Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Разработка базы данных и конвертера для извлечения и анализа специализированных данных, получаемых с медицинского аппарата
Аннотация:При разработке экспертных систем могут возникнуть затруднения, связанные с используемыми форматами хранения или обмена данными. Возможны ситуации, когда данные хранятся в закрытом формате либо закрытый формат имеют файлы обмена для таких систем. Это затрудняет автоматический анализ данных, поскольку приходится заносить их в экспертную систему вручную. Однако существуют методы, позволяющие преобразовывать данные в удобный для работы формат. В статье рассматривается анализ двоичных файлов базы данных медицинского аппарата для исследования сложных патологий зрения с целью извлечения из нее данных биофизических исследований для последующего анализа. Поскольку в стандартном программном обеспечении отсутствуют возможности обмена информацией с внешними системами в открытых форматах, требуется разработка дополнительных методов и программных средств для определения физической структуры данных для последующего конвертирования в открытый формат. Исходными данными для анализа являются информация о данных, хранящихся в базе данных медицинского аппарата, а также общие принципы физического представления данных в компьютерных системах. После определения структуры файлов с данными выполняется разработка конвертера. Выходные файлы конвертера могут быть использованы в дальнейшем при обучении нейронных сетей. Такой подход позволяет достаточно быстро создавать базу образцов (прецедентов), исключив необходимость ручного переноса данных, и может служить основой для анализа данных в других подобных ситуациях.
Abstract:When developing expert systems, there may be difficulties associated with storage or data exchange formats. There may be situations when the data is stored in a proprietary format, or exchange files for such systems have proprietary format. This makes automated data analyze difficult, since they have to be manually entered into an expert system. However, there are methods that allow converting data into an easy-to-use format. The paper considers the analysis of database binary files of a medical apparatus for studying com-plex vision impairment in order to extract biophysical studies data for further analysis. Since the standard software does not allow information exchange with external systems in open formats, it is necessary to develop additional methods and software to determine data physical structure for subse-quent conversion to an open format. The initial data for the analysis is information about what data are stored in a medical device data-base, as well as general principles of physical data representation in computer systems. Converter de-veloping follows determining the structure of data files. Converter output files can be used in further neural network training. This approach allows quick creating of a database of samples (precedents) eliminating the need for manual data transfer. The proposed approach can further serve as a basis for data analysis in other similar situations.
| Авторы: Еремеев А.П. (eremeev@appmat.ru) - Национальный исследовательский университет «Московский энергетический институт» (профессор), г. Москва, Россия, доктор технических наук, Ивлиев С.А. (siriusfrk@gmail.com) - Национальный исследовательский университет «Московский энергетический институт» (аспирант), Москва, Россия | |
| Ключевые слова: двоичные файлы, нейронные сети, открытые данные, закрытый формат, бд, представление данных, анализ данных |
|
| Keywords: binary files, neural network, open data, closed format, database, data presentation, data analysis |
|
| Количество просмотров: 7202 |
Статья в формате PDF |
Важной частью любой системы (в статье рассматривается экспертная система) является подсистема хранения данных. В зависимости от важности и оперативности доступа к данным, значимости самих данных, используемых алгоритмов и методов работы в системе выбираются различные способы организации хранения данных. Это могут быть простые текстовые файлы, представляющие наборы пар вида <имя параметра, значение>, а также структурированные файлы как в текстовом, так и в двоичном виде. Могут использоваться файлы с разметкой типа XML или JSON [1, 2]. Нередки случаи смешанного (гетерогенного) хранения данных, например, заголовки для данных хранятся в одном формате, а сами данные - в другом. Все это обусловливает необходимость наличия (разработки), помимо стандартного ПО для хранения и оперирования данными, специализированного ПО - конвертера, который может быть использован для преобразования данных из одного формата в другой. Такая ситуация сложилась из-за отсутствия единых подходов к организации хранения данных [1]. Простой пример – метод хранения числовых последовательностей. Если используется БД, то можно хранить числовые последовательности в отдельных таблицах, на что будет расходоваться дополнительная память и создаваться нагрузка на ядро СУБД при работе с ними. Другим подходом является сохранение (запись) числовой последовательности в некоторый массив (строковый или бинарный) в отдельное поле БД. По мере дальнейшего развития технологии хранения данных наблюдается переход к форматам, простым в понимании и содержащим как сами данные, так и их разметку. Легкость понимания обеспечивается наличием разметки в файлах и соглашения о формате представления тех или иных типов данных (строковые, целые, вещественные, логические, дата и время и т.д.) [3–5]. Однако довольно большое количество данных хранится в системах (обычно специализи Альтернативным подходом является решение задачи так называемой обратной разработки формата данных и соответствующей БД с применением специализированного ПО, который будет далее проиллюстрирован на примере медицинского аппарата, используемого для диагностики сложных патологий зрения (патологий сетчатки). Описание ПО аппарата медицинской диагностики Tomey
Аппарат Tomey предоставляет пользователю ряд экранов-окон для анализа ЭРГ (см. http://www.swsys.ru/uploaded/image/2019-3/ 2019-3-dop/3.jpg, http://www.swsys.ru/uploaded/ image/2019-3/2019-3-dop/4.jpg). ПО Tomey предоставляет возможности для просмотра и создания отметок на результатах исследования, однако в нем отсутствуют функции для экспорта в форматы, которые были бы пригодны для взаимодействия с другими программными продуктами, например, экспертными системами. В результате было решено разработать дополнительную БД для аппарата Tomey. Описание БД аппарата Tomey БД Paradox, поставляемая в составе ПО Tomey EP-1000, реализована на ядре Borland Database Engine версии 5.0.1, собственно СУБД написана на языке Delphi. Средства разработки и драйверы чтения для данной БД обновлялись в последний раз в 1996 г., после чего разработка и поддержка данного продукта были прекращены.
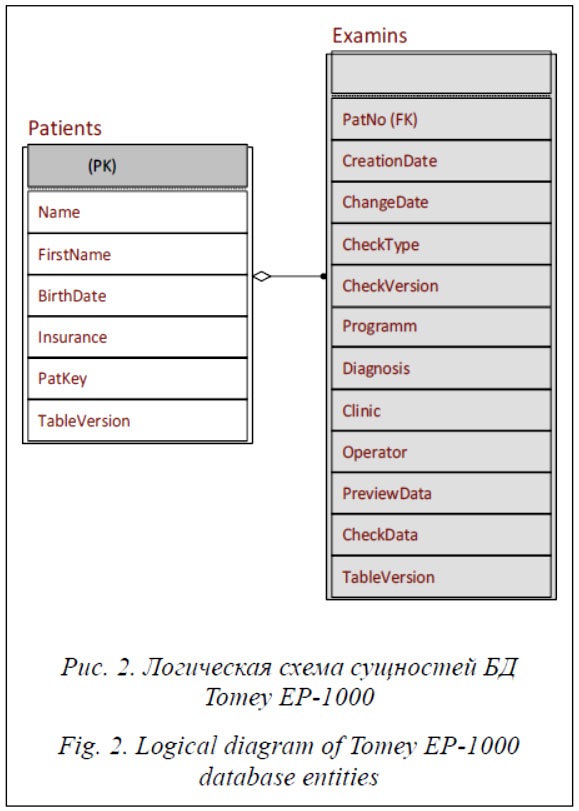
Анализ двоичных данных Файловая структура и архитектура БД Tomey достоверно неизвестны, поэтому будем исходить из предположения, что поля, хранящие двоичные данные об исследованиях, на самом деле не содержат эту информацию непосредственно, а ссылаются на некоторые внешние файлы или области внешних файлов. Действительно, в папке с БД есть два файла, имена которых соответствуют описанным выше таблицам: Examins.db и Patients.db. Файлы имеют значительный размер, поэтому будем считать, что они представляют информацию из полей таблицы. Известно, что бинарные поля включены в состав сущности Examins, поэтому рассмотрим именно этот файл в побайтовом виде. Будем исходить из предположения, что файл разделен на записи, число которых равно числу исследований в БД. Известно, что БД с тестовым набором данных содержит 3 934 записи об исследованиях. Для анализа файла используем редактор файлов 010 Editor. Просматривая файл, можно заметить, что он заполнен информацией неравномерно: пу- стые участки чередуются с участками, содержащими некоторую информацию. Предположим, что информативные участки и являются записями, хранящими данные об исследованиях. Поскольку считаем, что файл состоит из записей, выделим для всех информативных участков некоторую последовательность байтов, которая может быть заголовком для всех записей об исследованиях. В результате поиска (см. http://www.swsys.ru/uploaded/image/2019-3/2019-3-dop/5.jpg) удается найти последовательность 0C 51 AB 67 03 00 02 00 и определить число вхождений данной последовательности в файл. Число вхождений соответствует количеству записей об исследованиях в БД (3 934). Поскольку данная последовательность находится в начале каждой записи, будем считать ее заголовочной. Далее проанализируем байты, расположенные между найденными заголовками, то есть байты, образующие запись.
В итоге получен формат хранения бинарных данных результатов исследований, который может быть использован при реализации конвертера. Стоит отметить, что на данных в БД Tomey не было никакой дополнительной защиты, что упростило анализ [10].
Программная реализация конвертера Реализованное в виде конвертера ПО позволяет устанавливать подключение к БД Tomey и считывать всю информацию как с полей таблиц БД, так и из бинарного файла, структура которого была рассмотрена ранее. Имеется также возможность просмотра считанной информации. Весь основной функционал конвертера реализован в главном окне, изображенном на рисунке 4. Использованы такие опции, как выпадающее меню, контекстное меню, кнопки и радио-группы.
- таблица с перечнем исследований; - блок с просмотром графика исследования и подробными сведениями об исследовании; - блок просмотра отладочной информации и переключения вариантов отображения графиков результата исследования. В главном окне имеется возможность просмотра сведений о пациенте, к которому относится текущее исследование. Для этого необходимо нажать на кнопку Show patient info. Разработано также меню экспорта для передачи результатов в формате СSV в другие программы, в которых возможно проведение интеллектуального анализа и диагностики с применением методов искусственного интеллекта, в частности, на основе байесовских сетей доверия и нейронных сетей. Заключение В статье рассмотрена проблема хранения большого количества полезных данных в закрытых форматах, что тормозит разработку приложений (экспертных систем, систем поддержки принятия решений и т.д.), требующих обработки большого количества примеров. В качестве одного из методов решения данной проблемы предложен подход на основе разработки дополнительной БД и конвертера (так называемой обратной разработки БД для за- крытого формата данных) на примере аппарата биофизической диагностики зрения Tomey, позволяющий получить данные в открытом формате для их последующего анализа и диагностирования проблемной ситуации (патоло- гии зрения). Полученные результаты могут быть использованы для обучения нейронных сетей и для проведения аналогичных операций в других прикладных системах (например, для анализа кардиограмм). Работа выполнена при финансовой поддержке РФФИ (проекты №№ 17-07-00553 а, 18-01-00201 а, 18-51-00007 Бел а, 18-29-03088 МК). Литература 1. Cleve A., Gobert M., Meurice L., Maes J., Weber J.H. Understanding database schema evolution: a case study. Sci Comput Program 97, 2015, no. P1, pp. 113–121. DOI: 10.1016/j.scico.2013.11.025. 2. Ma Z., Zhao Z., Yan L. Heterogeneous fuzzy XML data integration based on structural and semantic similarities. Fuzzy Sets and Systems, 2018, vol. 351, pp. 64–89. 3. Vinoth P. and Sankar P. Encoding of coordination complexes with XML. J. Mol. Graphics Modell., 2017, vol. 76, pp. 242–259. DOI: http://dx.doi.org/10.1016/j.jmgm.2017.07.009. 4. Eito-Brun R. Chapter 4 – Databases for XML Data. XML-based Content Management. Chandos Publishing, 2018, pp 117–153. DOI: 10.1016/b978-0-08-100204-9.00004-4. 5. Mata C., Oliver A., Lalande A., Walker P., Martí J. On the use of XML in medical imaging web-based applications. IRBM, 2017, vol. 38, pp. 3–12. DOI: 10.1016/j.irbm.2016.10.001. 6. Eremeev A., Khasiev R., Tcapenko I., Zueva M. The intelligent decision support system for diagnostics of difficult diseases of vision. IJ ICP, 2014, vol. 1, no. 3, pp. 269–279. 7. Еремеев А.П., Ивлиев С.А. Построение онтологии на основе нереляционной базы данных для интеллектуальной системы поддержки принятия решений медицинского назначения // Программные продукты и системы. 2017. № 4. С. 5–14. DOI: 10.15827/0236-235X.030.4.005-014. 8. Панов А.С. Реверсинг и защита программ от взлома. СПб: БХВ-Петербург, 2006. 256 с. 9. Хогланд Г., Мак-Гроу Г. Взлом программного обеспечения: анализ и использование кода; [пер. с англ.]. М.: Вильямс, 2005. 400 с. 10. Altheide C., Carvey H. Chapter 8 – Digital Forensics with Open Source Tools. File Analysis, 2011, pp. 169–210. DOI: 10.1016/B978-1-59749-586-8.00001-7. References
|


| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4629&lang=&lang=&like=1 |
Версия для печати |
| Статья опубликована в выпуске журнала № 3 за 2019 год. [ на стр. 512-517 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Анализ и обработка данных для прогнозирования состояния больных
- Унификация модели представления данных и преобразование форматов на основе нереляционной СУБД Neo4j
- Временной анализ обработки конфликтных транзакций в Oracle Enterprise Manager и Errmanager
- Разработка и программная реализация гибридного алгоритма решения оптимизационных задач автоматизированного проектирования
- Многофункциональный имитатор нейронных сетей
Назад, к списку статей