (1987) ‘Kolmogorov’s mapping neural network existence theorem’, Proc. IEEE Int. Conf. on Neural Networks, 3, pp. 11–14. 17. Nikolenko, S., Kadurin, A., Arkhangelskaya, E. (2018) Deep Learning. St. Petersburg, 480 p. (in Russ.). |

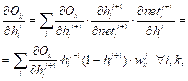 (4)
(4)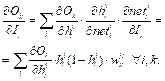 (5)
(5)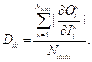 (6)
(6)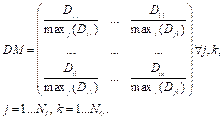 (7)
(7)
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=5033&lang=&lang=&like=1 |
Версия для печати |
| Статья опубликована в выпуске журнала № 4 за 2023 год. [ на стр. 551-560 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка и программная реализация гибридного алгоритма решения оптимизационных задач автоматизированного проектирования
- Многофункциональный имитатор нейронных сетей
- Комплекс программного обеспечения для оптимизации надежности однородных нейронных структур
- Применение модели нейронных сетей для поддержки принятия решения абитуриента по выбору специальности
- Двухслойный векторный персептрон для решения задачи распознавания бинарных образов
Назад, к списку статей