Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Оценка эффективности методического и алгоритмического обеспечения системы поддержки принятия решений специального назначения
Аннотация:При оценке состояния воздушных и космических радиотехнических объектов управления для принятия решения по устранению информационной перегрузки используются методическое обеспечение и алгоритмы классификации объектов системы поддержки принятия решений АСУ специального назначения. В статье представлен метод оценки эффективности алгоритмического обеспечения системы поддержки принятия решений АСУ специального назначения, основанный на использовании искусственной генерации входных данных, а также данных, представляющих собой совокупность всех возможных значений на основе полного перебора в виде программ-генераторов случайных объектов и случайных областей. При данном подходе, использующем анализ взаимного расположения областей в параметрическом пространстве, представляющих собой каталог эталонных значений, нет необходимости сравнивать параметры объекта с параметрами всех классов из каталога. Находится первое вхождение в область, и далее рассматривается возможность попадания анализируемого объекта в области, имеющие пересечения с областью, в которую объект уже попал. Полученные в статье экспериментальные результаты оценки общей вычислительной трудоемкости системы поддержки принятия решений АСУ специального назначения при классификации объектов с использованием комбинированной методики в среднем в два раза ниже по сравнению с базовым методом классификации. Полученный результат особенно актуален при классификации воздушных и космических радиотехнических объектов управления в условиях интенсивного поступления информации в реальном масштабе времени.
Abstract:To eliminate information overload when assessing the state of air and space radio control objects for decision-making, we use methodological support and classification algorithms of decision support system (DSS) objects of an automated control system (ACS) for special purposes. The paper presents a method for efficiency evaluation of algorithmic support of a special purpose ACS DSS. The method is based on artificial generation of input data, as well as data representing a set of all possible values based on an exhaustive enumeration in the form of generating programs of ran-dom objects and random areas. This approach uses the analysis of the relative location of regions in a parametric space, which is a catalog of reference values. In this approach, there is no need to compare object parameters with the parameters of all catalog classes. After finding the first input into an area, we consider the possibility of getting the analyzed object into those areas that have intersections with the area in which the object has already got. The obtained experimental results of evaluation of a general computing labor intensity of the spe-cial-purpose ACS DSS when classifying the objects using a combined method is, on average, two times lower than the basic classification method. The obtained result is particularly relevant in the classifi-cation of air and space radio engineering control objects under conditions of intensive real-time data entry.
| Авторы: Допира Р.В. (rvdopira@yandex.ru) - НПО РусБИТех, пр-т Калинина, 17, г. Тверь, 170001, Россия (профессор, зав. отделом), г. Тверь, Россия, доктор технических наук, Гетманчук А.В. (getmanshuk@mail.ru) - Таганрогский научно-исследовательский институт связи (заместитель начальника лаборатории), Таганрог, Россия, кандидат технических наук, Потапов А.Н. (potapov_il@mail.ru) - Военный учебно-научный центр Военно-воздушных сил «Военно-воздушная академия им. проф. Н.Е. Жуковского и Ю.А. Гагарина» (доцент, зам. начальника кафедры), Воронеж, Россия, кандидат технических наук, Семин М.В. (potapov_il@mail.ru) - Военный учебно-научный центр Военно-воздушных сил «Военно-воздушная академия им. проф. Н.Е. Жуковского и Ю.А. Гагарина» (начальник лаборатории), Воронеж, Россия, Брежнев Д.Ю. (dimanbreg@mail.ru) - Военная академия воздушно-космической обороны им. Маршала Советского Союза Г.К. Жукова (докторант), Тверь, Россия, кандидат технических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 2742 |
Статья в формате PDF Выпуск в формате PDF (6.72Мб) |
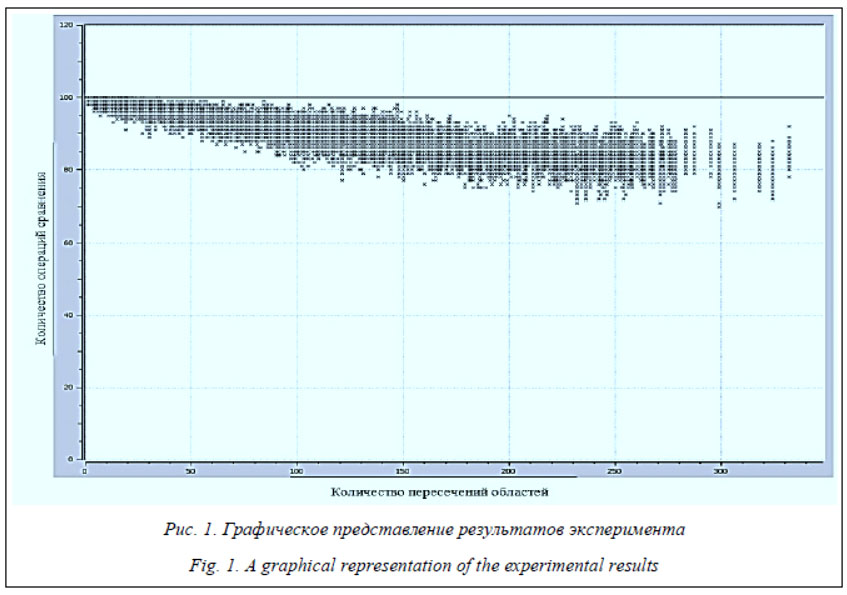
Для обнаружения информационной перегрузки системы необходимо определить признаки, по которым ее можно идентифицировать в системе, и критерии включения алгоритма агрегирования. Такими признаками являются количество данных о воздушной обстановке (отметок от воздушных объектов) и качество информации [1]. Когда количество отметок от воздушных объектов достигнет величины, соизмеримой или превышающей производительность каналов и потребителя, возникает ситуация информационной перегрузки, увеличиваются задержки информации, снижа- ется ее качество (точность и достоверность). Качество информации существенным образом ухудшается и в условиях плотных боевых порядков, когда расстояния между объектами в группе соизмеримы и меньше размеров стробов, используемых при обработке (вторичной и третичной). При этом в один строб попадают несколько отметок от воздушных объектов и происходит формирование большого количества ложных траекторий, создающих предпосылки для информационной перегрузки. Вследствие этого для устранения инфор- мационной перегрузки при оценке состояния воздушных и космических радиотехнических объектов управления для принятия решения используются алгоритмы классификации объектов, реализованные в виде системы поддержки принятия решений (СППР), интегрированной в состав АСУ специального назначения. Поэтому актуальной является оценка методического и алгоритмического обеспечения системы поддержки принятия решений (СППР), интегрированной в состав АСУ специального назначения в условиях информационной перегрузки. В качестве основных задач по оценке методического и алгоритмического обеспечения таких систем были выделены следующие: - исследование эффективности алгоритма предварительного анализа входных данных; - оценка эффективности применения списочного алгоритма представления классификационной матрицы; - оценка влияния сокращения классификационной матрицы на решение задачи классификации; - проверка работоспособности алгоритма анализа информации о новых объектах; - оценка вычислительной трудоемкости методического обеспечения функционирования СППР АСУ специального назначения. На практике задачи классификации объектов решаются в условиях различного рода ограничений на представление исходных данных, а также требований к алгоритмической реализации функциональных возможностей и к вычислительным средствам. Одним из видов ограничений представления исходных данных является сложность определения классов объектов. Неопределенность может заключаться и в отсутствии информации о количестве объектов, подлежащих классификации [2]. В ходе исследований по оценке эффективности алгоритмического обеспечения СППР АСУ специального назначения использованы искусственная генерация входных данных, а также данные, представляющие собой совокупность всех возможных значений на основе полного перебора. Для генерации исходных данных были разработаны программы-генераторы случайных объектов и случайных областей. Интерфейсы данных программ [3] приведены на рисунках (см. http://www.swsys.ru/uploaded/image/2019-2/2019-2-dop/1.jpg и http:// www.swsys.ru/uploaded/image/2019-2/2019-2-dop/ 2.jpg). Программа-генератор случайных объектов позволяет сгенерировать определенное количе- ство объектов классификации, каждый из кото- рых характеризуется четырьмя параметрами – X, Y, K, Z. Параметры генерируются случайным образом в заданном диапазоне значений. Набор из заранее указанного количества сгенерированных объектов записывается в файл в формате, совместимом с форматом файлов объектов, применяемых в программной реализации комбинированного метода. В поле «Количество файлов» можно задать необходимое количество реализаций случайно сгенерированных объектов. При этом файлу присваивается имя в формате ННН.pnt, где ННН – номер реализации. Программа-генератор случайных областей дает возможность сгенерировать определенное количество областей. В каждой области значения параметров X, Y, K, Z являются ее центром, а значения dX, dY, dK, dZ определяют размер области. Каждый параметр генерируется случайным образом в заданном диапазоне значений. В полях dx, dy, dk, dz указываются максимально возможные значения размера области. Таким образом, изменяя параметры минимально и максимально возможных значений параметров областей, а также их размеров, можно варьировать количество пересечений генерируемых областей. Набор из заранее указанного количества сгенерированных областей записывается в файл в формате, совместимом с форматом, применяемым при программной реализации комбинированного метода. Программа-генератор случайных областей при записи данных в файл подсчитывает количество пересечений и присваивает создаваемому файлу имя в формате ННН.rgn, где ННН – количество пересечений областей в файле. За одну генерацию программа может создать до ста файлов областей. Исследование эффективности алгоритма предварительного анализа входных данных Эффективность алгоритма предварительного анализа входных данных определяется зависимостью количества операций сравнения от количества пересечений областей каталога эталонных значений при формировании классификационной матрицы. Стоит отметить, что базовым методом при построении классифи- кационной матрицы для создания классификационного образа объекта осуществляется сравнение параметров анализируемого объекта с параметрами каждого класса, занесенного в каталог методом последовательного перебо- ра [4]. Следовательно, при таком анализе количество операций сравнения будет постоянным и равным произведению количества объектов, участвующих в эксперименте, на количество классов в каталоге эталонных значений. При подходе, использующем анализ взаимного расположения областей в параметрическом пространстве, представляющих собой каталог эталонных значений, нет необходимости сравнивать параметры объекта с параметрами всех классов из каталога. Достаточно найти первое вхождение в область и далее рассмотреть возможность попадания анализируемого объекта лишь в области, имеющие пересечения с областью, в которую объект уже попал [5]. С использованием описанных программ-генераторов случайных объектов и областей для участия в эксперименте были подготовлены следующие данные: - 100 файлов объектов, параметры X, Y, K, Z которых меняются в пределах от 1 до 100; - 281 файл областей, параметры X, Y, K, Z которых меняются в пределах от 1 до 100, а размеры областей варьируются от 2 до 25; количество пересечений областей в файлах варьируется от 1 до 332.
Значение количества операций сравнения, равное 100, является максимальным и говорит о том, что параметры каждого анализируемого объекта сравнивались с параметрами каждой области, участвующей в эксперименте. Прямая линия на графике, соответствующая количеству операций сравнения, равному 100, характеризует наихудший результат работы при составлении классификационной матрицы методом последовательного перебора. График наглядно демонстрирует, что наибольшее количество операций сравнения приходится на наборы данных с наименьшим количеством пересечений областей. С увеличением количества пересечений областей количество операций сравнения уменьшается. Детальный анализ входных данных, участвующих в эксперименте, показал, что реализации наборов объектов содержат большое коли- чество объектов, которые не входят ни в одну область, характеризующую класс объекта. На практике при решении задачи классификации объектов такие неклассифицированные объекты являются либо новыми объектами, информация о которых не занесена в каталог эталонных значений, либо помеховыми, обусловленными сложной внешней обстановкой. Очевидно, что данные объекты значительно влияют на результаты эксперимента, так как для каждого такого объекта проводится сравнение с каждой областью в параметрическом пространстве.
Анализ эффективности применения списочного алгоритма представления классификационной матрицы Целью эксперимента являлось сравнение двух алгоритмов представления и обработки данных при выполнении процедуры последовательного нормирования. Речь идет о матричном и списочном алгоритмах представления и обработки классификационной матрицы. Матричный алгоритм представляет данные, составляющие классификационную матрицу, в виде двумерного массива, списочный – в виде циклически связанных ортогональных списков. Наибольший интерес представляет сокращение времени выполнения для матриц большой размерности (50´50, 100´100). Как правило, на практике объект классификации не может попадать во все классы из каталога эталонных значений (или в большую их часть), отсюда следует вывод о разреженности классификационной матрицы. В связи с этим представляет интерес использование списков для хранения и обработки классификационной матрицы [6]. Рассмотрим реализацию данной задачи на компьютере с использованием примера, в котором с увеличением размерности классификационной матрицы увеличивается разреженность.
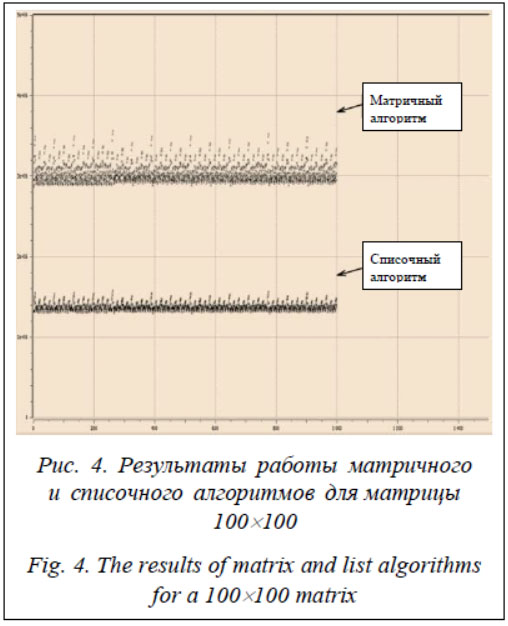
При условиях заполнения классификационной матрицы, описанных в данном эксперименте, применение матриц размерностью от 100´100 до 300´300 показало разницу в быстродействии в среднем в два раза в пользу списочного алгоритма. При малых размерах классификационной матрицы эффективность списочного алгоритма падает. Это обусловлено особенностью организации и взаимодействия с памятью при использовании динамических списков для хранения и обработки данных. Однако падение эффективности применения списочного алгоритма на матрицах малой размерности несущественно по причине относительно малого времени выполнения процедуры последовательного нормирования. С целью более глубокого анализа сравнительных соотношений использования матричного и списочного алгоритмов проведем анализ количества операций без учета взаимодействия с памятью. Для эксперимента была использована программа реализации работы процедуры последовательного нормирования в режиме циклического задания исходных данных. В этом режиме происходит автоматическое задание исходных данных методом циклического перебора всех возможных вариантов заполнения исходной матрицы единичными элементами. Для каждой сгенерированной матрицы производится дополнение ее до квадратной и применяется процедура последовательного нормирования. Количество операций, выполненных в ходе процедуры, запоминается и отмечается точкой на результирующем графике. Для проведения эксперимента была установлена размерность матрицы 5´5, позволяющая получить статистическую оценку путем проведения полного цикла перебора заполнения матрицы единичными элементами. При рассматриваемых условиях без учета взаимодействия с памятью выводы, полученные для матрицы 5´5, можно использовать для матриц большей размерности. Результаты проведенного анализа представлены в виде фрагментов графиков, где отражено количество операций, произведенных при выполнении процедуры последовательного нормирования для матрицы 5´5 с помощью матричного алгоритма (см. http://www. swsys.ru/uploaded/image/2019-2/2019-2-dop/3.jpg) и списочного алгоритма (см. http://www.swsys. ru/uploaded/image/2019-2/2019-2-dop/4.jpg). По горизонтали отражено количество экспериментов, а по вертикали – количество операций. Проведенный эксперимент показал среднее количество операций, затраченных на выполнение процедуры последовательного нормирования с помощью матричного алгоритма, равное 736, тогда как количество операций для списочного алгоритма составило 344. Таким образом, при выполнении процедуры последовательного нормирования количество операций в среднем сократилось в два раза. Это соотношение совпадает с результатом первой части эксперимента.
Среднее значение количества операций для матрицы 100´100 при использовании матричного алгоритма составило 3 093 695, списочного – 1 389 118. Полученные результаты позволяют сделать следующий вывод: алгоритм представления и обработки данных, составляющих классификационную матрицу в виде списков, позволяет сократить вычислительные затраты на выполнение процедуры последовательного нормирования в среднем в два раза. Оценка влияния сокращения классификационной матрицы на решение задачи классификации Целью являлась оценка эффективности от сокращения классификационной матрицы на подготовительном этапе. Эксперимент заключался в сравнении количества операций, затраченных на выполнение процедуры последовательного нормирования применительно к классификационной матрице в неизменном виде, созданной на подготовительном этапе, с количеством операций, затраченных на выполнение данной процедуры применительно к сокращенной классификационной матрице. Сокращенная классификационная матрица представляет собой одну либо несколько матриц, содержащих только взаимозависимые элементы. Для участия в эксперименте из сгенерированного ранее набора входных данных были выбраны четыре файла областей, содержащие по 100 областей каждый. Общее количество пересечений областей в выбранных файлах равно 0, 100, 200 и 300. Для каждого файла областей было сгенерировано по одному файлу объектов с информацией о 90 объектах каждый. Файлы объектов генерировались таким образом, что для каждой связки «файл областей–файл объектов» соблюдаются следующие условия: параметры 90 объектов распределены по отношению к областям так, что 30 объектов не попадают ни в одну область, 30 объектов попадают не более чем в одну область, а оставшиеся 30 объектов попадают в пересечения областей, то есть более чем в одну область. Для файла областей с нулевым количеством пересечений объекты распределились следующим образом: 30 объектов не попали ни в одну область, 60 объектов попали в области. Для каждого соотношения «файл объектов–файл областей» была создана классификационная матрица с помощью программы анализа параметров объектов. На следующем этапе для каждой классификационной матрицы был произведен расчет с помощью программы реализации работы процедуры последовательного нормирования в режиме ввода данных из файла. Далее каждая из классификационных матриц была сокращена с помощью программы анализатора классификационных векторов. В результате сокращения из состава каждой матрицы были выведены объекты, не имеющие взаимозависимых объектов, а оставшиеся объекты были разделены на подмножества взаимозависимых объектов. Для каждого из таких подмножеств была построена классификационная матрица. К каждой новой классификационной подматрице была применена процедура последовательного нормирования. Результатом эксперимента стало количество операций сравнения, проделанных во время применения процедуры последователь- ного нормирования по отношению к исходным матрицам и к подматрицам, созданным в результате сокращения. Эксперимент проводился с использованием двух алгоритмов представления и обработки классификационной матрицы – списочного и матричного. Результаты эксперимента сведены в таблицу. Результаты сокращения классификационной матрицы The results of classification matrix reduction
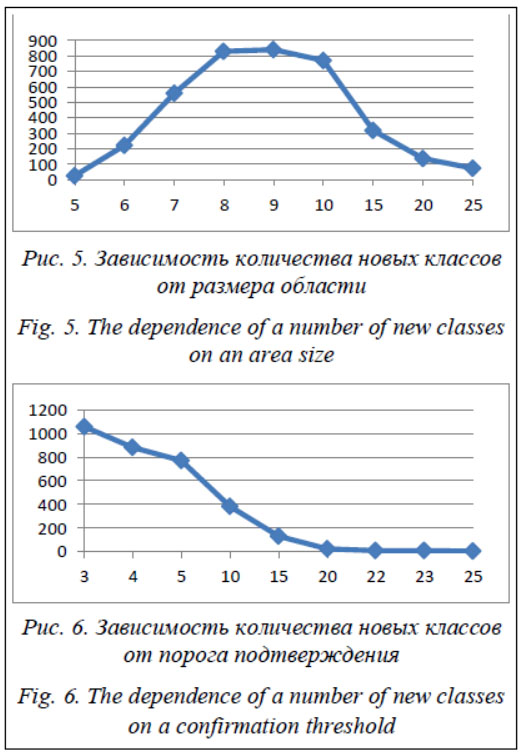
Проведенный эксперимент показал возможность сокращения вычислительной трудоемкости при решении задачи классификации в среднем в два раза. На основании его результатов можно сделать следующий вывод: применение алгоритма сокращения классификационной матрицы на подготовительном этапе позволяет существенно сократить затраты на выполнение процедуры последовательного нормирования. Таким образом, эксперимент показал преимущество сокращенной матрицы по сравнению с исходной по количеству операций сравнения примерно в 2 раза [8]. Так как данный эксперимент проводился с применением и матричного, и списочного алгоритмов представления и обработки классификационной матрицы, можно сделать вывод о сокращении количества операций сравнения при применении списочного алгоритма по сравнению с матричным в 3,45 раза. В приведенных выше результатах эксперимента не используются значения, полученные для файла с нулевым количеством пересечений областей. Этот файл представляет собой исходные данные для определения предельной оценки вычислительной трудоемкости. Результатом применения к данной исходной матрице разработанного алгоритма сокращения классификационной матрицы стала классификационная матрица нулевой размерности. Это очевидно, так как области не имеют пересечений, а следовательно, все объекты будут классифицироваться однозначно. Оценка работоспособности алгоритма анализа информации о новых объектах Для проверки работоспособности алгоритма анализа информации о новых объектах была использована программа анализа параметров объектов в режиме динамического анализа информации о новых объектах. Для динамической подачи данных в программу анализа были подготовлены 100 файлов-объектов. Зависимость количества новых классов от размера области (порог подтверждения по умолчанию равен 5) будет следующей:
Зависимость количества новых классов от порога подтверждения (размер области по умолчанию равен 10):
1. Количество новых классов возрастает в зависимости от размера области, пока он не достигнет пикового значения, после чего количество новых классов уменьшается. Данный эффект объясняется размером параметрического пространства и его отношением к варьируемому размеру области. При превышении варьируемого размера области пикового значения снижение количества новых классов обусловлено увеличением количества пересечений областей [10, 11]. 2. Зависимость количества новых классов от порога подтверждения обратно пропорциональна. Проведенный эксперимент подтверждает недостатки кластерного анализа. Однако, учитывая специфику применения разработанного алгоритма, можно утверждать, что указанные недостатки в данном случае играют положительную роль. На практике при решении задачи классификации объектов варьирование оператором параметров работы вручную позволит адаптировать его к таким реальным условиям АСУ, как погрешность работы измерительной аппаратуры, особенности внешней об- становки и т.д. Оценка вычислительной трудоемкости методического обеспечения функционирования системы Вычислительную трудоемкость базового метода классификации можно представить в следующем обобщенном виде: ТБ = Т1 + Т2 + Т3, (1) где Т1 – вычислительная трудоемкость подготовительного этапа; Т2 – вычислительная трудоемкость процедуры последовательного нормирования; Т3 – вычислительная трудоемкость завершающего этапа [12]. Оценку вычислительной трудоемкости комбинированного метода классификации можно отобразить как ТК = Т1/к1 + Т2/(к2´к3) + Т3, (2) где к1 – параметр, характеризующий статистическую оценку сокращения вычислительной трудоемкости подготовительного этапа; к2 – параметр, характеризующий статистическую оценку сокращения вычислительной трудо- емкости выполнения процедуры последовательного нормирования за счет применения списочного алгоритма формирования классификационной матрицы; к3 – параметр, характеризующий среднюю оценку сокращения вычислительной трудоемкости выполнения про- цедуры последовательного нормирования за счет применения алгоритма сокращения классификационной матрицы. Сравнительную оценку общей вычислительной трудоемкости теперь можно представить следующим образом:
Принимая во внимание то, что Т3 << Т1 и Т3 << Т2, формулу (3) можно упростить:
В работе [9] показано, что к1 ≈ 2, к2 ≈ 2, к3 ≈ 2. В то же время, учитывая приближенность данных оценок, получаем S = 2. Таким образом, общая итоговая сравнительная оценка характеризуется полученным с запасом значением статистической средней оценки, равной 2. В комбинированной методике классификации по сравнению с базовым методом классификации [1, 2] введены новые, разработанные в рамках данной работы алгоритмы обработки данных. Вычислительная трудоемкость этих алгоритмов не превышает 10 % от общей трудоемкости, что практически не влияет на сформулированную итоговую оценку вычислительной трудоемкости. Выполненные исследования по оценке эффективности методического и алгоритмического обеспечения СППР АСУ специального назначения позволили сделать следующие выводы. Исследование эффективности алгоритма предварительного анализа входных данных показало, что на подготовительном этапе работы комбинированной методики классификации количество операций сравнения снижается, по статистической оценке, в среднем в два раза. Анализ эффективности применения списочного алгоритма представления классификационной матрицы показал преимущество списочного алгоритма перед матричным. По статистическим оценкам, эксперимент показал снижение количества операций при применении списочного алгоритма по сравнению с матричным в среднем в 2 раза. При этом снижение реальных временных затрат на реализацию списочного алгоритма пропорционально размерности классификационной матрицы. Применение алгоритма сокращения классификационной матрицы позволяет уменьшить ее размерность и снизить вычислительную трудоемкость при выполнении процедуры после- довательного нормирования в среднем в два раза. Снижение вычислительной трудоемкости варьируется в пределах от максимально необходимой при отсутствии возможности сокращения до полного исключения выполнения процедуры последовательного нормирования в случае вырождения классификационной матрицы. Результаты проведенных экспериментов подтверждают снижение общей вычислительной трудоемкости при классификации объектов с использованием комбинированной методики в среднем в 2 раза по сравнению с базовым методом классификации. Это особенно актуально при решении поставленной задачи в случае интенсивного поступления входных данных в масштабе реального времени. Литература 1. Дикарев В.А. Обработка параметров системы информационного обеспечения авиационных комплексов радиоэлектронной борьбы // Радиотехника. 2001. № 4. С. 59–64. 2. Семин М.В. Метод и алгоритм представления информации для обмена в сложной иерархической автоматизированной системе управления в условиях информационной перегрузки // Журн. СФУ: Техника и технологии. 2016. № 9. С. 470–480. DOI: 10.17516/1999-494X-2016-9-4-470-480. 3. Гетманчук А.В. Алгоритм классификации радиотехнических сигналов по методу Г.В. Шелейховского // Состояние, проблемы и перспективы создания корабельных информационно-управляющих комплексов: сб. докл. науч.-технич. конф. 2013. С. 258–262. 4. Кулаков А.А., Лобода К.П., Шпак В.Ф. Основные принципы параллельной обработки входной информации разнотипными АСУ радиотехнических комплексов // Вопросы специальной радиоэлектроники: Сер. ОВР. Москва–Таганрог, 2013. Вып. 2. С. 15–20. 5. Потапов А.Н., Ищук И.Н. Моделирование систем массового обслуживания – автоматизированных систем управления («МСМО – АСБУ»): свид. о гос. регистр. программы для ЭВМ 2007610584 Рос. Федерация; заявл. 08.12.2006; зарегистр. в Реестре 06.02.2007. 6. Рыбина Г.В. Основы построения интеллектуальных систем. М.: Финансы и статистика, ИНФРА-М, 2010. 432 с. 7. Круг П.Г. Нейронные сети и нейрокомпьютеры. М.: Изд-во МЭИ, 2002. 128 с. 8. Местецкий Л.М. Математические методы распознавания образов. 2016. URL: http://www. ccas.ru/frc/papers/mestetskii04course.pdf (дата обращения: 20.07.2018). 9. Горелик А.Л., Барабаш Ю.Л., Кривоше- ев О.В., Эпштейн С.С. Селекция и распознавание на основе локационной информации. М.: Радио и связь, 1990. 211 с. 10. Jenssen R. An Information Theoretic Approach to Machine Learning. Thesis Univ. of Tromso, Norway, 2005, pp. 44–49. 11. Torkkola K. Feature Extraction by Non-Parametric Mutual Information Maximization. J. of Machine Learning Research, 2003, vol. 3, pp. 24–30. 12. Хайдуков Д.С. Применение кластерного анализа в государственном управлении // Философия математики: актуальные проблемы: тез. II Междунар. конф. М.: МАКС Пресс, 2009. С. 57–69. References
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4593&lang= |
Версия для печати Выпуск в формате PDF (6.72Мб) |
| Статья опубликована в выпуске журнала № 2 за 2019 год. [ на стр. 273-282 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Электронный глоссарий
- О выборе числа процессоров в многопроцессорной вычислительной системе
- Макроэкономическая балансовая модель для стран с элементами переходной экономики
- ДИНАМИКА-2 - программа для решения осесимметричных и плоских задач
- Построение маршрута с максимальной пропускной способностью методом последовательного улучшения оценок
Назад, к списку статей