Journal influence
Bookmark
Next issue
Text analysis method for tariff classification goods in customs
Abstract:The use of artificial intelligence in customs administration is the most important practical sphere of the digital transformation of socio-economic systems. The paper considers one of the particular problems of this area: the choice of a product code according to the tariff classification based on declarations presented in Russian. The object of study was a voltage stabilizer. Analysis of customs declarations, performed by a person using the keywords in the product description, showed the need for machine learning methods. To do this, 1005 customs declarations were submitted, filed for three commodity items, which were regarded as three classes in the classification problem. Using the Orange Anaconda Navigator platform, it was possible to apply visual design methods to build a workflow diagram for solving the problem. The diagram includes a pre-processing stage, at which word clouds and a word bag were built, and a da-ta set was formed, the columns of which are lemmas, and the lines are individual declarations. In order to reduce the dimension of the problem, methods of filtering, removing n-grams, and stop words were applied. The resulting data set allows us to choose the best classifier in terms of accuracy, specificity, sensitivity, as well as using the error matrix and AUC curve. Training and test samples, as well as cross-validation were used.. The best in terms of the range of indicators analyzed was the classifier based on logistic regression, the equation of which made it possible to determine the most important lemmas for solving the classification problem. Since the complexity of solving the problem depends on the number of identifiable classes, it is ad-visable to use specific classifications for a small number of classes, including them in the information-analytical systems along with accounting systems, databases of customs declarations, request-response systems, and others.
Аннотация:Применение искусственного интеллекта в таможенном деле является важнейшей практической сферой цифровой трансформации социально-экономических систем. В статье рассмотрена одна из частных задач данной сферы – выбор кода товара по тарифной классификации на основе деклараций, представленных на русском языке. Объектом исследования выступал стабилизатор напряжения. Анализ таможенных деклараций, выполненный человеком по ключевым словам в описании товара, показал необходимость применения методов машинного обучения. Для этого были рассмотрены 1 005 таможенных деклараций, поданных по трем товарным позициям, которые расценивались как три класса в задаче классификации. Использование платфор-мы Orange Anaconda Navigator позволило применить методы визуального проектирования для по-строения workflow-диаграммы решения задачи. Диаграмма включает этап предпроцессинга, на котором были построены облака слов и мешок слов, а также сформирован набор данных, столбцами которого являются леммы, а строками – отдельные декларации. С целью сокращения размерности задачи применены методы фильтрации, удаления n-грамм и стоп-слов. Полученный набор данных позволяет выбрать лучший классификатор по показателям точности, специфичности, чувствительности, а также с помощью матрицы ошибок и AUC-кривой. Использованы обучающая и тестовая выборки, а также кроссвалидация. Лучшим по комплексу анализируемых показателей оказался классификатор, основанный на логистической регрессии, уравнение которой позволило определить наиболее важные леммы для решения задачи классификации. Поскольку сложность решения задачи зависит от числа идентифицируемых классов, целесо-образно использовать частные классификации для небольшого числа классов, включая их в со-став информационно-аналитических систем вместе с учетными системами, базами таможенных деклараций, системами «запрос–ответ» и другими.
| Authors: E.V. Zhiryaeva (Zhiryaeva-ev@ranepa.ru) - North-West Institute of Management of the Russian Residential Academy of National Economy and Public Administration (Associate Professor), St. Petersburg, Russia, Ph.D, V.N. Naumov (naumov122@list.ru ) - North-West Institute of Management of the Russian Residential Academy of National Economy and Public Administration (Professor), St. Petersburg, Russia, Ph.D | |
| Keywords: customs administration, digital technologies, AI methods, classification errors, classification methods, text mining, harmonized system (HS), commodity nomenclature |
|
| Page views: 3821 |
PDF version article |
Во внешнеэкономической деятельности решение о коде товара определяет издержки предприятия-импортера на оплату таможенной пошлины. В странах, где доходы от импорта бюджетообразующие, код является приоритетом для таможенных органов. Применение искусственного интеллекта в этой области – важнейшая практическая сфера управления в социально-экономических системах. Тарифная классификация в странах основана на Гармонизированной системе (ГС) описания и кодирования товаров. Языками системы являются английский и французский. Страны Евразийского экономического союза (ЕАЭС) используют русскоязычную Товарную номенклатуру внешнеэкономической деятельности ЕАЭС (ТН ВЭД ЕАЭС), основанную на ГС. Органы, принимающие решения о классификации, могут иметь фискальные или политические (инте- ресы в ВТО) причины для выбора кода товара. Часто в таможенных декларациях товар описывают так, чтобы он соответствовал тексту товарной позиции (четырехзначный код). Такая практика приводит к появлению ошибок. В то же время накоплен огромный практический опыт декларирования товаров, а правильный код может быть определен путем статистического анализа с применением методов машинного обучения. Обзор методов Задачи анализа текстов могут быть решены с помощью, например, метода нейронных сетей [1]. Анализу русскоязычных текстов посвящены исследования [2, 3], а решению задачи классификации судебных актов – статья [4]. В данных работах рассматриваются вопросы классификации текстов для задач различной семантической направленности. Раскрытые вопросы позволяют сделать вывод о целесообразности использования методов text mining и машинного обучения при решении задач тарифной классификации. Анализом классификации для целей таможенных тарифов занимаются многие исследователи. Подчеркивается, что ошибки классификации возникают вследствие слабой обеспеченности программными средствами [5]. Предложена форма представления данных для потенциального программного продукта [6]. Дана схема процесса автоматической классификации на основании синтаксического и лингво-статистического анализа деклараций на товары [7]. Отдельные авторы выступают с критикой подхода к классификации на основе ключевых слов [8]. В рассмотренных работах конкретные решения и анализ полученных результатов не приводятся. В статье [9] предлагается автоматическая система обнаружения кода ГС, основанная на визуальных свойствах продукта и текстовом анализе пояснений. Извлеченные корни слов позволяют построить частотные таблицы слов для каждой из сформированных тем, содержащие вероятности слов. Такой подход базируется на методах text mining [10] и может быть принят за основу рассматриваемого исследования. Отметим, что в указанном источнике анализируется текст на английском языке. Цель работы – применить text mining к решению задачи по тарифной классификации на русском языке, выявить ограничения и недостатки метода, определить области применения. Работа носит методологический характер. Объект исследования Рассмотрим задачу классификации инверторного стабилизатора напряжения «Штиль» серии ИнСтаб (350-550 ВА). Стабилизатор подает напряжение на газовый котел, подключается к входной сети переменного тока (220 В), а котел включается в розетку на корпусе стабилизатора. Рассмотрим три возможных варианта классификации. По первому варианту в товарной позиции (т.п.) 8504 товар может рассматриваться как статический электрический преобразователь (850440 – трансформаторы электрические, статические электрические преобразователи…). Второй вариант – т.п. 8536 – аппаратура электрическая для коммутации или защиты электрических цепей или для подсо- единений к электрическим цепям… на напряжение не больше 1000 В, субпозиция 853630 – устройства для защиты электрических цепей прочие. Третий вариант классификации – т.п. 9032 – приборы и устройства для автоматического регулирования или управления, субпозиция 903289 – прочие. В нормативных и судебных документах встречаются различные варианты классификации товаров данного типа, что создает неоднозначную для таможенного администрирования задачу. В практике декларирования аналогичные товары классифицируются в различных товарных позициях номенклатуры. Классификация по ключевым словам, выполненная человеком В распоряжении специалиста, решающего проблему классификации, имеется база данных по предварительным решениям и декларациям на товары. Воспользуемся базой предварительных классификационных решений Binding tariff information (BTI) Европейского Союза и базой таможенных деклараций компании «Альта-софт». Согласно экспертному мнению, товар может быть описан следующими ключевыми словами: - инверторный стабилизатор; - для стабилизации электрического напряжения; - электрический стабилизатор; - для регулирования напряжения; - регулятор напряжения; - преобразователь напряжения; - для преобразования напряжения; - электрический преобразователь; - для автоматического регулирования; - электронный регулятор; - источник питания; - для бесперебойного питания. Суммируя информацию из двух источников, можно определить ключевые слова для исследованных субпозиций (табл. 1) (источник: собственные расчеты на основе данных alta.ru и https://ec.europa.eu/taxation_customs/dds2/ebti/ ebti_home.jsp?Lang=en). С учетом полученной статистики следует сделать выбор в пользу субпозиции 850440 (последняя строка в таблице 1). Как представляется, слово «регулирование» определяет классификацию в товарной позиции 9032, а «преобразование» – в 8504. Таблица 1 Ключевые слова исследуемых субпозиций Table 1 Keywords of researched sub-headings
Предварительный анализ выявил, что рассмотренные ключевые слова могут попадать и в другие товарные позиции. Распределение частот по товарным позициям показывает, что одного ключевого слова для классификации недостаточно. При этом для разных товарных позиций они должны быть разными. Следует использовать методы анализа текстов. Материалы и методы Большая размерность задачи классификации приводит к необходимости применения декомпозиции с целью ее упрощения. Классификация целесообразна в пределах отдельных групп товаров, товарных позиций, субпозиций, подсубпозиций. Необходимо определить набор данных, на основе которого будет решаться задача классификации. С этой целью произведен анализ деклараций, поданных по субпозициям 850440, 853630 и 903289. Большое число деклараций позволило сформировать сбалансированную обучающую выборку. Она содержит 1 005 наблюдений (документов) – 405, 397 и 202 для каждого класса товаров, обозначенных соответственно как первый (850440), второй (853630) и третий (903289). Каждое наблюдение включает категорийную и текстовую переменные. Первая из них определяет субпозицию (класс ситуации), вторая содержит описание товара, сформулированное в декларации. Декларации на товары имеют большое число слов, чисел, знаков препинания и др. (рис. 1).
Для уменьшения размерности задачи исключим из облака n-граммы, представляющие собой устойчивые словосочетания. В дальнейшей обработке будут участвовать только одиночные леммы анализируемого текста. С целью уменьшения числа лемм также выполним задачу фильтрации, установив определенные фильтры. · Фильтр на частоту лемм в текстах. Включение редких токенов приводит к переобучению модели. Высокая частота может привести к тривиальным выводам, когда классификатор выявляет слова, входящие в название субпозиции или подсубпозиции классифицируемых товаров. Зададим диапазон частот лемм от 0,05 до 0,3. Левая граница выбрана на основе общепринятой в статистике практики, предполагающей, что события, вероятность которых меньше 0,05, считаются редкими. Правая граница определена тем, что события не должны быть частыми. · Фильтр на общий размер облака. Чем больше слов в облаке, тем больше размерность задачи и сложнее классификатор. Возникает противоречие между точностью классификации и сложностью модели. Зададим максимальное число лемм равным 30. В дальнейшем исследуем зависимость качества классификации от данного числа. · Фильтр на стоп-слова. В их качестве могут выступать знаки препинания, служебные слова. Облако слов позволяет дополнительно в качестве стоп-слов определить десятич- ные цифры, числа, некоторые английские слова и др. После предобработки из полученного набора данных формируется мешок слов, который в дальнейшем используется для решения задачи классификации. Его столбцами являются отдельные токены, строками – отдельные документы, а ячейками – частоты токенов в до- кументе. Таким образом, формируется таблица данных – фрейм, который может быть использован для решения задачи классификации.
Проблема машинного обучения связана с возможными ситуациями «недообучения» и «переобучения» алгоритма. С целью их выявления, а также оценки качества классификации предусмотрено разделение сформированного набора данных на две выборки: обучающую и контролирующую. Первая из них позволяет построить классификатор, а вторая – проверить его качество на новых исходных данных. Для оценки качества классификатора будут использованы матрица ошибок, а также традиционные показатели качества. Результаты Сценарий анализа деклараций на товары приведен на рисунке 3. Его узлами являются виджеты, реализующие частные задачи процессов предобработки текста, выбора лучшего классификатора и построения классификационной модели. Этапы предобработки позволили сократить число токенов и уменьшить размерность ящика слов, на основе которого строится классификатор.
Дальнейший выбор классификатора производился на основе сравнительного анализа значений показателей качества, матрицы ошибок, ROC-кривой [13]. Общий вид формируемой матрицы приведен в таблице 2 (источник – [14]). Ее размерность соответствует мультиклассовому классификатору. Таблицу можно рассматривать как результат решения трех задач бинарной классифика- ции с положительными (positive) и отрицательными (negative) примерами. Под положитель- ным понимается пример, принимаемый по умолчанию. Для каждого такого классификатора можно определить четыре ситуации: истинно положительная (TP), ложноположительная (FP), ложноотрицательная (FN), истинно отрицательная (TN). Так как в таблице 2 совмещены три таблицы для каждого бинарного классификатора, все ее ячейки, кроме лежащих на главной диагонали, обозначены False. Это указывает, что данные ячейки содержат число различных ошибочных ситуаций. Таблица 2 Матрица ошибок Table 2 Confusion Matrix
Для оценки качества классификаторов ис- пользованы показатели: - точность классификации (accuracy, CA):
- точность классификации (Precision):
- полнота классификации (Recall):
- среднее гармоническое двух последних показателей (F1):
Кроме того, используется показатель AUC, связанный с так называемой ROC-кривой, графиком, показывающим качество бинарной классификации. В таблице 3 приведены результаты сравнительного анализа качества классификаторов по указанным показателям (здесь и в следующих таблицах приведены данные собственных расчетов). Была использована тестовая выборка размером в 30 % от имеющейся выборки с числом повторений, равным десяти. Ее случайный выбор, а также усреднение приводят к корректной оценке показателей качества классификации для всех выбранных методов. Отметим, что нет ни одного метода, наилучшего по всем показателям качества. Найдем среднее анализируемых показателей (mean) и стандартное квадратическое отклонение (s.d). Точечные оценки параметров показывают, что лучшие результаты для среднего получены для методов бустинга и случайного леса. Однако интервальная оценка параметров с учетом стандартного отклонения показывает на пересечение доверительных интервалов. Поэтому методы обладают примерно одинаковым качеством. В дальнейшем будем использовать метод логистической регрессии, позволяющий построить логистические уравнения. Таблица 3 Результаты оценки качества классификаторов Table 3 Classifier quality assessment results
Откорректированный сценарий, включающий данный метод и отдельную проверочную выборку, приведен на рисунке 5. С помощью логистической регрессии проанализируем изменение качества классификации при изменении числа анализируемых лемм и их относительных частот. В таблице 4 приведены результаты анализа, показывающие, что с ростом мощности облака значения показателей качества существенно не изменяются. Таблица 4 Зависимость качества классификации от числа анализируемых лемм Table 4 Classification Quality Dependence of the number of analyzed lemmas
Приведенные в таблице 5 значения AUC показывают малое влияние выбранных показателей на качество классификации. Можно ограничиться сравнительно небольшим размером облака слов, например, равным 50, и выбранным диапазоном относительной частоты слов для включения в анализ. Таблица 5 Зависимость качества классификации (по значению показателя AUC) от значения максимальной относительной частоты лемм Table 5 Classification quality dependence (by AUC value) from the value of the maximum relative frequency of lemmas
С целью упрощения логистической модели выполним ее регуляризацию L1-методом. Единичное значение параметра регуляризации позволяет исключить от 20 (для второго класса) до 30 (для первого класса) лемм. Для регуляризованной модели проанализируем матрицу ошибок (табл. 6). Она построена Таблица 6 Матрица ошибок для построенного классификатора Table 6 Error matrix for the constructed classifier
Показатели качества для модели по итогам ее проверки сведены в таблицу 7. Их высокие значения свидетельствуют о хорошем качестве классификатора. При этом наилучшие значения получены для первого класса, а наихуд- шие – для третьего, что подтверждается ROC-кривыми, приведенными на рисунке 6. Таблица 7 Значения показателей качества модели Table 7 Model quality indicators values
Обсуждение Проанализируем, какие леммы входят в ло- гистические уравнения для каждого класса, а также значения и знак коэффициентов моделей. Результаты приведены в таблице 8. Таблица 8 Коэффициенты уравнений логистической регрессии Table 8 Coefficients of equations logistic regression
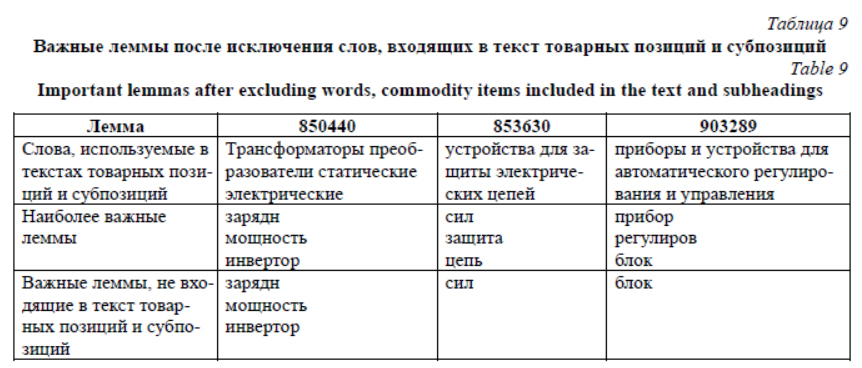
Наиболее важными для первого класса (850440) являются леммы «зарядн», «мощность», «инвертор». Для второго класса (853630) – «сил», «защита», «цепь». Для третьего класса (903289) – «прибор», «регулиров», «блок». Программы, которые применяются при заполнении деклараций на товары, предлагают пользователю описание с помощью слов, содержащихся в текстах товарных позиций и субпозиций. Такие слова, вероятно, следует считать дополнительными стоп-словами. Результат, полученный после их исключения, представлен в таблице 9. Таким образом, с учетом весов, приведенных в таблице 8, можно осуществлять частотную классификацию по словам. Проверим исходный пример: «Инверторный стабилизатор напряжения «Штиль» серии ИнСтаб». В приведенном в таблице 9 списке лемм «инвертор» позволяет отнести пример к первому классу. Предварительная оценка, полученная анализом Заключение
Проведенное исследование позволяет сделать следующие выводы. Имеющиеся выборки по декларациям на товары позволяют построить тарифные классификаторы с использованием методов анализа текстов. Поскольку сложность решения задачи классификации зависит от числа классов, такие классификаторы целесообразно строить для небольшого числа классов для нескольких субпозиций. Ни один классификатор не способен безошибочно определить код анализируемого товара. Следовательно, его следует рассматривать как систему, которая может выработать рекомендации для поддержки принятия решений при заполнении декларации на товары и проверке классификационного кода сотрудником таможенного органа. Возможность определить вероятность ошибки при определении принадлежности к конкретному коду позволит повысить степень обоснованности решений. Увеличение размера обучающей выборки может повысить качество классификации. Поэтому классификаторы, подобные рассмотренному в статье, должны входить в состав информационно-аналитических систем вместе с учетными системами, базами таможенных деклараций, системами «запрос–ответ» и др. Литература 1. Андреев А.М., Березкин Д.В., Морозов В.В., Симаков К.В. Автоматическая классификация текстовых документов с использованием нейросетевых алгоритмов и семантического анализа // ECM-journal. 2007. URL: https://ecm-journal.ru/docs/Avtomaticheskaja-klassifikacija-tekstovykh-dokumentov-s-ispolzovaniem-nejjrosetevykh-algoritmov-i-semanticheskogo-analiza.aspx (дата обращения: 14.01.2020). 2. Осочкин А.А., Фомин В.В., Флегонтов А.В. Метод частотно-морфологической классификации текстов // Программные продукты и системы. 2017. Т. 30. № 3. C. 478–486. DOI: 10.15827/0236-235X.119.478-486. 3. Фомин В.В., Фомина И.К., Осочкин А.А. Классификация текстов на основе частотного и морфологического анализов с применением алгоритмов Data-mining // Информатизация образования и науки. 2016. Т. 31. № 3. С. 137–152. 4. Алексеев А.А., Катасёв А.С., Кириллов А.Е., Кирпичников А.П. Классификация текстовых документов на основе технологии text mining // Вестн. Казанского технологич. ун-та. 2016. Т. 19. № 18. С. 116–119. 5. Андреева Е.И., Кушнер Г.Ф. Выбор объектов контроля правильности классификации товаров с учетом соотношения кода ТН ВЭД и величины их таможенной стоимости // Вестн. Российской таможенной академии. 2016. № 3. С. 32–38. 6. Андреева Е.И., Говоров В.В. Методическое обеспечение таможенного контроля правильности классификации товаров в современных условиях // Вестн. Российской таможенной академии. 2019. № 3. С. 69–77. 7. Васина Е.Н., Филиппова Л.А. Методы и модели классификации для автоматического определения кода товара по товарной номенклатуре внешнеэкономической деятельности // Вестн. Российской таможенной академии. 2017. № 2. С. 81–88. 8. Андреева Е.И., Суглобов А.Е. Искусственный интеллект: перспективы цифровизации таможенных технологий // Russ. J. of Management. 2019. Т. 7. № 2. URL: https://riorpub.com/ru/nauka/article/29659/view (дата обращения: 14.01.2020). DOI: 10.29039/article_5d4846bd0cd8d6.84213476. 9. Turhan B., Gozde B. Akar, Turhan C., Yukse C. Visual and textual feature fusion for automatic customs tariff classification. Proc. IEEE 16th Int. Conf. Inform. Reuse and Integration, 2015, pp. 76–81. DOI: 10.1109/IRI.2015.22. 10. Feinerer I., Hornik K., Meyer D. Text Mining Infrastructure in R. JSS, 2008, vol. 25, iss. 5, 54 p. DOI: 10.18637/jss.v025.i05. 11. Porter M.F. An algorithm for suffix stripping. Program, 1980, vol. 14, no. 3, pp. 130–137. DOI: 10.1108/00330330610681286. 12. Willett P. The Porter stemming algorithm: then and now. Program Electronic Library and Information Systems, 2006, vol. 40, no. 3, pp. 219–223. DOI: 10.1108/00330330610681295. 13. Han J., Kamber M. Data Mining: Concepts and Techniques. Morgan Kaufmann Publ., 2006, 800 p. 14. Паклин Н.Б., Орешков В.И. Бизнес-аналитика: от данных к знаниям. СПб: Питер, 2013. 701 c. References
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






| Permanent link: http://swsys.ru/index.php?page=article&id=4740&lang=en |
Print version |
| The article was published in issue no. № 3, 2020 [ pp. 538-548 ] |
Perhaps, you might be interested in the following articles of similar topics: