Journal influence
Bookmark
Next issue
Implementing an expert system to evaluate technical solutions innovativeness
Abstract:The paper presents a possible solution to the problem of algorithmization for quantifying innovativeness indicators of technical products, inventions and technologies. The concepts of technological novelty, relevance and imple-mentability as components of product innovation criterion are introduced. Authors propose a model and algorithm to calculate every of these indicators of innovativeness under conditions of incompleteness and inaccuracy, and sometimes inconsistency of the initial information. The paper describes the developed specialized software that is a promising methodological tool for using in-terval estimations in accordance with the theory of evidence. These estimations are used in the analysis of com-plex multicomponent systems, aggregations of large volumes of fuzzy and incomplete data of various structures. Composition and structure of a multi-agent expert system are presented. The purpose of such system is to process groups of measurement results and to estimate indicators values of objects innovativeness. The paper defines ac-tive elements of the system, their functionality, roles, interaction order, input and output interfaces, as well as the general software functioning algorithm. It describes implementation of software modules and gives an example of solving a specific problem to determine the level of technical products innovation. The developed approach, models, methodology and software can be used to implement the storage technology to store the characteristics of objects with significant innovative potential. Formalization of the task's initial data significantly increases the possibility to adapt the proposed methods to various subject areas. There appears an op-portunity to process data of various natures, obtained during experts’ surveys, from a search system or even a measuring device, which helps to increase the practical significance of the presented research.
Аннотация:Представлено возможное решение задачи алгоритмизации количественной оценки показателей инновационности технических изделий, изобретений, технологий. Введены понятия технологической новизны, востребованности и имплементируемости – составных частей критерия инновационности продукта. Предложены модель и алгоритм вычисления каждого из указанных показателей инновационности в условиях неполноты и неточности, а иногда и противоречивости исходной информации. В статье описывается разработанное специализированное ПО, которое является перспективным методологическим инструментом для использования интервальных оценок в соответствии с теорией свидетельств. Эти оценки применяются при анализе сложных многокомпонентных систем, агрегации больших объемов нечетких и неполных данных различной структуры. Представ-лены состав и структура мультиагентной экспертной системы, назначение которой – групповая обработка результатов измерений и оценок значений показателей инновационности объектов. Определяются активные элементы системы, их функциональность, роли, порядок взаимодействия, входные и выходные интерфейсы, общий алгоритм функционирования ПО. Описывается реализация программных модулей, приводится пример решения конкретной задачи по определению уровня инновационности технических изделий. Разработанные подход, модели, методика и ПО могут быть использованы в реализации технологии хранилища характеристик объектов, обладающих значительным инновационным потенциалом. Формализация исходных данных задачи существенно повышает адаптивность предложенных методов к различным предметным областям. Появляется возможность обработки данных различной природы, полученных в результате опроса экспертов, из поисковой системы или даже с измерительного устройства, что способствует повышению практической значимости представленной разработки.
| Authors: Ivanov V.K. (mtivk@mail.ru) - Tver State Technical University, Tver, Russia, Ph.D, Obraztsov I.V. (sunspire@list.ru) - Tver State Technical University, Tver, Russia, Ph.D, Palyukh B.V. (pboris@tstu.tver.ru) - Tver State Technical University, Tver, Russia, Ph.D | |
| Keywords: certificate, estimation, invention, implementability, relevance, expert system, data warehouse, term, innovation |
|
| Page views: 4774 |
PDF version article Full issue in PDF (4.91Mb) |
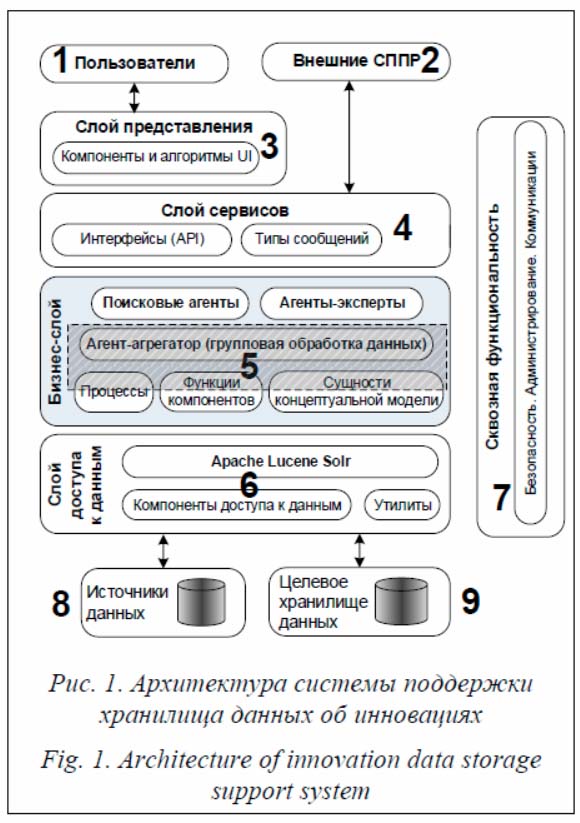
Говоря о инновационности продуктов, необходимо учитывать три важных аспекта: что есть инновационность продукта, как определить количественную меру для ее оценки, с помощью каких удобных и эффективных инструментов можно вычислить уровень инновационности продукта и проанализировать результаты. В этой связи актуальным представляется практическое решение задачи алгоритмизации количественной оценки показателей инновационности таких продуктов, как технические изделия, изобретения, технологии. В исследованиях, касающихся различных аспектов инновационного развития общества, определение «инновация» всегда основано на таких коннотациях, как «новый», «научный», «повышающий эффективность», «приносящий прибыль». В данной работе введены понятия технологической новизны, востребованности и имплементируемости – составных частей критерия инновационности искомого объекта или продукта. Исходя из этих понятий разработаны модель и алгоритм вычисления каждого из указанных показателей инновационности в условиях неполноты и неточности, а иногда и противоречивости исходной информации. Реализацией предложенных концепций является описываемое в статье ПО специализированной экспертной системы, которая позволяет вычислить и проанализировать показатели инновационности продуктов, в том числе в динамике. Предполагается, что разработанные подход, модели, методика и ПО могут быть использованы в реализации технологии хранилища характеристик следующих объектов: - предприятия малого и среднего бизнеса (анализ ретроспективы и перспективы конкретных инноваций, поиск текущих и вероятных трендов в развитии инновационных товаров и услуг); - бизнес-инкубаторы, стартапы (экспертиза инновационности проектных решений, оценка благоприятных для инвестиций факторов); - образовательные учреждения (оценка инновационности образовательного контента, включая достижения обучающихся); - органы управления (определение инновационных направлений для стимулирования деловой активности персонала, предприятий). Архитектура системы поддержки хранилища данных об инновациях
- специализированные прикладные системы для информационного обеспечения имплементации инноваций; - внешние (по отношению к рассматриваемой) системы поддержки принятия решений (СППР); - визуализация состава хранилища данных об инновациях, поисковых паттернов и результатов поиска по ним, индикаторов инновационности объектов хранилища, наборов связанных объектов; - программные интерфейсы для взаимодействия с внешними СППР и компонентами слоя представления; - активные элементы, или акторы (агенты); детализация каждого типа акторов представлена в таблице 1; - компонент Apache Lucene Solr – программная реализация модели векторного пространства документов для предварительной обработки данных, планируемых к помещению в целевое хранилище данных; - компоненты, отвечающие за безопас- ность данных, администрирование, сетевые коммуникации; - ресурсы Интернета, специализированные хранилища и БД; - реестр инновационных решений научно-технических задач.
Показатели инновационности объектов Введем понятия технологической новизны, востребованности и имплементируемости как составных частей критерия инновационности искомого объекта. Количественная оценка этих показателей основана на гипотезе об адекватности отображения жизненного цикла продуктов в различных хранилищах данных при условии доступа к достаточному количеству таких хранилищ. Для поиска информации о потенциально инновационных объектах в хранилищах данных предложена лингвистическая модель архетипа искомого объекта, образующая поисковый паттерн. Термы модели классифицируются как ключевые свойства, описывающие структуру объекта, условия применения или результаты функционирования. Область определения архетипа определяется маркером. Поисковые запросы конструируются как комбинации термов и маркера. При значительном количестве термов используется генетический алгоритм генерации запросов и фильтрации ре- Под технологической новизной архетипа объекта понимаются его значительные улучшения, новый способ использования или предоставления (субъектами новизны являются потенциальные пользователи или сам производитель). Оценка индикатора новизны основана на нормированном интегральном значении числа найденных элементов информации об объекте (документов, записей и т.п.) в результате поиска в гетерогенных БД. Предполагается, что для новых объектов количество найденных элементов информации, релевантных поисковому паттерну, будет меньше, чем для давно существующих и известных объектов. Формальное выражение для вычисления значения индикатора новизны объекта следующее: где Nov – новизна архетипа объекта; S – общее количество выполненных запросов к БД; Rk – число документов, найденных в результате выполнения k-го запроса к БД, содержащей информацию о рассматриваемой предметной области; R01(Rk, …) – вариативная функция, нормирующая значение Rk на диапазон [0; 1]. Могут быть использованы различные функции R01(Rk, …). Например: – линейное нормирование
– нелинейное нормирование со статистическими характеристиками данных
– нелинейное экспоненциальное нормирование
Здесь Rmin и Rmax – наименьшее и наибольшее, соответственно, число документов, найденных при выполнении всех S запросов; Линейное нормирование (2) предпочтительно, когда значения Rk достаточно равномерно заполняют интервал Rmin–Rmax. Если среди всех значений Rk имеются редкие аномалии, намного превышающие типичный разброс, следует использовать выражение (3), а если Rmax ® ¥, целесообразно применить выражение (4). Востребованность архетипа объекта – это осознанная потенциальным производителем необходимость в этом объекте, оформленная в спрос. Оценка индикатора востребованности основана на нормированном интегральном значении частоты обращения пользователей к информации о потенциально инновационном продукте или услуге. Формальное выражение для вычисления значения индикатора новизны объекта:
где Rel – востребованность архетипа объекта; Fk – частота обращения пользователей к информации о потенциально инновационном продукте или услуге, найденной при выполнении k-го запроса из S запросов; F01(Fk, …) – вариативная функция, нормирующая значение Fk на диапазон [0; 1]. Выбор вида функции F01(Fk, …) осуществляется аналогично выбору функции R01(Rk, …) при расчете Nov в соответствии с (2)–(4). Используемые в качестве аргументов Fmin, Fmax, Имплементируемость архетипа объекта определяет технологическую обоснованность, физическую осуществимость и способность интеграции объекта в систему для получения желаемого эффекта. Оценка индикатора имплементируемости основана на нормированном значении среднего периода восстановле- ния уровня новизны и/или востребованности архетипа объекта. Предполагается, что со временем архетип объекта теряет новизну и/или востребованность. Однако новые технологии, конструкция, улучшенные функциональные и потребительские характеристики могут повысить значения индикаторов новизны и востребованности. Чем быстрее это происходит, тем выше имплементируемость. Формальное выражение для вычисления значения индикатора имплементируемости объекта:
где Imp – имплементируемость архетипа объекта; Nov(t) – функция, показывающая зависимость новизны архетипа объекта от времени и определенная на временном интервале [t0; tm]; Rel(t) – функция зависимости востребованности архетипа объекта от времени, определенная на том же временном интервале [t0; tm]; Учитывая непосредственную количественную оценку индикаторов инновационности, будем считать, что этот подход дополняет традиционные [3, 4]. Обоснование использования теории свидетельств Поскольку возможны очевидные неполнота и неточность информации об объектах, полученной из различных источников, введены нечеткие показатели вероятности того, что объект обладает технологической новизной, востребован потребителями и реализуем, то есть может быть имплементирован. В экспертных системах в случаях неопределенности исходных данных выбор того или иного математического метода обработки зависит от степени такой неопределенности. Вероятностные и статистические методы, методы нечеткой логики применяются в условиях частичной неопределенности и требуют об- работки больших объемов информации, опе- рирования с повторными выборками, детер- минированного характера вероятностных характеристик [5–7]. Для смягчения подобных требований целесообразно применение теории свидетельств Демпстера–Шафера [8, 9]. Математический аппарат теории свидетельств явля- ется распространенным современным подходом, применяемым в различных задачах оптимизации, диагностики технических систем, оценки уровней соответствия технических показателей целевым значениям, оценки уровня инвестиционного потенциала технических решений и инноваций и в других актуальных задачах. Принимается, что базовая вероятность m попадания результатов измерения показателя инновационности объекта (Nov, Rel и Imp) в интервал значений A определяется следующим образом:
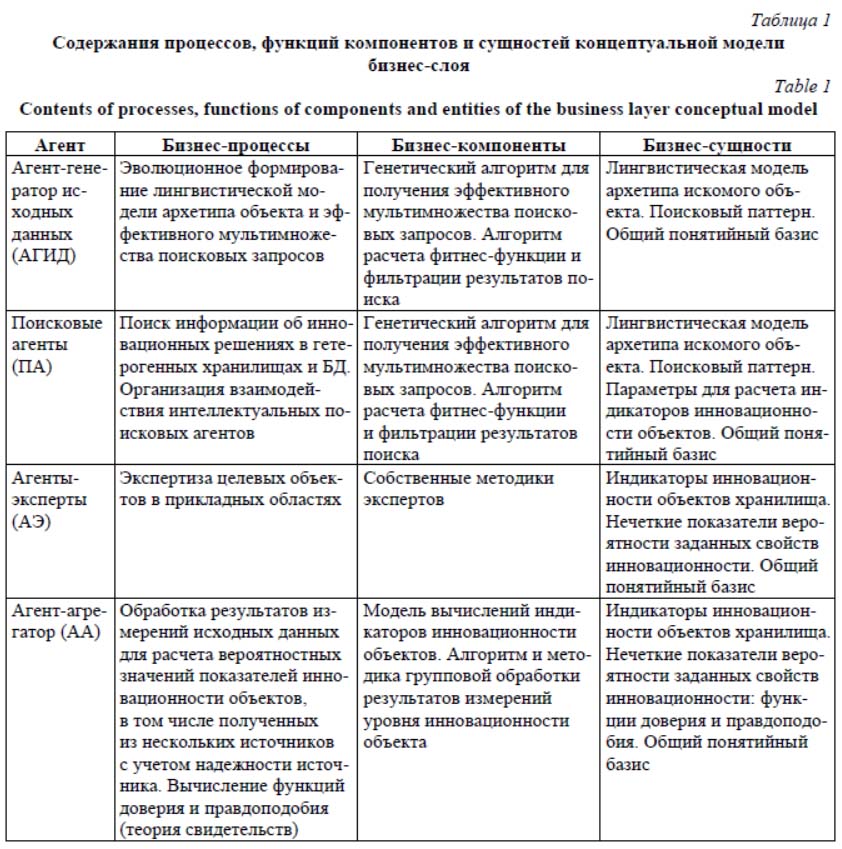
где W – множество значений результатов измерения показателя; P(W) – множество всех подмножеств W. Далее для заданных k интервалов рассчитываются функция доверия: Математический аппарат теории свиде- тельств ориентирован на получение объективной модели согласования экспертных суждений, наблюдений или измерений. Отсутствие знаний об объекте, о предыстории процесса, невозможность использования повторных выборок позволяют применять теорию свидетельств к задачам, в которых теория вероятностей и нечеткая логика принципиально неприменимы. В целях повышения гибкости и достоверности получаемых моделей в ряде исследований предлагаются различные модификации математического аппарата теории свидетельств в части правил агрегирования свидетельств из независимых источников и учета конфликтности экспертных мнений [10–13]. На предыдущих этапах работы по данному проекту изложены принципы специфического применения теории свидетельств к оценке показателей инновационности объектов, описаны лингвистическая модель, технология обработки результатов измерений, полученных из поисковых систем, а также разработана методика оценки достоверности источника данных. В [14] как объект исследования рассмотрена электронная информационно-образовательная среда университета в контексте кооперации об- разовательных и бизнес-процессов. Описаны возможности применения предложенных ранее подходов к оценке новизны, востребованности и имплементируемости компонентов среды. В работе [15] отражена концепция практического применения теории свидетельств для оценки инновационного потенциала технических решений и изобретений, а также моделирования, диагностики и оценки состояния сложных производственных систем. Алгоритмизация ПО оценки инноваций Общее представление функциональности ПО системы показано на рисунке 2 в виде диаграммы сценариев UML.
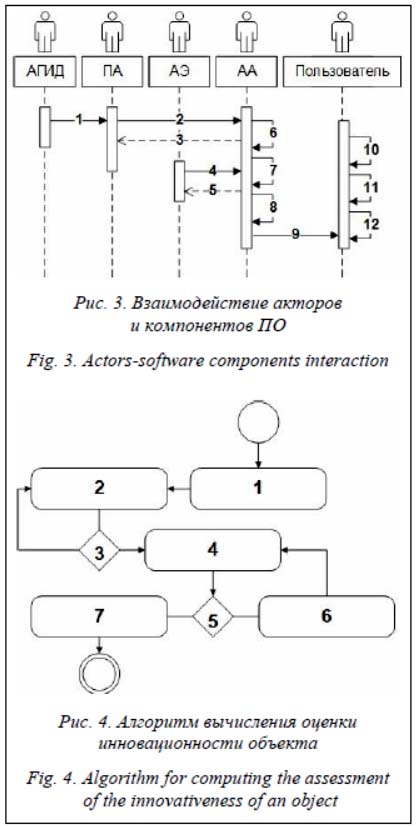
Опишем алгоритм вычисления количественной оценки инновационности многокомпонентного объекта (рис. 4). Структуризация исходных данных происходит по четырем абстрактным категориям – компоненты, показатели, экспертные группы, оценки. После сбора исходных данных (действие 1) осуществляется сортировка экспертных мнений и их аналогов (оценок) с последующим формированием таблицы свидетельств (действие 2). Если в пределах одной экспертной группы встречаются одинаковые оценки, они объединяются в одно свидетельство с учетом количества экспертов, давших оценку. Далее производится расчет базовых вероятностей для каждого свидетельства. Обработка свидетельств выполняется по всем рассматриваемым показателям для каждого компонента объекта. Цикл формирования таблицы свидетельств (действия 2 и 3) заканчивается при достижении последней эксперт- ной оценки (действие 3). Далее выполняются сортировка (действие 4) и комбинирование (действие 6) свидетельств из различных источников. Целью является объединение свидетельств, числовые интервалы которых пересекаются друг с другом, с учетом влияния конфликтных свидетельств, числовые интервалы которых не пересекаются. Процедура комбинирования объединена с расчетом границ математического ожидания интервалов и значений функций доверия и правдоподобия. Цикл комбинирования свидетельств (действия 4–6) заканчивается после обработки всех свидетельств (действие 5). Алгоритм завершается ранжированием (действие 7) комбинированных оценок. В таблицу интегральных оценок выводятся оценки, для которых нижняя и верхняя границы вероятности наличия свойства инновационности у объекта максимальны.
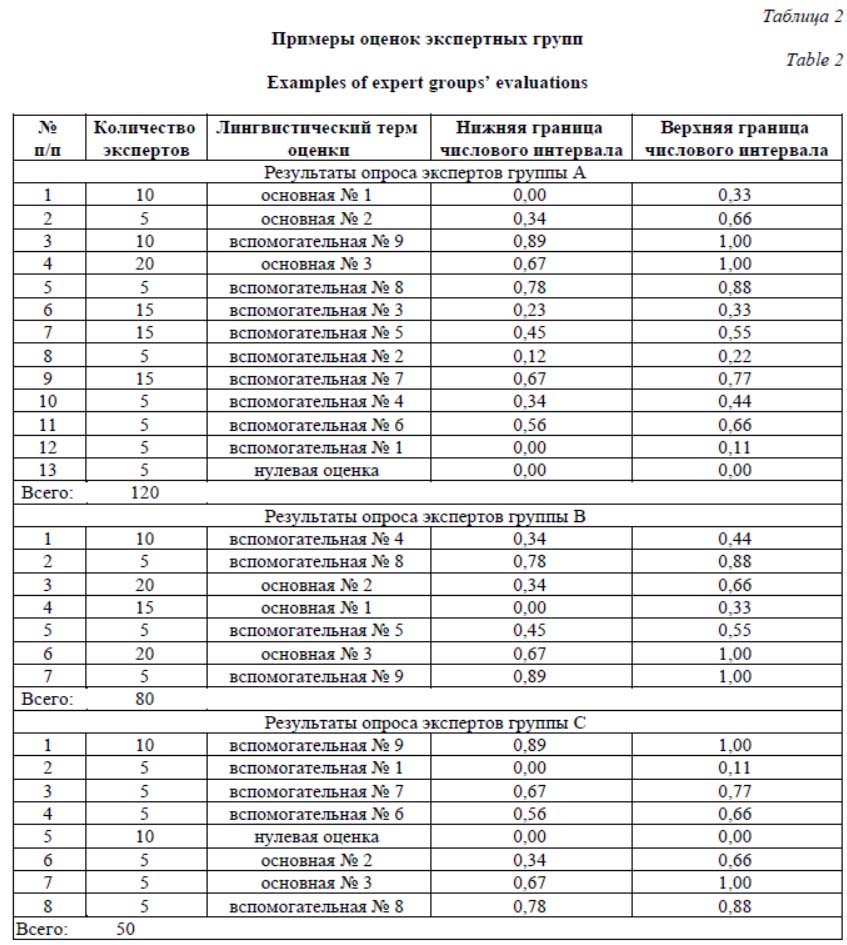
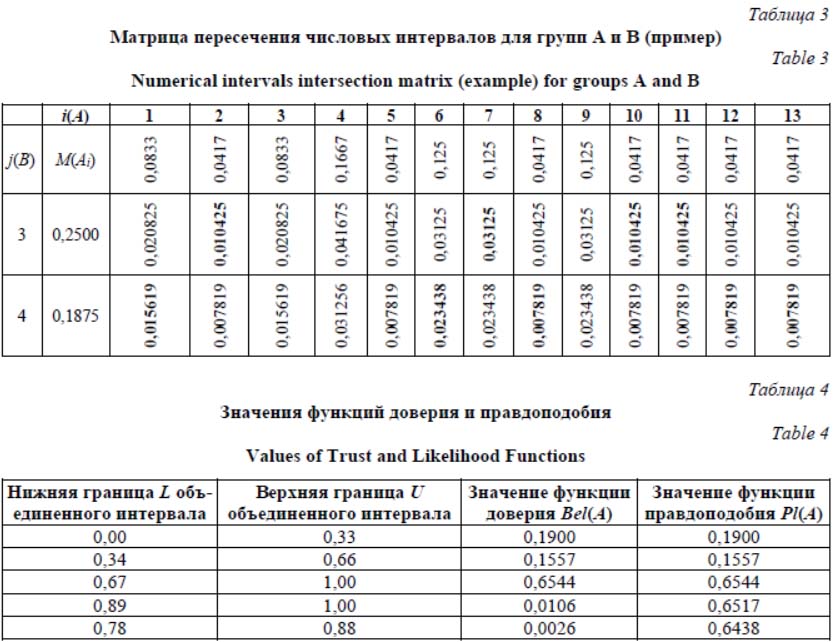
Реализация ПО Прототип экспертной системы реализован в виде веб-приложения с графическим интер- фейсом пользователя. Приложение разработано на языке SpiderBasic, компилятор которого генерирует оптимизированный код JavaScript для выполнения в браузере с поддержкой стандарта HTML5. Графический интерфейс приложения имеет иерархическую структуру и состоит из главного окна (см. http://www.swsys.ru/uploaded/image/2019-4/2019-4-dop/14.jpg) и ряда вспомогательных диалоговых окон, отображаемых в процессе работы. Взаимодействие пользователя с приложением сегментировано на раздельные операции посредством переключаемых объектных контейнеров, каждый из которых содержит группы стандартных элементов управления – текстовые поля, электронные таблицы, списки, кнопки, переключатели и флажки. С помощью графического интерфейса пользователь последовательно настраивает па- раметры экспертной системы, заполняет опросный лист, а также получает доступ к таблицам свидетельств и выходным расчетным показателям. Представим основные классы данных, используемые в экспертной системе. Класс Estimate – Оценка: Lingvo.s – лингвистический терм (string), LBound.f – нижняя граница интервала (float), UBound.f – верхняя граница интервала (float). Класс ExpGrp – экспертная группа: GroupName.s – название экспертной группы, ExperCount.i – количество экспертов в группе. Класс Evidence – свидетельство: Lingvo.s – лингвистический терм (string), LBound.f – нижняя граница интервала (float), UBound.f – верхняя граница интервала (float), Numb_c.i – количество экспертов, давших оценку (integer), Numb_N.i – количество экспертов в группе (integer), Val_mA.f – базовая вероятность или масса (float), Val_bA.f – функция доверия (float), Val_pA.f – функция правдоподобия (float). Класс DSstruc – структура Демпстера–Шейфера: LBound.f – нижняя граница (float), UBound.f – верхняя граница (float), Massa.f – масса (float). Класс MatrAB – матрица пересечения множеств: SubM.f – произведение масс (float), Stat.i – статус пересечения интервалов (integer), SumL.f – объединенная нижняя граница (float), SumU.f – объединенная верхняя граница (float). Класс SourceData – исходные данные: ComponentNumber.i – количество компонентов, IndicatorNumber.i – количество показателей, ExpGroupsNumber.i – количество экспертных групп, EstimatesNumber.i – количество оценок в шкале, RoundDigsNumber.i – количество разрядов округления, InterviewNumber.i – количество результатов опроса, List ComponentNames.s() – список названий компонентов, List IndicatorNames.s() – список названий показателей, List ExpertGroupes.ExpGrp() – список экспертных групп с двумя подтипами (название группы, количество человек), List EstimateScale.estimate() – список оценок шкалы с тремя подтипами (лингвистический терм, нижняя граница, верхняя граница), List InterviewRslt. estimate() – список результатов опроса экспертов с тремя подтипами (лингвистический терм, нижняя граница, верхняя граница). Данные конкретного расчета показателей инновационности могут быть экспортированы в файл в формате JSON. При необходимости дальнейшей обработки эти данные могут быть импортированы в экспертную систему. Стандартизация формата данных приложения особенно актуальна при оценке показателей на основе большого количества технических измерений или расчетов. Приведем фрагмент файла экспорта данных, построенного по результатам выполнения поисковых запросов в нескольких поисковых системах с целью оценки изобретений и технических решений по нормированному показателю технологической новизны: { "ComponentNumber": 10, "IndicatorNumber": 1, "ExpGroupsNumber": 5, "EstimatesNumber": 20, "RoundDigsNumber": 2, "InterviewNumber": 800, "ComponentNames": ["Электрический глаз", "Ген-активированный материал для регенерации тканей", "Имплантация миниконтура", "Лечение пародонта", "Электронный индикатор уровня"], "IndicatorNames": ["Нормированный показатель КН4"], "ExpertGroupes": [{"GroupName": "Yandex", "ExperCount": 16}, {"GroupName": "ЕГИСУ НИОКТР", "ExperCount": 16}, {"GroupName": "Google", "ExperCount": 16}], "EstimateScale": [{"Lingvo": "0–5 %", "LBound": 0, "UBound": 0.05}, {"Lingvo": "95–100%", "LBound": 0.95, "UBound": 1}], "InterviewRslt": [{"Lingvo": "95–100 %", "LBound": 0.95, "UBound": 1}, {"Lingvo": "60–65 %", "LBound": 0.6, "UBound": 0.65}, {"Lingvo": "0–5 %", "LBound": 0, "UBound": 0.05}] } Пример работы экспертной системы Рассмотрим обобщенно оценку показателя инновационности с помощью обсуждаемой экспертной системы. Зададим оценочную интервальную числовую шкалу от 0 до 1,0, каждому интервалу присвоим соответствующий лингвистический терм. Как правило, эксперту-специалисту удобнее работать с лингвистическими термами, а числовая составляющая шкалы необходима для математической обработки данных. В случае использования результатов измерений в качестве экспертных данных числовые значения (получаемые, например, от поисковых агентов) следует соотносить с соответству- ющими им числовыми интервалами оценочной шкалы. Причем назначение узких оценочных интервалов дает более точные выходные значения, но приводит к повышению вероятности конфликтов экспертных оценок. В свою очередь, использование широких оценочных интервалов снижает вероятность конфликтности экспертных оценок, но при этом приводит и к снижению точности выходных данных экспертной системы. Рассмотрим ситуацию, в которой присутствуют три независимых источника свидетельств – A, B и C. Эти источники в терминах предлагаемой экспертной оценки представляют собой экспертные группы со строго определенным количеством экспертов. Предположим, что экспертные группы A, B и C включают 120, 80 и 50 экспертов соответственно. Примеры оценок экспертных групп приведены в табли- це 2. Каждая экспертная оценка представляет собой уникальное свидетельство в пределах своей группы. Основной характеристикой свидетельств является его базовая вероятность или масса m(A), соотнесенная с границами числового интервала в исходной оценочной шкале: M(Ai) = Ai)/Ni, (8) где Ai – интервал i-го свидетельства; Ai) – количество экспертов, давших i-е свидетельство; Ni – общее количество экспертов в группе. Необходимо скомбинировать свидетельства из экспертных групп A, B и C между собой, учитывая их однозначность и конфликтность. В разработанном алгоритме используется правило комбинирования Демпстера, суть которого заключается в формировании матрицы пересечения числовых интервалов свидетельств и расчете комбинированных базовых вероятностей, нормализованных с помощью коэффициента конфликтности. В таблице 3 для примера представлена матрица пересечения числовых интервалов свидетельств из группы А (все свидетельства) и группы B (свидетельства из диапазонов основных оценок № 1 и № 2). Номера интервалов групп A и B обозначены как i(A) и j(В) соответственно. В ячейках матрицы представлены произведения базовых вероятностей свидетельств. Жирным шрифтом выделены значения в ячейках, соответствующие областям полного или частичного пересечения числовых интервалов свидетельств. Остальные ячейки соответствуют областям конфликтующих (непересекающихся) свидетельств. Базовые вероятности пар неконфликтных свидетельств, имеющих одинаковые числовые интервалы, суммируются:
Базовые вероятности пар конфликтных свидетельств, числовые интервалы которых не пересекаются, также суммируются:
Для данного примера
В процессе работы экспертной системы строится диаграмма обобщенных аккумулированных функций распределения, визуализирующая числовые интервалы исходных свидетельств до процедуры комбинирования и их базовые вероятности (см. http://www.swsys.ru/ uploaded/image/2019-4/2019-4-dop/15.jpg). По оси абсцисс диаграммы откладываются числовые интервалы фокальных элементов в порядке возрастания, а по оси ординат – значения масс фокальных элементов с накоплением. Данные диаграммы наглядно иллюстрируют согласованность (наложение областей диаграммы) и конфликтность экспертных мнений из нескольких экспертных групп. Разными цветами обозначены свидетельства из исходных экспертных групп. Области, в которых все три цвета накладываются друг на друга, соответствуют областям согласованности экспертных мнений. Ширина столбцов диаграммы соответствует числовым интервалам оценочной шкалы. Кроме того, диаграмма отражает оценки, которые не были задействованы в экспертном опросе (горизонтальные линии между заполненными областями). Демонстрационная версия приложения доступна по адресу http://virtlabs.tech/apps/DST/ Dempster_Shafer_App.html. Функциональность приложения поддерживается для всех популярных веб-браузеров. Заключение Представляется, что описанное в статье ПО является перспективным методологическим инструментом и в определенной степени спо- собствует решению таких актуальных задач, как имплементация алгоритма количественной оценки инновационных свойств объектов, использование интервальных оценок в соответствии с теорией свидетельств при анализе сложных многокомпонентных систем, агрега- ция больших объемов нечетких и неполных данных различной структуры. Важной особенностью представленной разработки является возможность абстрактной формализации исходных данных задачи, что существенно повышает адаптивность данного метода к различным предметным областям. Таким образом, появляется возможность обработки данных различной природы, полученных в результате опроса экспертов, из поисковой системы или даже с измерительного устройства, что, в свою очередь, способствует повышению практической значимости представленной разработки. Исследование выполнено при финансовой поддержке РФФИ в рамках научных проектов №№ 18-07-00358, 17-07-01339. Литература 1. Ivanov V.K., Palyukh B.V., Sotnikov A.N. Efficiency of genetic algorithm for subject search queries. Lobachevskii J. Math., 2016, no. 12, рр. 244–254. DOI: 10.1134/S1995080216030124. 2. Luke S. Essentials of Metaheuristics. 2013. URL: http://cs.gmu.edu/~sean/book/metaheuristics (дата обращения: 20.09.2019). 3. Tucker R.B. Driving growth through innovation: how leading firms are transforming their futures. Berrett-Koehler Publ., San Francisco, 2008, 240 p. 4. OECD/Eurostat, Oslo Manual: Guidelines for Collecting, Reporting and Using Data on Innovation. 2018, 258 p. DOI: 10.1787/9789264304604-11-en. 5. Анисимов Д.Н., Вершинин Д.В., Колосов О.С., Зуева М.В., Цапенко И.В. Диагностика текущего состояния динамических объектов и систем сложной структуры методами нечеткой логики с использованием имитационных моделей // Искусственный интеллект и принятие решений. 2012. № 3. С. 39–50. 6. Доценко Н.В., Шостак Е.И. Анализ альтернативных вариантов состава команд исполнителей высокотехнологичных проектов на основе кластеризации и ранжирования групповых экспертных оценок // Авиационно-космическая техника и технология. 2016. № 7. С. 164–172. 7. Швед А.В. Анализ моделей экспертных свидетельств // Проблеми інформаційних технологій. 2016. № 19. C. 88–95 (рус.). 8. Shafer G. A Mathematical Theory of Evidence. Princeton Univ. Press, 1976, 314 p. 9. Yager R., Liping L. Classic works of the Dempster–Shafer theory of belief functions. Springer, London, 2008, 223 p. DOI: 10.1007/978-3-540-44792-4. 10. Zhou D., Tang Y., Jiang W. A modified belief entropy in Dempster–Shafer framework. PLOS ONE, 2017, vol. 12, iss. 5, e0176832. DOI: 10.1371/journal.pone.0176832. 11. Ганцева Е.А., Каладзе В.А. Статистический подход разрешения неопределенности экспертных суждений на основе теории случайных множеств // Вестн. ВГУ. 2015. № 2. C. 82–88. 12. Конченкова К.И. Комбинирование экспертных оценок инновационных проектов ранних стадий развития с использованием метода Демпстера // Проблемы экономики и менеджмента. 2015. № 12. C. 189–192. 13. Giuseppe C., Giacomo M.G., La Fata M.C. A Dempster–Shafer theory-based approach to compute the Birnbaum importance measure under epistemic uncertainty. IJAER, 2016, vol. 11, no. 21, pp. 10574–10585. 14. Иванов В.К., Глебова А.Г., Образцов И.В. Количественная оценка инновационности технических решений в инженерном образовании // Инфорино: матер. IV Междунар. науч.-практич. конф. М.: Изд-во МЭИ, 2018. C. 114–119. 15. Palyukh B., Ivanov V., Sotnikov A. Evidence theory for complex engineering system analyses. Proc. 3rd I Int. Sc. Conf. IITI, 2019, pp. 70–79. DOI: 10.1007/978-3-030-01818-4_7. References
|
| Permanent link: http://swsys.ru/index.php?page=article&id=4658&lang=en |
Print version Full issue in PDF (4.91Mb) |
| The article was published in issue no. № 4, 2019 [ pp. 696-707 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Экспертный выбор ключевых показателей взрывных работ на карьерах
- Определение весовых коэффициентов для аддитивной фитнес-функции генетического алгоритма
- Инструментальное средство для автоматизированного создания экспертных систем
- Оценка эффективности тренажерной подготовки методом целевого управления
- Автоматизация оценки знаний студентов в системе электронного обучения ECOLE
Back to the list of articles