Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Сложность распознавания при разработке программного обеспечения для видеомониторинга
Аннотация:В работе рассмотрена проблема выбора оптимального режима видеомониторинга при использовании моделей нейронных сетей в качестве распознавателя, когда на видеопотоке в разные моменты времени эффективнее оказываются разные модели. Задачи видеомониторинга различные, при этом условия получения данных отличаются, что можно выразить в понятии сложности распознавания. Оценка сложности распознавания в мониторинге позволяет сэкономить вычислительные ресурсы и тем самым удешевить их внедрение и использование. Оценив среднюю сложность распознавания, можно выбрать оптимальный по скорости и достоверности режим распознавания при постобработке, когда время на нее ограничено. Решение проблемы показано на задаче детектирования объектов двух типов с использованием моделей YOLOv5, когда видеопоток должен обрабатываться в реальном времени с минимальной задержкой при выдаче результата после каждого кадра. Проанализированы метрики, используемые при детектировании объектов, на предмет возможности оценки достоверности результатов, когда нет конечных сведений о том, что это за объект. Выбран критерий эффективности на основе суммы компонент F1-score и затрат на вычислительные ресурсы, позволяющий оценить эффективность модели для конкретных объектов. Показана зависимость критерия эффективности от F1-score для двух моделей. При-ведены результаты тестирования двух моделей и динамического режима, основанного на выборе подходящей модели в зависимости от объекта на входе. Описаны ограничения подхода, который может быть использован только на потоковом распознавании, когда поступающие на распознавание изображения лишь немного отличаются от предыдущих. Сделан вывод о применимости подхода для ряда задач при соблюдении ограничений.
Abstract:The paper considers the problem of choosing an optimal video monitoring mode when using neural network models as a recognizer when different models are more effective on a video stream at different times. Video monitoring tasks are different while the conditions for obtaining data are different, which can be expressed in the recognition complexity concept. Evaluation of the recognition complexity in monitoring allows saving computing resources, thereby reducing the cost of implementation and use. After evaluating the average complexity of recognition, it is possible to choose the optimal recognition mode in terms of speed and relia-bility during post-processing, when time for it is limited. The paper shows the problem solution in the task of two type object detection using YOLOv5 models, when the video stream must be processed in real time with a minimum delay when the result is returned after each frame. The metrics used in the object detection are analyzed in terms of a possibility of assessing the reliability of the results when there is no final information about an object. There is a chosen efficiency crite-rion based on the sum of the F1-score and the cost of computing resources, which makes it possible to eval-uate the model effectiveness for specific objects. The paper shows the dependence of the efficiency criterion on the F1-score for two models. There are the results of testing two models and a dynamic mode based on choosing an appropriate model depending on the input object. The paper describes the limitations of the ap-proach, which can be used only for streaming recognition, when the images received for recognition are only slightly different from the previous ones. in the end, there is a conclusion about the approach applicability for a number of problems in accordance with the restrictions.
| Авторы: Кручинин А.Ю. (kruchinin-al@mail.ru) - Оренбургский государственный университет (доцент), Оренбург, Россия, кандидат технических наук | |
| Ключевые слова: видеомониторинг, сложность распознавания, детектирование объектов, f1-score, yolo |
|
| Keywords: video monitoring, recognition complexity, object detection, f1-score, yolo |
|
| Количество просмотров: 1154 |
Статья в формате PDF |
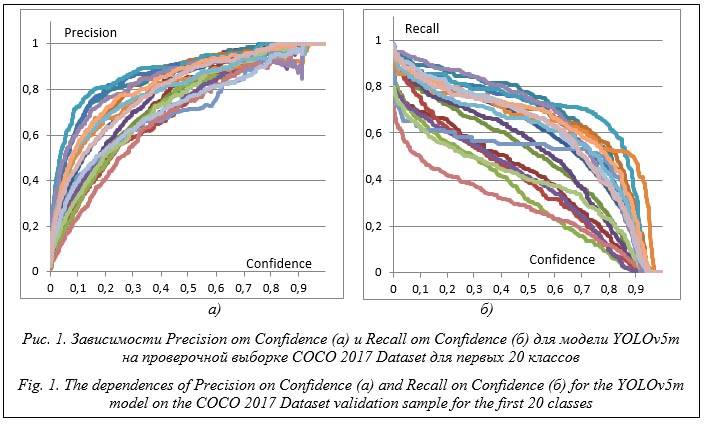
Видеомониторинг является активно развивающейся областью науки и находит широкое применение. Это класс мониторинга, в котором сбор данных осуществляется с помощью видеотехнологий (например, видеокамерами). Мониторинг состояния объекта осуществляется по одному или нескольким видеопотокам. К раз- рабатываемому ПО видеомониторинга предъ- являются требования по достоверности рас- познавания и производительности. Создание алгоритма/модели распознавания связано с исследованием данных, которое нужно осуществлять по формальным этапам, описанным, например, в межотраслевом стандарте интеллектуального анализа данных CRISP-DM. Задачи видеомониторинга бывают разные, при этом условия получения данных отличаются, что можно выразить в понятии сложности распознавания. Как показано в работе [1], сложность распознавания соответствует вероятности его ошибки. В самом простейшем случае существуют два класса образов и один признак, по которому осуществляется распознава- ние. Если вероятностные распределения этих образов пересекаются, то образуется область ошибочного распознавания. Чем больше эта область, тем выше сложность распознавания, и чем выше сложность распознавания, тем больше измерений нужно сделать, чтобы получить результат с требуемым уровнем достоверности, что показано в работе [2]. В этой же работе используется понятие единичной достоверности, которая является косвенно оцененной для конкретного распознавания. При этом сделан вывод о невозможности по единичной достоверности оценить статистическую достоверность результатов, что затрудняет оценку сложности распознавания в реальном времени. Таким образом, косвенные показатели оценки достоверности результата даже в простейшем случае двух образов с нормальным распределением не могут быть использованы для оценки текущей сложности распознавания, которая требует владения информацией (априорная и апостериорная вероятность) о присутствии тех или иных образов. Оценка сложности распознавания в мониторинге позволяет сэкономить вычислительные ресурсы и тем самым удешевить их внедрение и использование. Оценив среднюю сложность распознавания, можно выбрать оптимальный по скорости и достоверности режим распознавания при постобработке, когда время на нее ограничено. Если же мониторинг производится в реальном времени или с небольшой задержкой, то оценка сложности распознавания дает возможность оптимально использовать ресурсы системы мониторинга, позволяя динамически выбирать режим. Анализ изображений и видеоданных является намного более сложной задачей, чем работа с одномерными данными. Но при этом не менее важно оценивать сложность распознавания для выбора правильных режимов как ПО, так и системы видеомониторинга в целом. Самой простой задачей при распознавании изображений является их классификация. Она обусловлена необходимостью отнесения неизвестного изображения к определенной категории, например, кошка на изображении или собака. Однако в видеомониторинге подобная задача практически не решается, здесь выполняются детектирование и трекинг объектов. В данной работе предлагается применение подхода к управлению режимами ПО на основе оценки сложности текущего распознавания на примере детектирования объектов. В последнее десятилетие детектирование графических образов на изображениях перешло в разряд классических задач, решаемых глубокими нейронными сетями. В качестве примера можно привести фреймворк TensorFlow и его Object Detection API [3], хотя есть и множество других альтернатив. Основными показателями работы нейронной сети считаются скорость и достоверность, которые обычно сравниваются на наборе данных COCO. Другими важными параметрами являются размеры требуемой памяти GPU устройства и входного изображения. Структур нейронных сетей предостаточно: YOLO, SSD, R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN. В настоящее время одной из наиболее эффективных архитектур для детектирования объектов является YOLOv5. Совместно с задачей детектирования объектов решается задача трекинга – слежение за объектами в разных кадрах видео. И здесь тоже существует много методов: ROLO, Deep SORT, TrackR-CNN, Tracktor++, JDE. Есть большое направление исследований вопросов сегментации объектов и трекинга, обзор по которым представлен в работе [4]. Очевидным является факт, что в большин- стве случаев чем быстрее модель, тем она менее точна. Поэтому в системах реального времени, системах с оплатой за использование ресурса (удаленные онлайн-сервисы распознавания) и в случаях ограничения вычислительных ресурсов на первый план выходит выбор оптимальной модели для конкретной ситуации детектирования графических образов. Большинство научных исследований направлено на разработку методов, позволяющих ускорить получение результата при сохранении требуемого качества, например [5]. Но есть и исследования, посвященные снижению затрат вычислительных ресурсов путем адаптивной оптимизации в зависимости от наличия объектов в кадре [6]. А в работе [7] с той же целью предлагается заранее определить оптимальную частоту кадров. В [8, 9] представлены методы обработки видеопотока с понятием ключевого и неключевого кадров, где ключевые кадры распознаются сильной моделью, а неключевые – слабой. В [10] предлагается объединение объектов в близлежащих кадрах. Также есть множество исследований, в той или иной мере направленных на оптимизацию процесса распознавания. Между тем представленный подход, когда для выбора режима работы системы видеомониторинга используется оценка сложности распознавания, не распространен. Для упрощения введем следующие ограничения задачи: - видеопотоки, обрабатываемые системой видеомониторинга, независимы; - каждый видеопоток должен обрабатываться в реальном времени с минимальной задержкой при выдаче результата после каждого кадра; - система видеомониторинга использует две модели для распознавания – быструю и медленную; медленная модель гарантирует более достоверный результат; - задача распознавания сводится к детектированию двух классов образов, один из которых с достаточным качеством распознается быстрой моделью, а другой – медленной; - данные в видеопотоке структурированы таким образом, что изображения поступают друг за другом и изменения плавные, то есть появившийся в кадре объект, скорее всего, будет и в следующем кадре; - не используются другие методы, улучшающие классификацию, например, детектирование движения, улучшение видео за счет объединения кадров, трекинг и др. Под такие условия попадает задача детектирования на изображениях грузового транспорта и автобусов с использованием двух моделей YOLOv5: YOLOv5s и YOLOv5m. Все метрики в задаче детектирования базируются на информации о результатах: истинно положительных (TP), ложно положительных (FP), истинно негативных (TN) и ложно негативных (FN). Простейшими метриками являются Precision и Recall: Precision = TP/(TP + + FP), Recall = TP/(TP + FN), где Precision – мера ложных срабатываний, Recall – мера пропусков.
Зависимости имеют явный тренд для каждого класса (при нескольких исключениях). Это позволяет сгладить график для классов и построить таблицу данных Precision от Confidence, используя ее в качестве меры вероятности того, что распознанный образ с некоторым значением Confidence является истинно распознанным. Несколько иное значение имеет Re- call (рис. 1б). Для графиков Recall от Confi- dence значения Recall используются при поро- говом значении Confidence. В задачах детектирования устанавливается некоторое пороговое значение Confidence, ниже которого результаты отбрасываются, например 0.3. Этот показатель характеризует степень вероятности того, что данный класс не будет распознан. Однако его использование для оценки достоверности распознавания в чистом виде весьма затруднительно, поскольку без данных об апостериорной и априорной вероятности появления того или иного класса образа на изображении применять его нельзя. Таким образом, для задачи детектирования объектов на изображениях нельзя найти точную меру оценки достоверности результатов, но можно определить, какой из объектов сложнее распознавать, по экспериментальным значениям вероятности ошибки или соответствующей метрикой, например F1-score: F1 = = 2 (Precision * Recall)/(Precision + Recall).
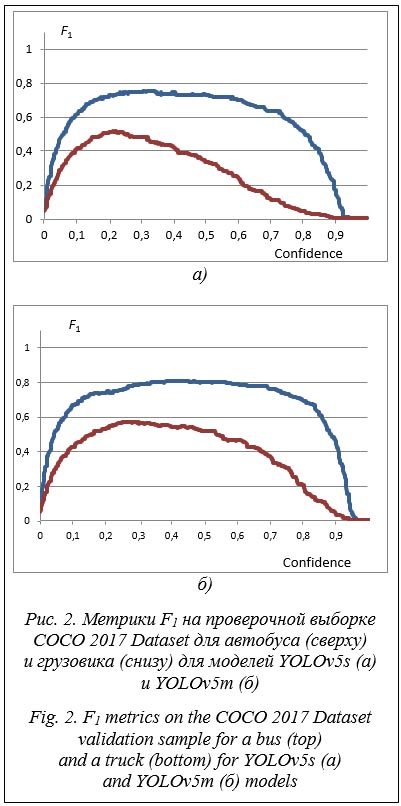
Из рисунка 2а видно, что для грузовика метрика F1 имеет более плохие показатели, чем для автобуса, поэтому использование модели YOLOv5s для грузовиков не подходит и надо использовать более массивные модели, например YOLOv5m (рис. 2б). Однако и в этом случае показатель F1 для автобусов невелик. Возникает вопрос, каким может быть критерий, который позволял бы динамически выбирать модель, зная конкретные объекты, находящиеся в кадре. Для этого предлагается использовать следующий критерий эффективности модели: E = F1 + k/P, где P – затрачиваемые моделью вычислительные ресурсы (например, время распознавания на данной вычислительной системе); F1 – среднее значение показателя F1-score для найденных в кадре объектов; k – коэффициент значимости для эффективности параметра производительности.
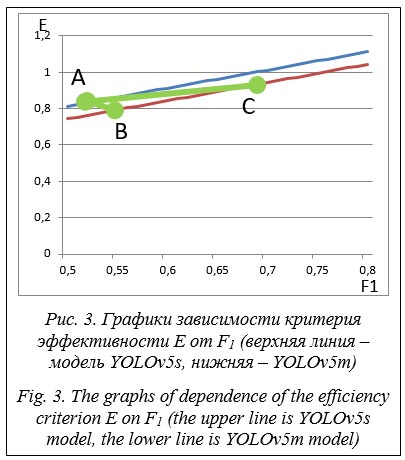
Разница между графиками определяется коэффициентом k. Количественные показатели критерия имеют значения только в относительной величине. При этом модель, находящаяся ниже, необязательно менее эффективна, так как при распознавании она будет давать более высокие значения F1 и, соответственно, критерий будет выше. Это можно видеть по точкам A, B и C. Если распознавание моделью YOLOv5s дает результаты в точке A, то распознавание моделью YOLOv5m может дать другой результат по величине F1, например, в точке B или C. Если в точке B, то модель YOLOv5m менее эффективна, а если в C, то более эффективна. На примере COCO 2017 Dataset проследим, как меняется критерий эффективности для обеих моделей. Для начала посмотрим, как меняется значение F1. При этом для каждой из моделей зафиксируем порог на уровне максимального значения F1. Всего в COCO 2017 Dataset 393 проверочных изображения, где встречается автобус или грузовой автомобиль. Если посчитать среднее F1 по этим моделям, то наилучшие показатели у YOLOv5m (см. таблицу). Если исключить из тестовой выборки плохие картинки (так как они почти не видны за другими объектами), оставив 288, то результаты еще более показательны. При этом производительность лучше у модели YOLOv5s. Результаты тестирования отдельных моделей и динамического выбора режима Test results for individual models and dynamic mode selection
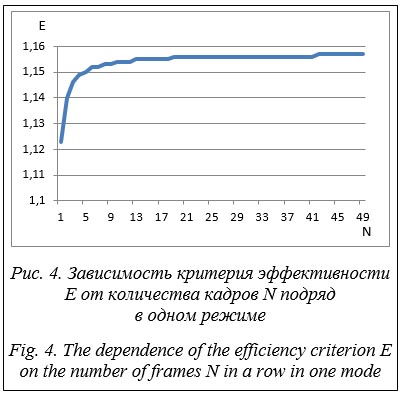
Максимальное значение критерия эффективности в обоих случая ограничено F1 = 1 и значением критерия k, управляя которым, можно определять, что важнее – достоверность распознавания или быстродействие. В правом столбце приведены данные для динамического режима, в котором все изображения с грузовиком распознавались моделью YOLOv5m, а остальные YOLOv5s. Тестирование показало, что критерий эффективности лучше при динамическом выборе.
Заключение Проведенные исследования позволяют сделать вывод о том, что динамический выбор модели на основании оценки сложности может быть эффективным в ряде задач. Это нужно учитывать при разработке соответствующего ПО. Однако есть ограничения и на динамический выбор модели: - подход может быть использован только на потоковом распознавании, когда поступающие на распознавание изображения лишь немного отличаются от предыдущих; в этом случае при отсутствии класса грузовика в нескольких кадрах используется модель small; - частота изменения сложности распознавания, которая определяется классом грузовика, должна быть не слишком большой. Дальнейшие исследования могут быть направлены на применение описанного подхода к другим задачам, в том числе трекинга объектов, сегментации, 3D-набора точек состояния окружающего мира в реальном времени. Литература 1. Кручинин А.Ю. Управление процессом распознавания образов в реальном времени // Автоматизация. Современные технологии. 2010. № 3. С. 33–37. 2. Кручинин А.Ю. Оптимальный подход к распознаванию протяженных объектов в реальном времени. М., 2016. 305 с. 3. Huang J., Rathod V., Sun C., Zhu M. et al. Speed/accuracy trade-offs for modern convolutional object detectors. Proc. IEEE CVPR, 2017, pp. 3296–3297. DOI: 10.1109/CVPR.2017.351. 4. Yao R., Lin G., Xia S., Zhao J., Zhou Y. Video object segmentation and tracking. ACM Transactions on Intelligent Systems and Technology, 2020, vol. 11, no. 4, pp. 1–47. DOI: 10.1145/3391743. 5. Murray S. Real-Time multiple object tracking – a study on the importance of speed. ArXiv, 2017, art. 1709.03572v2. URL: https://arxiv.org/pdf/1709.03572.pdf (дата обращения: 22.08.2022). 6. Inoue Y., Ono T., Inoue K. Real-time frame-rate control for energy-efficient on-line object tracking. IEICE Trans. Fundamentals, 2018, vol. E101.A, no. 12, pp. 2297–2307. DOI: 10.1587/transfun.E101.A.2297. 7. Mohan A., Kaseb A.S., Gauen K.W., Lu Y.-H., Reibman A.R., Hacker T.J. Determining the necessary frame rate of video data for object tracking under accuracy constraints. Proc. IEEE Conf. MIPR, 2018, pp. 368–371. DOI: 10.1109/MIPR.2018.00081. 8. Jiang Z., Liu Y., Yang C. et al. Learning where to focus for efficient video object detection. Proc. ECCV, 2020, pp. 18–34. DOI: 10.1007/978-3-030-58517-4_2. 9. Chen K., Wang J., Yang S., Zhang X., Xiong Y. et al. Optimizing video object detection via a scale-time lattice. Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2018, pp. 7814–7823. DOI: 10.1109/CVPR.2018.00815. 10. Zhu X., Wang Y., Dai J., Yuan L., Wei Y. Flow-guided feature aggregation for video object detection. Proc. IEEE ICCV, 2017, pp. 408–417. DOI: 10.1109/ICCV.2017.52. References
|
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4980&lang= |
Версия для печати |
| Статья опубликована в выпуске журнала № 1 за 2023 год. [ на стр. 123-129 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Алгоритм обнаружения и сегментации дефектов в полупрозрачных минералах на фотоизображениях
- Построение системы технического зрения для выравнивания содержимого упаковок дельта-манипулятором на пищевом производстве
- Алгоритм детектирования объектов на фотоснимках с низким качеством изображения
Назад, к списку статей