Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Семантический анализ научных текстов: опыт создания корпуса и построения языковых моделей
Аннотация:Данная статья посвящена исследованию методов автоматического обнаружения сущностей (NER) и классификации семантических отношений (RC) в научных текстах из области информационных технологий. Научные публикации содержат ценную информацию о передовых научных достижениях, однако эффективная обработка непрерывно увеличивающихся объемов данных яв-ляется трудоемкой задачей. Требуется постоянное совершенствование автоматических методов обработки такой информации. Современные методы, как правило, довольно хорошо решают обозначенные задачи с помощью глубокого машинного обучения, но, чтобы добиться хорошего качества на данных из конкретных областей знаний, необходимо дообучать полученные модели на специально подготовленных корпусах. Подобные коллекции научных текстов существуют для английского языка и активно используются научным сообществом, однако в настоящее время на русском языке такие корпусы в открытом доступе не представлены. Статья содержит описание созданного корпуса текстов на русском языке. Корпус RuSERRC состоит из 1 600 неразмеченных документов и 80 размеченных сущностями и семантическими отношениями (рассмотрены 6 типов). В работе также предложены несколько модификаций методов для построения моделей, работающих с русским языком. Это особенно актуально, так как большая часть существующих исследований ориентирована на работу с данными на английском и китайском языках и найти в свобод-ном доступе качественные модели для русского языка не всегда возможно. В статью включены результаты экспериментов по сравнению словарного метода, RAKE и методов на основе нейронных сетей. Модели и корпус являются общедоступными, могут быть полезными для проведения исследований и при создании систем извлечения информации.
Abstract:This paper is devoted to the development of methods for named entity recognition (NER) and relation classification (RC) in scientific texts from the information technology domain. Scientific publications provide valuable information about cutting-edge scientific advances, but efficient processing of in-creasing amounts of data is a time-consuming problem. Continuous improvement of automatic methods of such information processing is required. Modern deep learning methods are relatively good at solv-ing these problems with the help of deep computer-aided learning, but in order to achieve outstanding quality on data from specific areas of knowledge, it is necessary to additional training the obtained models on the specially prepared dataset. Such collections of scientific texts are available in English and are actively used by the Russian scientific community, but at present such collections are not pub-licly available in Russian. The paper contains the RuSERRC dataset description, which consists of 1600 unlabeled documents and 80 labeled with entities and semantic relations (6 relation types are considered). Several modifications of the methods for building models for the Russian language are also pro-posed. This is especially important, since most of the existing research is focused on working with data in English and Chinese, and it is not always possible to find high-quality models for the Russian lan-guage in the public domain. The paper includes the results of experiments comparing the vocabulary method, RAKE, and methods based on neural networks. Models and datasets are publicly available, and we hope it can be useful for research purposes and the development of information extraction systems.
| Авторы: Бручес Е.П. (bruches@bk.ru) - Новосибирский государственный университет, Институт систем информатики им. А.П. Ершова СО РАН (ассистент, аспирант), Новосибирск, Россия, Паульс А.Е. (aleksey.pauls@mail.ru) - Новосибирский государственный университет (студент), Новосибирск, Россия, Батура Т.В. (tatiana.v.batura@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (старший научный сотрудник), г. Новосибирск, Россия, кандидат физико-математических наук, Исаченко В.В. (vv.isachenko@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (аспирант), Новосибирск, Россия, Щербатов Д.Р. (d.shsherbatov@g.nsu.ru) - Новосибирский государственный университет (студент), Новосибирск, Россия | |
| Ключевые слова: построение корпуса текстов, нейросетевые модели языка, классификация отношений, извлечение семантических отношений, распознавание сущностей |
|
| Keywords: dataset building, neural network models, relation classification, semantic relation extraction, named entity recognition |
|
| Количество просмотров: 2910 |
Статья в формате PDF Выпуск в формате PDF (7.81Мб) |
С распространением Интернета количество информации, в том числе на естественном языке, стремительно растет. Если говорить о различных областях, то, по данным журнала «Nature», только по биомедицинской тематике мировое научное сообщество издает ежегодно свыше миллиона статей [1]. Научные публикации содержат ценную информацию о передовых научных достижениях, однако эффективная обработка столь огромных объемов данных является трудоемкой задачей. Усложняется она тем, что тексты научных статей слабоструктурированные и извлечь из них какую-либо полезную информацию нетривиально. Предположим, стоит задача выбора науч-ной литературы, направленной на решение не-которой проблемы определенным образом или содержащей разносторонний анализ причинно-следственных связей при описании наблюдаемого феномена. Подобный качественный отбор научной литературы в настоящее время находится за пределами возможностей стандартных поисковых систем. В связи с этим, по мнению авторов, совершенствование методов обработки информации должно быть направлено на выявление и классификацию понятий и отношений, связывающих их, чтобы можно было автоматически идентифицировать соответствующие предметно-специфические семантические отношения в научных публикациях. К примеру, было бы полезно находить и классифицировать отношения, содержащиеся в та-ких выражениях, как «описан новый способ решения задачи» или «результаты экспериментов, полученные предложенным методом, оказались лучше ранее известных» и т.д. Выявление семантических отношений между предметно-ориентированными понятиями позволило бы выявлять исследовательские работы, посвященные той же проблеме, или отслеживать эволюцию результатов по ней. Одной из задач извлечения информации из текстов является распознавание именованных сущностей (Named Entity Recognition, NER). Для ее решения необходимо найти и классифицировать упоминания именованных сущностей (слов или групп слов) в тексте по заранее определенным категориям, таким как имена людей, организации, местоположение, медицинские коды, выражения времени, денежные значения и т.д. Эта задача часто решается вместе с задачей обнаружения отношений (Relation Extraction, RE), суть которой состоит в выделении в тексте пар сущностей, которые могут быть связаны друг с другом. Если заранее заданы классы отношений, то говорят о задаче классификации отношений (Relation Classification, RC) – сопоставлении каждой паре сущностей конкретного класса отношения или распределения вероятностей классов. Для упрощения этих задач вводится следующее ограничение – сущности должны находиться в одном предложении. Современные методы, как правило, неплохо решают обозначенные задачи с помощью глубокого машинного обучения, которое позволяет строить языковые модели на основе огромного корпуса неразмеченных текстов, например Википедии. Чтобы добиться хорошего качества на данных из конкретных областей знаний, необходимо дообучать полученные модели на специально подготовленных корпусах. В статье описан процесс создания такой коллекции текстов по информационным технологиям, которая названа RuSERRC (Russian Scientific Entity Recognition and Relation Extraction Dataset). На этом корпусе проведена серия экспериментов по исследованию и сравнению различных методов, результаты которых также включены в статью. Сам корпус, реализация методов и модели доступны по адресу https://github.com/iis-research-team. Анализ предметной области Задача распознавания сущностей является необходимым этапом извлечения информации из текстов. На сегодняшний день существует достаточно много датасетов общего назначения на разных языках (CONLL-2003, MUC-6, OntoNotes 5.0 и т.д.). Для решения конкретных задач, например, в биомедицинской области, используют специальные корпусы, такие как BIOCREATIVE II, BioInfer и другие. Однако для выполнения семантического анализа также важно извлекать отношения, которые связывают извлеченные сущности, поэтому стали появляться датасеты для извлечения отношений. Следует отметить, что эта задача сложнее, поскольку она неизбежно связана с семантикой языков. Вот почему имеется относительно немного доступных коллекций данных для обучения и оценки как алгоритмов распознавания именованных сущностей, так и методов извлечения и классификации отношений. Наиболее известными датасетами на английском языке общего назначения, содержащими разметку не только сущностей, но и отношений, являются CONLL04, АСЕ 2005, TACRED, SemEval 2010 Task 8 [2]. Для работы с русским языком наиболее популярна коллекция FactRuEval-16, состоящая из новостных текстов [3]. В последнее время появляются новые корпусы для конкретных областей знаний. Например, корпус DREC (Dutch Real Estate Classifieds) [4] на английском и голландском языках создан на основе объявлений о недвижимости. Он состоит из 2 318 документов, размеченных 9 типами сущностей и 2 типами отношений. Датасет re3d (Relationship and Entity Extraction Evaluation Dataset, https://github.com/dstl/re3d) состоит из 7 небольших наборов данных на английском языке и предназначен для анализа защиты и безопасности. Он был аннотирован с использованием двух отдельных схем для сущностей (14 типов) и отношений (11 типов). DFKI SmartData Corpus [5] состоит из 2 598 документов на немецком языке из области мобильности и промышленности и включает тексты новостных лент, сообщения в Твиттере и отчеты о трафике от радиостанций, полиции и железнодорожных компаний. Этот корпус был аннотирован 16 типами сущностей и 15 типами отношений. Недавно был опубликован корпус RuREBus на русском языке, ориентированный на решение бизнес-задач. Он состоит из большого числа неразмеченных официальных документов (распоряжений, постановлений, программ развития и планов). Размеченная часть корпуса включает в себя 188 документов и содержит разметку по 8 типам сущностей и 11 типам отношений [6]. Вызывает интерес научного сообщества и решение задач извлечения сущностей и классификации семантических отношений в научных текстах. Существуют корпусы на английском языке [7], но подобных корпусов на русском языке в открытом доступе нет. Имеющиеся методы для решения задач NER, RE и RC можно условно разделить на три группы. Заметим, что целью этой группировки является не классификация всех этих моделей, а выделение интересных в рамках данного исследования особенностей некоторых популярных методов. К первой группе относятся методы, которые требуют огромного количества человеческого труда, заключающегося в ручном задании правил (например, на основе регулярных выражений, деревьев синтаксического разбора и т.д.) и создании словарей для предметной области. Для этих подходов характерны высокая интерпретируемость моделей и высокое качество за счет длительной разработки и невысокой обобщающей способности. Один из таких подходов, основанный на использовании индуктивного логического программирования, описан в работе [8]. Вторая группа включает в себя методы, основанные на генерации признаков и их последующей обработке нейронными сетями (сверточными или рекуррентными) или алгоритмами классического машинного обучения (SVD-разложения). Человек отвечает за выбор этапов предобработки текста, архитектуру и подбор параметров моделей. Эти методы активно развивались до 2018 года и до сих пор применяются для решения рассматриваемых задач, так как предоставляют разумный компромисс между качеством модели, временем обучения и человеческим трудом. Описание и сравнение методов второй группы можно найти, например, в [7]. В частности, для русского языка в работе [9] предлагается использовать информацию и граф сущностей Wikidata для обучения модели, автоматического создания корпуса и сбора словаря именованных сущностей. Для задачи извлечения и классификации семантических отношений в работе [10] рекомендуется использовать так называемые синтаксические индикаторы: изначально для каждого из отношений формируется словарь лексико-синтаксических маркеров, указывающих на то или иное отношение (например, moved into для Destination, of для Component-Whole и т.д.). На вход нейронной сети подают конкатенацию изначального предложения с индикаторной фразой (e1 indicator e2). Третья группа – методы, основанные на глубоком машинном обучении, в частности, на архитектурах типа Transformer. Трансформеры состоят из кодировщика и декодировщика (одна часть генерирует векторные представления, другая преобразует их в конечные данные), используют механизм self-attention (для выделения зависимостей между токенами в пределах всего предложения) и обучаются на данных большого объема, благодаря чему способны выдавать векторные представления слов, богатые синтаксической и семантической информацией. Это освобождает человека от необходимости подбора низкоуровневых признаков и позволяет сразу переходить к обнаружению и классификации семантических отношений. Модели с такой архитектурой показывают качество, сравнимое с методами из первой группы, но требуют огромного количества данных и большего времени на обработку, чем методы второй группы. Методы третьей группы считаются наиболее перспективными на сегодняшний день. Лучший результат для задачи распознавания сущностей дает модель BERT-MRC [11] на датасете ACE 2005 для английского языка (F1-мера 86,88 %). Лучшие результаты для задачи классификации отношений показывает модель сверточной нейронной сети (EPGNN) на основе графа сущностей [12]. EPGNN объединяет семантические характеристики предложения, созданные предварительно обученной моделью BERT, с топологическими характеристиками графа. Этот метод дает макро-F1 90,2 % на датасете SemEval 2010 Task 8 и оценку микро-F1 77,1 % на коллекции ACE 2005. Еще один метод обнаружения отношений, представленный в работе [13], заключается в тонкой донастройке модели BERTLARGE с помощью метода сопоставления промежутков (matching the blanks). При этом модель BERTLARGE предварительно обучается на текстах, размеченных связанными сущностями. Этот метод дает довольно хорошие результаты на датасете SemEval 2010 Task 8 (F1-мера 89,5 %) и превосходит ранее пред-ложенные методы на коллекции TACRED (F1-мера 71,5 %). Что касается русского языка, то одна из моделей, показывающая лучшие метрики, описана в работе [14]. В модели успешно комбинируются слои Bi-LSTM и CRF (Conditional Random Fields), что позволяет значительно увеличить качество распознавания именованных сущностей. Разметка корпуса RuSERRC Собранный авторами корпус состоит из находящихся в открытом доступе аннотаций научных статей по информационным технологиям. Данные были взяты из журналов «Вестник НГУ. Серия: Информационные технологии» (https://journals.nsu.ru/jit/archive/) и «Программные продукты и системы» (http://www.swsys.ru/). Объем корпуса – 1 600 неразмеченных документов и 80 текстов, вручную размеченных сущностями и отношениями между ними. Каждый документ был размечен двумя аннотаторами независимо, разногласия были разрешены модератором. Процент согласия аннотаторов в задаче выделения сущностей составил 51,77. Значение было вычислено как отношение пересечения выделенных терминов к объединению выделенных терминов. Полученное значение показывает высокую степень субъективности при нахождении слов и фраз, являющихся терминами, и при определении точных границ сущностей, что свидетельствует о сложности решаемой задачи. Процент согласия аннотаторов при выделении и классификации отношений между сущностями составил 70,03. Значение также было вычислено как отношение пересечения выделенных отношений к объединению выделенных отношений. Более подробное описание сущностей и отношений дано далее. В качестве сущностей рассматривались существительные или именные группы, являющиеся терминами в данной предметной области. Авторы придерживались следующего понимания термина: термин – слово или словосочетание, являющееся названием некоторого понятия определенной области науки, техники, искусства и др. В связи с бурным развитием отрасли компьютерных технологий не вся терминология в данной области устоявшаяся: одни термины появляются, другие быстро устаревают. Основной ресурс компьютерной лекси-ки – английский язык. Для переноса терминов в русский язык применяется заимствование путем транскрипции или транслитерации, используются аббревиатуры и другие способы. Однако особую сложность представляет процедура отграничения термина от нетермина. Зачастую довольно сложно понять без контекста, является ли сочетание слов термином. Например, составной термин модель структурной организации единого информационного пространства в нашем корпусе считается сущ-ностью, так как просто слово «модель» в кон-тексте конкретной аннотации не несет полной информации. Другие примеры составных терминов: формальная модель процесса, транзакционная модель, математическая модель упругопластических сред, задачи геонавигации, задача быстрого распознавания типа устройства. В качестве ориентира при принятии решения, что можно считать сущностью, послужил тезаурус [15], первоначально задуманный как источник систематизированной информации для поддержки научной и образовательной деятельности в сфере информационных технологий. Аббревиатуры и составные термины вида «аббревиатура–термин» (ЭЭГ, ЭЭГ-данные), составные понятия, содержащие латинские символы (n-грамма), названия языков программирования (Python, Java, C++) или библиотек (Pytorch, Keras, pymorphy2) также было решено считать сущностями. Разметка сущностей выполнялась в формате BIO (каждой единице текста присваивается значение тега B-TERM, если она является начальной для сущности, I-TERM, если находится внутри термина, или O, если находится вне любой сущности). В рамках такой разметки предполагается, что именованные объекты не являются рекурсивными и не перекрываются. Всего в 80 размеченных текстах содержатся 11 157 токенов и 2 027 терминов. Средняя длина термина – 2,43 слова. Самый длинный термин состоит из 11 токенов. Классы отношений были выбраны в результате анализа работ [2, 7, 16] на основе следующих критериев: - отношение должно толковаться однозначно (например, не рассматривается семантическое отношение Entity-Destination, так как оно также имеет косвенное значение); - отношение должно быть способно связывать между собой научные термины (например, актантами семантического отношения Communication-Topic (an act of communication is about a topic) выступают ненаучные термины, поэтому такое отношение не подходит).
Отношения между сущностями выделялись только в границах одного предложения. Всего в размеченной части корпуса было выделено 620 отношений между сущностями, из них CAUSE – 25, COMPARE – 21, ISA – 90, PARTOF – 77, SYNONYMS – 22, USAGE – 385. Методы извлечения сущностей и классификации отношений Словарный метод извлечения сущностей. Идея этого подхода состоит в использовании заранее составленного словаря терминов. Словарь терминов набирался в полуавтоматическом режиме двумя способами: - из текстов научных статей были извлечены 2-, 3- и 4-граммы слов, отсортированные по значению tf-idf, затем из них вручную были выбраны фразы, которые потенциально могут быть терминами; - из заголовков статей Википедии, входя-щих в подграф категории «Наука», были вруч-ную выбраны слова и фразы, которые потенциально могут быть терминами. Таким образом, был составлен словарь из 17 252 терминов. Основная сложность составления словаря терминов заключается в том, что без контекста сложно понять, является фраза термином или нет. Более того, в разных контекстах одна и та же фраза может и быть, и не быть термином, например, модель, текст, язык и др. Извлечение сущностей с помощью алгоритма RAKE (Rapid Automatic Keyword Extraction). Данный алгоритм предназначен для автоматического извлечения ключевых слов [17]. Сначала применяется список стоп-слов и разделителей для выделения многословных терминов. После этого используется статистическая информация: для каждого слова из ключевых фраз-кандидатов оцениваются ча-стота, с которой оно встречалось, и количество связей между этим словом и остальными. На основании этих двух величин вычисляется вес ключевой фразы, все фразы сортируются по весам, наиболее вероятные ключевые фразы получают максимальный вес. Алгоритм хорошо применим к динамическим корпусам документов и к абсолютно новым областям знаний, при этом не зависит от языка и его особенностей. Использовалась реализация на языке Python (https://github.com/vgrabovets/multi_rake), которая поддерживает работу с русским языком и автоматическое выделение стоп-слов из текста. Следует отметить, что при использовании заранее подготовленного списка стоп-слов из открытых источников сети Интернет (http://datalytics.ru/all/spisok-stop-slov-yandeks-direkta/) алгоритм показывает лучшие результаты. Было замечено, что зачастую алгоритм добавляет в ключевые фразы словосочетания, содержащие глагольные формы, например, «посвящена разработке нового программного обеспечения» или «решения задач геонавигации используются алгоритмы». Так как в качестве сущностей рассматривались существительные или именные группы, было решено выполнить предобработку текстов и убрать глаголы и их формы перед применением RAKE. Для этого использовалась обертка на питоне для инструмента mystem (https://github.com/nlpub/pymystem3) от компании Яндекс. При помощи mystem в тексте выделялись все глагольные формы и принудительно удалялись из него. Применение CNN и LSTM для классификации отношений и извлечения сущностей. В работе [7] приведены результаты международного соревнования SemEval2018 Task 7 по извлечению и классификации семантических отношений в научных текстах на английском языке. Участниками были опробованы различные модели, отличающиеся подходом к расширению датасета, набором признаков и способами их выделения, классификатором и т.д. Исходная задача была разбита на три подзадачи: 1.1 – классификация отношений на вручную размеченных сущностях; 1.2 – классификация отношений на данных с автоматически сгенерированной разметкой сущностей; 1.3 – извлечение и классификация отношений. Авторы данной статьи рассматривают методы и результаты для подзадачи 1.1, так как она наиболее подходит к корпусу. Приводят диаграмму, отображающую популярность используемых методов (CNN, LSTM, SVM и «не ис-пользующие нейронные сети») и средний F1-score для каждого метода. Самым популярным методом оказался CNN (10 систем), по 5 систем использовали LSTM и SVM, 4 системы были построены без использования нейронных сетей. В среднем хороший результат показали решения на основе LSTM (~0.73) и CNN (~0.675), в то время как результат других решений оказался около 0,45. Рассмотрим подробнее модель, показавшую лучший результат на подзадаче 1.1. В моде-ли [18] были использованы эмбеддинги токенов, частеречная разметка и расстояние между сущностями в качестве признаков, в качестве классификатора – ансамбль нейронных сетей с CNN- и LSTM-блоками. Авторы предполагают, что CNN лучше выделяет кратковременные зависимости (между близко расположенными токенами), в то время как LSTM выделяет долговременные зависимости и дополняет CNN. Важную роль сыграло расширение датасета на основе генерации новых примеров с помощью языковой модели и использования перевернутых отношений (авторы утверждают, что, несмотря на нарушенные синтаксис и семантику в предложении с обратным порядком слов, некоторые зависимости между сущностями сохраняются). Также был замечен и исправлен дисбаланс в количестве обучающих примеров для разных классов отношений. На данный момент появились модели на основе архитектуры Transformer, имеющие более глубокую структуру, использующие больше информации о языке и, как следствие, показывающие лучший результат. Несмотря на это, решение команды победителей оказалось полезным – удалось добиться хорошего результата путем грамотного расширения обучающей выборки и применения ряда трюков во время обучения, что может быть использовано и в более сложных моделях. Классификация отношений и извлечение сущностей на основе модели BERT (Bidirectional Encoder Representations from Transformers). Модель BERT представлена компанией Google в 2018 году. На момент публикации она показала наилучшее качество для решения ряда NLP-задач. На вход BERT принимает порядковые номера токенов в специальном словаре (например, на основе BPE), разделенные номерами специальных тэгов (меток) – [CLS] и [SEP]. Первый означает начало последовательности и аккумулирует в результате работы сети общую информацию о последовательности, второй разделяет предложения внутри последовательности. На выходе BERT возвращает векторные представления токенов. Далее эти представления подаются на вход так называемой «голове» (BERT-head) – модели, которая решает некоторую полезную задачу на основе выходных данных BERT-а. Для обучения BERT с нуля используются две модели – Masked LM и NSP (Next Sentence Prediction). Для этого из текстов генерируются обучающие примеры следующего вида: 15 % токенов в последовательности заменяются на тэг [MASK], а сама последовательность состоит из двух предложений, где второе либо следует в каком-то тексте за первым, либо нет (положительный и отрицательный примеры). Соответственно, цель модели Masked LM – как можно лучше восстановить замаскированные слова, а модели NSP – точно предсказать, является ли второе предложение продолжением первого. Такие задачи выбраны специально – они относятся к разным уровням оперирования семантикой языка, что позволяет выделить больше закономерностей из корпуса текстов. Имеет смысл решать эти задачи на очень большом и охватывающем корпусе текстов (например Википедии), что может занять 4 дня при использовании 64 TPU. Это существенный недостаток трансформеров, но есть способ его преодолеть, и он заключается в fine-tuning-e (дообучении). Заметим, что для каждого языка обучать большую модель необходимо только один раз – такая модель охватывает синтаксис и семантику большинства областей языка. Для решения конкретной задачи (например, вопросно-ответная система в банковской сфере) нужно всего лишь дообучить готовую модель на относительно небольшом корпусе специфичных для задачи текстов и использовать полученную языковую модель для решения задачи. Решение конкретной задачи (NER, Sentiment Analysis (тональность текста)) заключается в дообучении BERT с новой головой (чаще всего простым классификатором). Предобучение BERT. Для русского языка есть предобученный на русской Википедии BERT – RuBERT. Используя его веса для инициализации, можно предобучить BERT на меньшем количестве текстов из узкой пред-метной области. В данном случае для предобучения BERT использованы ~1 600 научных текстов на русском языке из области информационных технологий и компьютерной лингвистики.
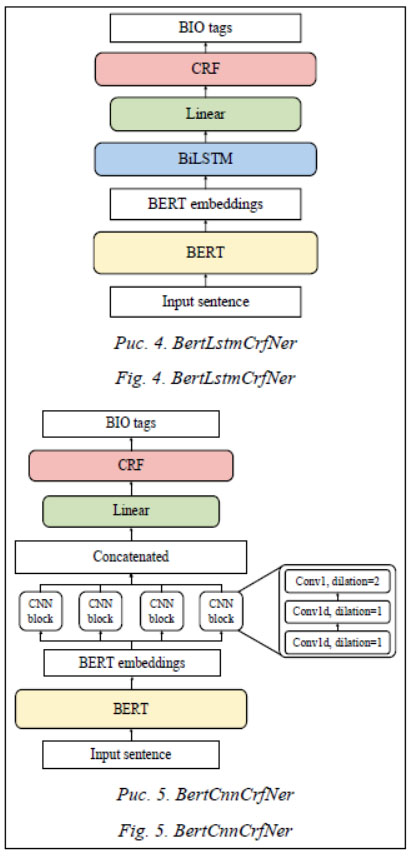
Далее будут представлены основные идеи моделей на основе BERT для NER и RС. Для упрощения в графических представлениях архитектур опущены некоторые детали, а именно функции активации (tanh, relu) и dropout. Также в моделях для NER не используется векторное представление первого токена ([CLS]). BertLinearNer. Самый простой вариант разметки последовательностей – использовать линейный слой поверх полученных с помощью BERT векторных представлений токенов. Архитектура такой модели представлена на рисунке 1. В качестве функции потерь используется перекрестная энтропия (CrossEntropyLoss). BertLstmLinearNer и BertCnnLinearNer. Разумным решением выглядит усложнение классификатора путем добавления слоев, обучающихся нахождению зависимостей в после-довательности. Сверточные слои больше подходят для выделения кратковременных (для токенов на небольшом расстоянии друг от друга) зависимостей, LSTM – для выделения долговременных (для токенов на большом расстоянии друг от друга) зависимостей. В качестве структуры CNN-блоков используется структура, предложенная в проекте Keras-bert-ner (https://github.com/liushaoweihua/keras-bert-ner/). В качестве функции потерь также используется перекрестная энтропия. Полученные модели имеют архитектуру, показанную на ри
BertRC. За основу архитектуры для RC взята архитектура R-BERT [19]. Входные данные для RC отличаются: на вход, помимо по-следовательности токенов, также подаются би-товые маски, показывающие принадлежность токенов сущностям. Это необходимо, чтобы получить из векторных представлений токенов векторные представления сущностей, например, усредняя представления токенов, входящих в сущность. Полученные векторные представления сущностей являются признаками для классификации семантического отношения. В то же время, чтобы получить векторное представление всей последовательности (всего предложения), рекомендуется брать векторное представление первого токена (специальный тег [CLS]), а не усреднять представления всех токенов. На выходе модели расположен слой Softmax, в качестве функции потерь используется MSE loss. Таким образом, была предложена архитектура, показанная на рисунке 6.
Результаты экспериментов Для оценки качества работы алгоритмов извлечения сущностей были выбраны два вида метрик: учитывающие полное совпадение токенов и частичное. В связи с тем, что задача определения границ термина достаточно субъективна (что, например, показывает невысокая степень согласованности асессоров при разметке корпуса), метрика, учитывающая частичное совпадение токенов, видится также релевантной для данной задачи.
Точность – это доля верно извлеченных терминов относительно всех терминов, извлеченных моделью. Полнота – это доля верно найденных моделью терминов относительно всех терминов в тестовой выборке. F-мера представляет собой гармоническое среднее между точностью и полнотой. Результаты работы вышеописанных алгоритмов извлечения сущностей на размеченных вручную данных представлены в таблице 2. Низкие метрики у словарного метода связаны с тем, что словарь состоит только из названий терминов, в то время как в реальных текстах цепочка токенов, из которых состоит термин, может быть разорвана другими токенами, содержать синонимы, сокращения или вовсе быть неполной.
Метрики алгоритма RAKE, учитывающие полное совпадение сущностей, несколько лучше. Оптимизированная версия RAKE позволила еще немного улучшить результат. Было замечено, что алгоритм в целом выделяет больше терминов из текста, но за счет этого ре-зультат точности для метрики, учитывающей частичное совпадение токенов, ниже, чем у словарного и комбинированного подходов. При частичном совпадении сущностей оптимизация с удалением глагольных форм уменьшает мощность множества выделенных терминов, тем самым повышая точность алгоритма, но негативно влияет на полноту, так как некоторые термины все-таки содержат глагольные формы (например, причастия), и затрудняется проверка на наличие термина в размеченной выборке. Таблица 2 Метрики нахождения сущностей Table 2 Metrics for finding entities
Обучение всех моделей на основе BERT проводилось в течение 50 эпох (полных проходов по набору обучающих данных). Для тестирования было выделено 10 % датасета (эти примеры не участвовали в обучении моделей). Получены следующие значения F-меры на корпусе RuSERRC для рассмотренных моделей на основе BERT: NER: Linear – 0,520, LSTM-Linear – 0,530, LSTM-CRF – 0,522, CNN-Linear – 0,496, CNN-CRF – 0,503; RC: 0,670. Точность классификации отношения USAGE составляет 0,89, PARTOF – 0,59, SYNONYMS – 0,67, ISA – 0,57, COMPARE – 0,80, CAUSE – 0,50. Видно, что лучше всего модель распознает отношение USAGE, что неудивительно, так как оно самое высокочастотное в обучающей выборке. Полученные результаты могут быть улучшены при помощи расширения корпуса текстов для предобучения BERT и увеличения количества эпох для предобучения и обучения. Ввиду того, что похожего корпуса и моделей для русского языка для решения поставленных задач авторам не удалось найти, опубликованные результаты других исследователей на других похожих датасетах могут служить лишь ориентиром и демонстрировать, какие результаты способна показать модель в принципе. Так, для задачи RC на корпусе SemEval2018 Task7 значение F-меры составляет 0,828, на FewRel – 0,848; для задачи NER на коллекции данных Open Entity – 0,756. Безусловно, при анализе результатов нужно принимать во внимание, что значения метрик на датасете во многом зависят от его свойств – размера, полноты, качества текстов, обучающих примеров и других характеристик. Видно, что на популярных датасетах на английском языке модели, основанные на BERT и ERNIE, показывают очень хорошие результаты. Заключение В статье описаны эксперименты по сравнению различных методов автоматического обнаружения сущностей и классификации семантических отношений для построения моделей, работающих с русским языком. Последнее особенно актуально, так как большинство существующих исследований ориентировано на работу с данными на английском и китайском языках и найти в свободном доступе качественные модели для русского языка довольно сложно. В будущем планируется провести ряд экспериментов на основе модели ERNIE [20], которая использует дополнительную структурированную информацию о языке. На данный момент предобученные модели ERNIE существуют только для двух языков – английского и китайского. Согласно выводам, сделанным в работе [20], есть основания полагать, что такой подход позволит улучшить результаты для русского языка. Собранный корпус научных текстов RuSECCR, содержащий разметку сущностей и семантических отношений, является общедоступным, может быть полезен при создании систем извлечения информации и для проведения исследований. Работа выполнена при частичной финансовой поддержке РФФИ, проект № 19-07-01134. Литература 1. Landhuis E. Scientific literature: Information overload. Nature, 2016, vol. 535, pp. 457–458. DOI: 10.1038/nj7612-457a. 2. Hendrickx I., Kim S., Kozareva Z., Nakov P., Seaghdha D., Pade S., Pennacchiotti M., Romano L., Szpakowicz S. SemEval-2010 Task 8: Multi-Way classification of semantic relations between pairs of nominals. Proc. V Intern. Workshop on SemEval, 2010, pp. 33–38. 3. Старостин А.С., Бочаров В.В., Алексеева С.В., Бодрова A.A., Чучунков А.С., Джумаев С.С. FactRuEval 2016: Тестирование систем выделения именованных сущностей и фактов для русского языка // Матер. междунар. конф. Диалог: компьютерная лингвистика и интеллектуальные технологии. 2016. С. 688–705. 4. Bekoulis G., Deleu J., Demeester T., Develder C. Reconstructing the house from the ad: Structured prediction on real estate classifieds. Proc. XV Conf. EACL, 2017, vol. 2, pp. 274–279. DOI: 10.18653/V1/E17-2044. 5. Schiersch M., Mironova V., Schmitt M., Thomas Ph., Gabryszak A., Hennig L. A German corpus for fine-grained named entity recognition and relation extraction of traffic and industry events. Proc. LREC, 2018, pp. 4437–4444. 6. Иванин В.А., Артемова Е.Л., Батура Т.В., Иванов В.В., Саркисян В.В., Тутубалина Е.В., Сму-ров И.М. RuREBus-2020: Соревнование по извлечению отношений в бизнес-постановке // Матер. Междунар. конф. Диалог: компьютерная лингвистика и интеллектуальные технологии. 2020. С. 401–416. 7. Gábor K., Buscaldi D., Schumann A.-K., QasemiZadeh B., Zargayouna H., Charnois T. SemEval-2018 Task 7: Semantic relation extraction and classification in scientific papers. Proc. XII Intern. Workshop on SemEval, 2018, pp. 679–688. DOI: 10.18653/v1/S18-1111. 8. Lima R., Espinasse B., Freitas F. A logic-based relational learning approach to relation extraction: The OntoILPER system. EAAI, 2019, vol. 78, pp. 142–157. 9. Сысоев А.А., Андрианов И.А. Распознавание именованных сущностей: подход на основе вики-ресурсов // Матер. Междунар. конф. Диалог: компьютерная лингвистика и интеллектуальные технологии. 2016. С. 746–755. 10. Tao Q., Luo X., Xu R., Wang H. Enhancing relation extraction using syntactic indicators and sentential contexts. Proc. 2019 IEEE XXXI ICTAI, 2019, pp. 1574–1580. DOI: 10.1109/ICTAI.2019.00227. 11. Li X., Feng J., Meng Y., Han Q., Wu F., Li J. A unified MRC framework for named entity recognition. ArXiv, 2020, art. 11476. URL: https://arxiv.org/pdf/1910.11476.pdf (дата обращения: 12.07.2020). 12. Zhao Y., Wan H., Gao J., Lin Y. Improving relation classification by entity pair graph. JMLR: Proc. ACML, 2019, vol. 101, pp. 1156–1171. 13. Soares L.B., FitzGerald N., Ling J., Kwiatkowski T. Matching the blanks: Distributional similarity for relation learning. Proc. 57th Annual Meeting of the ACL, 2019, pp. 2895–2905. DOI: 10.18653/v1/P19-1279. 14. Anh L.T., Arkhipov M.Y., Burtsev M.S. Application of a Hybrid Bi-LSTM-CRF model to the task of russian named entity recognition. CCIS, 2018, vol. 789, pp. 91–103. DOI: 10.1007/978-3-319-71746-3_8. 15. Федотов А.М., Идрисова И.А., Самбетбаева М.А., Федотова О.А. Использование тезауруса в научно-образовательной информационной системе // Вестн. НГУ. Сер.: Информационные технологии. 2015. Т. 13. № 2. С. 86–102. 16. Aditya S., Sinha A. Uncovering relations for marketing knowledge representations. ArXiv, 2020, art. 08374. URL: https://arxiv.org/pdf/1912.08374.pdf (дата обращения: 20.07.2020). 17. Rose S., Engel D., Cramer N., Cowley W. Automatic keyword extraction from individual documents. Text Mining, 2010, pp. 1–20. DOI: 10.1002/9780470689646.CH1. 18. Rotsztejn J., Hollenstein N., Zhang C. ETH-DS3Lab at SemEval-2018. Task 7: Effectively combining recurrent and convolutional neural networks for relation classification and extraction. Proc. XII Intern. Workshop on SemEval, 2018, pp. 689–696. DOI: 10.18653/v1/S18-1112. 19. Wu S., He Y. Enriching pre-trained language model with entity information for relation classification. Proc. 28th ACM Intern. Conf. on Information and Knowledge Management, 2019, pp. 2361–2364. DOI: 10.1145/3357384.3358119. 20. Zhang Z., Han X., Liu Z., Jiang X., Sun M., Liu Q. ERNIE: Enhanced language representation with informative entities. Proc. 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 1441–1451. DOI: 10.18653/v1/P19-1139. References
| ||||||||||||||||||||||||||||||||||



| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4789&lang= |
Версия для печати Выпуск в формате PDF (7.81Мб) |
| Статья опубликована в выпуске журнала № 1 за 2021 год. [ на стр. 132-144 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: