Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Конструктивный метод обучения искусственных нейронных сетей со взвешенными коэффициентами
Аннотация:В работе предлагается конструктивный метод обучения искусственных нейронных сетей с различными параметрами коррекции для нейронов, добавленных на разных этапах обучения. Данный метод позволяет бороться с попаданием в локальный минимум и при этом контролировать масштаб нейронной сети. Предполагается, что различие в коэффициенте скорости обучения, при котором нейроны, добавленные на более поздних этапах обучения, корректируются интенсивнее нейронов, добавленных на ранних этапах, позволит эффективнее бороться с попаданием в локальный минимум. В работе приводятся статистические данные, полученные на примерах MNIST при помощи предлагаемого метода, стандартного метода градиентного спуска и конструктивного метода обучения. Для проведения численных экспериментов, позволяющих сравнивать рассматриваемые методы, была разработана программа на Python с использованием библиотек numpy и matplotlib. Нейронная сеть является сетью прямого распространения, где входы нейронов связаны со всеми выходами предыдущего слоя. Функция активации для всех нейронов представляет собой экспоненциальную сигмоиду. Обучение производилось методом обратного распространения ошибок. В качестве функции оценки использовалась сумма квадратов расстояний между выходными сигналами и эталонными значениями. В работе подробно описываются условия обучения и приводится график, иллюстрирующий динамику спада значения функции оценки для всех трех методов. Предполагается также, что предлагаемый метод позволит снизить влияние процесса обучения на новом классе данных на эффективность работы нейронной сети на классах, которым сеть обучалась на ранних этапах.
Abstract:The paper proposes a constructive method for teaching artificial neural networks with different correction parameters for neu-rons added at different stages of training. This method allows dealing with local minimization and at the same time controlling a neural network scale. It is assumed that dealing with local minimization might become more effective due to the difference in the learning rate, when the neurons added at later training stages are adjusted more intensively than the neurons added at early stages. The paper presents statistical data obtained in MNIST examples using the proposed method, the standard gradient descent method and the constructive teaching method. There is a Python program that has been developed using the numpy and matplotlib libraries in order to conduct numerical experiments that allow comparing the considered methods. A neural network is a direct distribution network, where the neuron inputs are connected to all the outputs of the previous layer. The activation function for all neurons is an exponential sigmoid. The training has been carried out by the method of back propagation of errors. The sum of squares of distances between output signals and reference values has been used as an evaluation function. The paper describes study conditions in detail and provides a graph illustrating the dynamics of the decline in the evaluation function value for all three methods. It is also assumed that the proposed method will reduce the impact of the learning process on the new data class on the effectiveness of the neural network in the classes that the network has learned at the early stages.
| Авторы: Казаков М.А. (f_wolfgang@mail.ru) - Институт прикладной математики и автоматизации (младший научный сотрудник), Нальчик, Россия | |
| Ключевые слова: метод градиентного спуска, конструктивные методы обучения, искусственные нейронные сети, распознавание образов, машинное обучение |
|
| Keywords: gradient descent method, constructive learning methods, artificial neural networks, pattern recognition, machine learning |
|
| Количество просмотров: 5807 |
Статья в формате PDF Выпуск в формате PDF (6.60Мб) |
При проектировании нейронных сетей в числе важных задач проектирование топологии и оценка оптимального количества нейронов в сети. Существуют методы, которые позволяют произвести расчет оптимального количества нейронов в зависимости от поставленной задачи и выбранной топологии, однако сложность такой оценки существенно возрастает с ростом глубины нейронной сети. Другая проблема связана с обучением нейронных сетей на выборке нового класса данных. В этом случае есть риск ухудшения качества работы нейронной сети на данных из предыдущих классов. Часто, когда трудно заранее оценить сложность необходимой структуры искусственной нейронной сети, обучаемой по методу обратного распространения, сначала обучают сеть с заведомо избыточной структурой связей между нейронами, которая позволила бы успешно обучить нейронную сеть для решения задачи, а затем применяют процедуру прореживания, в основе которой также лежит тот или иной градиентный метод. Одним из эффективных методов решения задачи оценки количества нейронов является конструктивный метод обучения, при котором, как правило, обучение начинается с небольшой группы нейронов. Далее в нейронную сеть добавляются дополнительные нейроны с целью наращивания структуры обучаемой нейронной сети. Эта новая группа обучается, чтобы скорректировать ошибки, допускаемые первой группой нейронов. Преимуществами такого метода явля- ются адаптивность и гибкость, позволяющие менять структуру и масштаб нейронной сети непосредственно в процессе обучения, а также компактность искусственной нейронной сети. Однако оценка необходимого количества добавляемых нейронов на каждом этапе обучения и их топологическое размещение вызывают свои трудности. Существуют различные точки зрения на технологию искусственных нейронных сетей. Часто их называют коннекционистскими системами, акцентируя внимание на связях между процессорными элементами, адаптивными системами вследствие способности к адаптации в зависимости от целей, параллельными распределенными системами, учитывая особенности способа организации и обработки информации между процессорными элементами. В целом же эти сети обладают всеми перечисленными свойствами [1]. Постановка задачи Для обеспечения устойчивости качества работы нейронной сети по отношению к обучению на новых классах данных предлагается конструктивный метод обучения, при котором нейроны, добавленные непосредственно перед текущей эпохой обучения, принимают на себя основную нагрузку обучения на новом классе. Это достигается за счет коррекции алгоритма обучения, при котором параметры интенсивности обучения для старых нейронов снижаются, в то время как новые нейроны обучаются интенсивно. Такой метод обеспечивает высокую пластичность обученной сети за счет новых неспециализированных нейронов и при этом сохраняет эффективность работы нейронной сети на данных предыдущих классов, на которых была обучена нейронная сеть. Теоретические предпосылки Метод обратного распространения ошибок является одним из самых эффективных методов обучения нейронных сетей. Кроме того, этот метод хорошо интегрируется с другими методами, что открывает широкие возможности для исследования и совершенствования методов машинного обучения. Одной из характерных особенностей, которая проявляется в процессе градиентного спуска, является застревание в локальном минимуме. Существует ряд методов, помогающих бороться с этим явлением [2–4]. При этом выход из локального минимума не страхует от возможности очередного попадания в другой локальный минимум. Конструктивный метод обучения позволяет бороться с этим явлением. Известно, что у взрослого человека активное формирование новых нейронов происходит на протяжении всей жизни [5, 6]. Они формируются из стволовых клеток и участвуют в обеспечении когнитивных способностей. В частности, образовавшиеся нейроны участвуют в процессе обучения активнее старых, и можно сделать вывод, что принимают основную нагрузку, обеспечивая тем самым высокую пластичность, вероятно, оберегая обученные нейроны от потери навыков [7]. Вовлечение новых нейронов в процесс обучения является ключевой идеей конструктивного метода обучения искусственных нейронных сетей. Процедуры обучения, учитывающие подобную специфику работы нейронов, могут улучшить качество обучения искусственных нейронных сетей. При разбиении обучения на этапы, когда на начальном этапе присутствуют лишь часть классов и относительно небольшое количество нейронов, предоставляется возможность проведения градиентного спуска на гораздо меньшем числе измерений (число переменных, от которых зависит функция оценки, равно количеству параметров сети – числу всех весов и смещений). Предполагается, что конструктивный метод обучения, при котором нейроны, добавленные непосредственно перед текущей эпохой обучения, будет лучше справляться с проблемой попадания в локальные минимумы. Построение программы для испытательных экспериментов Для проведения численных экспериментов, позволяющих сравнивать рассматриваемые методы, была разработана программа на Python с использованием библиотек numpy и matplotlib. Для экспериментов вы- брана классическая задача распознавания рукописных чисел. В качестве тренировочной и тестовой выборок использовалась БД MNIST. Исходные данные были представлены в виде 20 изображений (10 для тренировочной выборки и 10 для тестовой). Каждое изображение тренировочной выборки, соответствующее определенной цифре, содержит около 6 000 уникальных экземпляров, представляющих собой изображения 28´28 пикселей. Тестовая выборка содержит около 1 000 уникальных экземпляров для каждой цифры, отличных от экземпляров тренировочной выборки. Для тестирования использовалась модель нейронной сети прямого распространения, где вход нейронов связан со всеми выходами предыдущего слоя. Функция активации для всех нейронов представляет собой экспоненциальную сигмоиду: Обучение производилось методом обратного распространения ошибок. В качестве функции оценки использовалась сумма квадратов расстояний между выходными сигналами и эталонными значениями: Нейрон выдает на выходе значение в интервале (0, 1). Каждый выходной нейрон соответствует одной из распознаваемых цифр. Результатом распознания нейронной сети будет цифра, соответствующая выходному нейрону с наибольшим значением выходного сигнала. Поэтому количество выходных нейронов в точности совпадает с количеством распознаваемых классов. Например, если на данном этапе обучения используются пять цифр, то выходных нейронов будет тоже пять. Количество нейронов первого слоя и скрытых слоев, а также количество слоев могут быть произвольными. На каждом шаге обучения на вход нейронной сети поступают данные изображения одного экземпляра 28´28 пикселей, стохастически выбираемого из всего множества тренировочных примеров. Предварительно множество изображений препарируется в пригодный для нейронной сети тип данных. Множество значений пикселей одного экземпляра записывается в одномерный массив из 784 элементов и преобразуется в набор данных в интервале (–0,3, 0,7). Первый слой нейрона получает данные в виде такого массива, значения которого характеризуют яркость соответствующего пикселя. Первым делом создается нейронная сеть заданной топологии (количество слоев и нейронов в каждом слое). Веса и смещения устанавливаются случайным образом. Далее есть возможность загрузить значения весов из сохраненного ранее файла или же приступить непосредственно к процедуре обучения. При обучении можно осуществить произвольное количество эпох, на каждой из которых менять значения α и скорость обучения. В результате обучения визуализируется динамика изменения функции оценки. Можно протестировать обученную нейронную сеть или же сохранить ее параметры в файл.
Вычислительные эксперименты
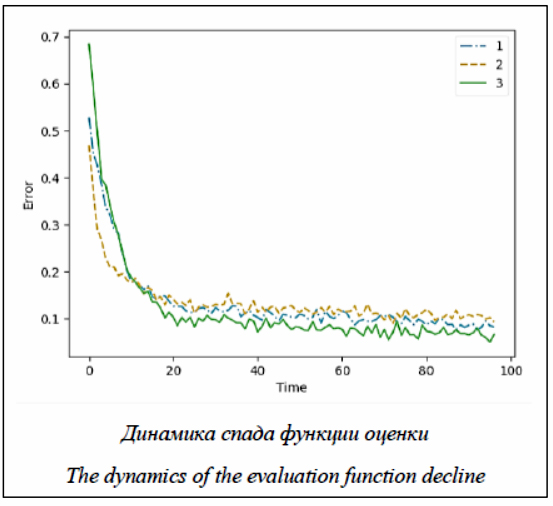
Во всех испытаниях строилась нейронная сеть, состоящая из трех слоев, α = 0,05, общее число циклов обучения равно 200 000. В качестве результата использовалось значение эффективности работы сети – доля распознаваемых цифр из всего множества и динамика изменения функции оценки в процессе обучения. Метод 1. Стандартный метод градиентного спуска. Первый слой нейронной сети содержит 30 нейронов, второй – 20, третий – 10. Проводятся 4 этапа обучения по всем выборкам: 1) 200 циклов обучения с коэффициентом скорос- ти 4; 2) 1 800 циклов с коэффициентом 3; 3) 18 000 циклов с коэффициентом 2; 4) 180 000 с коэффициентом 1. Метод 2. Конструктивный метод обучения. Создается сеть, содержащая 15 нейронов первого слоя, 10 второго и 5 выходного. Обучение проводится по выборкам, соответствующим цифрам 0, 1, 2, 3, 4: 1) 100 циклов с коэффициентом скорости 4; 2) 900 циклов с коэффициентом скорости 3; 3) количество нейронов каждого слоя удваивается; 4) 100 циклов обучения с коэффициентом скорос- ти 4; 5) 900 циклов с коэффициентом 3; 6) 18 000 циклов с коэффициентом 2; 7) 180 000 циклов с коэффициентом 1. Метод 3. Конструктивный метод обучения с избирательной скоростью обучения. Алгоритм обучения аналогичен предыдущему, за исключением пунктов 4 и 5. В данном случае указанный коэффициент скорости применяется только к новым нейронам, в то время как старые нейроны обучаются с коэффициентом, существенно ниже (x0,01). Таким образом, все три коэффициента приводятся к некоему единообразию, позволяющему сравнить их между собой. В графике, иллюстрирующем динамику спада функции оценки, приводятся результаты, соответствующие последним двум пунктам обучения, которые идентичны для каждого эксперимента. На рисунке приводятся соответствующие графики. После проведения серии идентичных испытаний и усреднения результатов эффективности распознавания были получены следующие результаты: первый метод дал 96,22 %, второй – 96,41 %, третий – 96,57 %.
Выводы На основе полученных результатов можно сделать вывод, что предложенный метод дает незначительное увеличение эффективности распознавания нейронной сети. График динамики функции оценки показал, что скорость спада выше при стандартном методе градиентного спуска, однако при дальнейшем обучении в предложенном методе значение функции ошибки становится меньше. Работа выполнена при поддержке РФФИ, грант № 18-01-00050-а. Литература 1. Шибзухов З.М. Конструктивные методы обучения SP-нейронных сетей. М.: Наука, 2006. 159 с. 2. Atakulreka1 A., Sutivong D. Avoiding local minima in feedforward neural networks by simultaneous learning. Proc. Australasian Joint Conf. on Artificial Intelligence, 2007, pp. 100–109. 3. Burse K., Manoria M., Kirar V.P.S. Improved back propagation algorithm to avoid local minima in multiplicative neuron model. IJECE, 2010, vol. 4, no. 12, pp. 1776–1779. 4. Ruder Sebastian. An overview of gradient descent optimization algorithms. 2016. URL: http://ruder.io/optimizing-gradient-descent/index.html (дата обращения: 02.08.2018). 5. Gould E., Beylin A., Tanapat P., Reeves A., Shors T.J. Learning enhances adult neurogenesis in the hippocampal formation. Nature Neuroscience, 1999, vol. 3, no. 2, pp. 260–265. 6. Cameron H.A., Glover L.R. Adult neurogenesis: beyond learning and memory. Annual Review of Psychology. 2015, vol. 1, no. 66, pp. 53–81. DOI: http://dx.doi.org/10.1146/annurev-psych-010814-015006. 7. Vivar C., Potter M.C., Choi J., Lee J., Stringer T.P., Calla- wy E.M., Gage F.H., Suh H., van Praag H. Monosynaptic inputs to new neurons in the dentate gyrus. Nature Communications, 2012, vol. 1038, no. 3, art. 1107. 8. Тимофеев А.В., Косовская Т.М. Нейросетевые методы логического описания и распознавания сложных образов // Тр. СПИИРАН. 2013. Вып. 27. C. 144–155. 9. Yann LeCun, Bengio Y., and Hinton G. Deep learning. Nature, 2015, vol. 521, pp. 436–444. DOI: 10:1038/nature/4539. 10. Sutskever I., Martens J., Dahl G., Hinton G. On the importance of initialization and momentum in deep learning. J. of Machine Learning Research, 2013, vol. 28, no. 3, pp. 1139–1147. References
|
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4561 |
Версия для печати Выпуск в формате PDF (6.60Мб) |
| Статья опубликована в выпуске журнала № 1 за 2019 год. [ на стр. 088-091 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Автоматизированное детектирование и классификация объектов в транспортном потоке на спутниковых снимках города
- Адаптация модели нейронной сети LSTM для решения комплексной задачи распознавания образов
- Метод идентификации технического состояния радиотехнических средств с применением технологий искусственных нейронных сетей
- Параллельные вычисления при реализации web-инструментария распознавания образов на основе методов прецедентов
- Разработка модели имитации значений технологических параметров гидроагрегата для тренажера оперативного персонала
Назад, к списку статей