Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Способы представления текстовой информации при автоматизированном рубрицировании коротких текстовых документов
Аннотация:Электронные сообщения граждан (жалобы, обращения, предложения и т.д.) с точки зрения возможности их автоматизированной обработки обладают рядом специфических особенностей: в значительной части случаев небольшой объем документа, что затрудняет его статистический анализ; отсутствие структуризации, что усложняет процедуры извлечения информации; наличие большого количества грамматических и синтаксических ошибок, что обусловливает необходимость реализации нескольких дополнительных этапов обработки; нестационарность тезауруса (состава и важности слов), зависящего от выхода новых нормативных документов, выступлений должностных лиц и политических деятелей и т.д., что вызывает необходимость использования процедур динамической классификации рубрик. В статье описываются этапы автоматизированного анализа и методы формализации текстовых документов. Предлагается метод рубрицирования, который использует результаты морфологического и синтаксического этапов с модифицированной лингвистической разметкой текстовых документов. В качестве синтаксического парcера рассматриваются современные программные продукты MaltParser и LinkGrammar, которые строят деревья зависимостей для всех предложений в документе. Приводятся стандартные лингвистические разметки MaltParser и LinkGrammar применительно к коротким текстовым документам, а также модификация разметки LinkGrammar для использования их рубрицирования. В процессе использования известных программных продуктов для проведения дополнительных этапов анализа придется столкнуться с проблемой разнообразия лингвистических разметок. Например, большинство синтаксических парсеров на выходе представляет каждое предложение текста в виде деревьев зависимостей, которые описывают лингвистической разметкой. Лингвистическую разметку для дальнейшей классификации и назначения весовых коэффициентов необходимо модифицировать, тем самым увеличивая размерность метрики. Описывается разработанный метод рубрицирования, который учитывает экспертную оценку важности слов для каждой рубрики, а также синтаксическую роль слов в предложениях. Приведена диаграмма процесса автоматизированного рубрицирования жалоб и предложений в разработанной системе анализа. Описан эксперимент, который подтверждает целесообразность использования синтаксических парсеров в подобных системах, что приводит к увеличению точности рубрицирования. Даны рекомендации по улучшению точности разработанного метода и использованию аппарата теории нечетких множеств и методов когнитивного моделирования для разрешения проблемы нестационарности тезауруса систем, которые зависят от выхода нормативных документов и выступлений должностных лиц.
Abstract:The paper shows that citizens’ electronic messages (complaints, appeals, proposals, etc.) in terms of the possibility of their automated processing have a number of specific features. They are: usually a small document capacity, which makes it difficult to analyze it statistically, a lack of structuring, which complicates extracting information, a big number of grammatical and syntactic errors that lead to implementing several additional processing steps, thesaurus non-stationarity (composition and importance of words), which depends on the issuance of new normative documents, officials’ and politicians’ speeches, etc. All this leads to the necessity of using procedures for headings dynamic classification. The paper describes the stages of automated analysis and methods for formalizing text documents. It also proposes a developed rubrication method that uses the results of the morphological and syntactic stages with modified linguistic markup of text documents. The syntactic parser is MaltParser or LinkGrammar software that build dependency trees for all sentences in a document. The paper shows standard linguistic markings of MaltParser and LinkGrammar applied to short text documents, as well as a modification of the LinkGrammar markup to use for rubrication. Using known software for additional stages of analysis shows the problem of the diversity of linguistic markings. For example, most of the syntactic parsers at the output represent each sentence as dependency trees, which are described by linguistic markup. For further classification and assignment of weighting factors, linguistic markup should be modified, so it will increase the dimension of the metric. The developed method of rubrication takes into account the expert evaluation of the importance of words for each rubric, as well as the syntactic role of words in sentences. The paper shows a diagram of the process of automated rubrication of complaints and proposals in the developed analysis system. It also describes an experiment that confirms the expediency of using syntactic parsers in such systems, which leads to increasing accuracy of rubrication. There are recommendations to improve the accuracy of the developed method and use the theory of fuzzy sets and methods of cognitive modeling in order to solve the problem of thesaurus nonstationarity in the systems that depend on the issue of normative documents and officials’ speeches.
| Авторы: Козлов П.Ю. (originaldod@gmail.com) - Смоленский филиал Национального исследовательского университета МЭИ (аспирант), Смоленск, Россия | |
| Ключевые слова: методы формализации текстовых документов., динамичный тезаурус, автоматизированный анализ текстов |
|
| Keywords: methods for formalizing text documents, dynamic thesaurus, analysis automated analysis of texts |
|
| Количество просмотров: 9075 |
Статья в формате PDF Выпуск в формате PDF (29.80Мб) |
Одним из основных направлений государственной политики в Российской Федерации является повышение степени открытости органов государственной и муниципальных властей различных уровней, в том числе на основе организации их виртуального взаимодействия с населением. В результате происходит процесс постоянного совершенствования интернет-порталов органов исполнительной и законодательной власти, где каждый гражданин может в электронном виде подать жалобу, обращение или предложение. Число подобных электронных контактов непрерывно растет. Например, в Смоленской области за 2016 год поступило 9 936 электронных обращений, что составляет 30 % от всего числа жалоб [1]. За 2015 год в администрацию Санкт-Петербурга поступило 134 387 документов (из них 38 000 в электронном виде), за 2016 год – 117 274 документа (из них 54 473 в электронном виде) [2]. С учетом жестко регламентированных сроков направления ответа возникает необходимость обеспечения автоматизированной обработки ука- занных запросов с целью их рубрицирования для повышения оперативности взаимодействия с профильными структурными подразделениями администраций. Электронные сообщения граждан (жалобы, обращения, предложения и т.д.) с точки зрения возможности их автоматизированной обработки имеют ряд специфических особенностей: - небольшой объем большинства документов, что затрудняет его статистический анализ; - отсутствие структуризации, что усложняет процедуры извлечения информации; - наличие большого количества грамматических и синтаксических ошибок, обусловливающее необходимость реализации нескольких дополнительных этапов обработки; - нестационарность тезауруса (состава и важности слов), который зависит от выхода новых нормативных документов, выступлений должностных лиц и политических деятелей и т.д., приводящая к необходимости использования процедур динами- ческой классификации рубрик. Очевидно, что указанные особенности рассмат- риваемых текстовых документов накладывают определенные ограничения на алгоритмы применения морфологического, синтаксического и семантического анализов, а также на соответствующие им процедуры формализации для автоматизированной обработки текстов, в том числе в рамках виртуальных систем информационного обеспечения различных региональных социально-экономических процессов (см, например, [3, 4]).
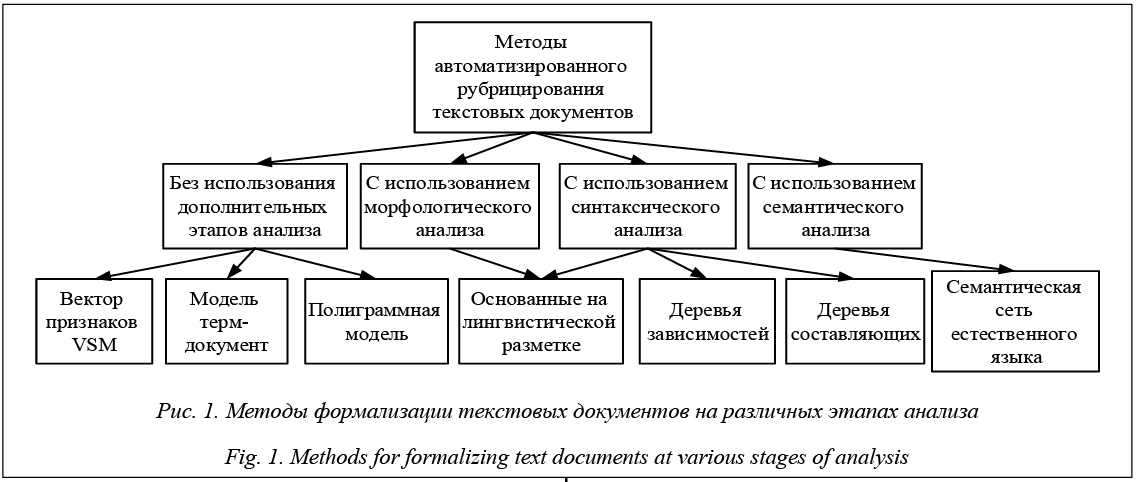
В методах, где не используются дополнительные этапы анализа, достаточно представить текстовый документ в виде моделей VSM, терм-документ или полиграммной. При использовании морфологического или синтаксического анализа необходимо текстовый документ приводить к виду лингвистической разметки. Результаты синтаксического анализа также можно представить в виде деревьев зависимостей и деревьев составляющих. Семантический этап анализа на выходе формирует семантическую сеть естественного языка. Рассмотрим подробнее способы формализации текстов с точки зрения возможности последующей автоматизированной обработки документов указанного выше вида. При использовании вектора признаков VSM (VectorSpaceModel) текстовый документ представляется в виде вектора, каждая координата которого соответствует частоте встречаемости одного из слов всей коллекции в этом тексте. Объединение всех таких векторов в единую таблицу приводит нас к прямоугольной матрице размером n×p, где p – количество слов в коллекции (размерность пространства), а n – число документов [5]. Применение полиграммной модели со степенью n и основанием M предполагает представление текстового документа в виде вектора {fi}, i = 1, ..., Mn, где fi – частота встречаемости i-й n-граммы в тексте, которая является последовательностью подряд идущих n символов вида a1, …, an-1, an, причем символы ai принадлежат алфавиту, размер которого совпадает с M [6]. Терм-документ представляет модель, в рамках которой текст описывается лексическим вектором {τi}, i = 1, …, Nw, где τi – важность (информационный вес) термина wi в документе; Nw – полное количество терминов в документной базе (словаре). Вес термина, отсутствующего в документе, принимается равным 0 [6]. Если в процессе анализа задействованы синтаксические и семантические этапы, для них необходимо текстовую информацию представлять в другом виде для сохранения результатов предыдущих этапов, а также для записи новых характеристик лингвистических единиц. Для представления текстовых документов с синтаксическими характеристиками чаще всего используется лингвистическая разметка, предполагающая задание информации о лингвистических единицах непосредственно в тексте в форме разметки на специальном языке (например SGML или XML). Использование специальной разметки для представления лингвистической информации в документе достаточно удобно для задач обработки текстов на естественном языке. Данный подход позволяет анализировать результаты обработки текстов пользователем или разработчиком, игнорировать не относящуюся к задаче разметку и использовать стандартные программные инструменты. Основной проблемой применения специальной разметки являются трудности при представлении сложных и пересекающихся структур, которые могут возникнуть вследствие неоднозначности анализа текста на одном из этапов обработки [7].
Главное отличие синтаксических деревьев зависимостей заключается в отсутствии обозначающих составляющие нетерминальных вершин, а синтаксические связи имеют пометки, обозначающие их тип. Типы связей определяют грамматические функции слов в предложении или общие семантические отношения между словами [8].
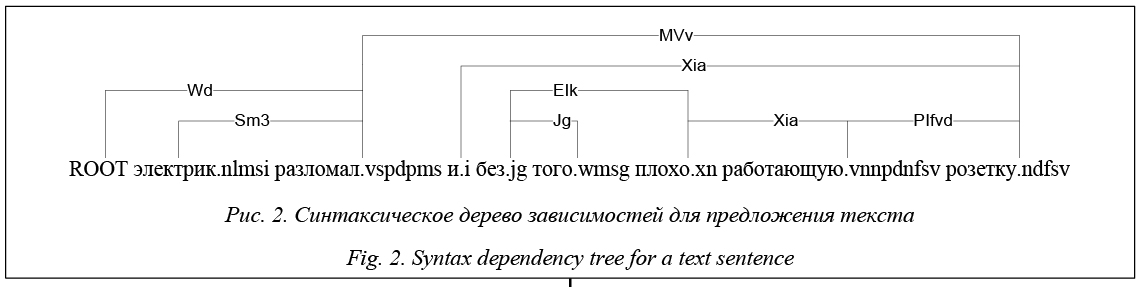
Конечная смысловая структура текста представляется основной алгебраической системой вида Mt = áOt, At, Lt, Ht, В связи с особенностью рассматриваемых тестовых документов, поступающих на интернет-порталы органов исполнительной и законодательной власти, целесообразно использовать все перечисленные способы формализации текстов на отдельных этапах их автоматизированной обработки. Например, на этапах, предшествующих морфологическому анализу, можно использовать модель терм-документ, так как данный вид формализации очень удобен для подготовки документа к морфологическому анализу. На этапах морфологического и синтаксического анализов рационально применять также лингвистическую разметку с использованием весовых коэффициентов и экспертной информации [9], при этом необходимо учитывать нестационарность тезауруса (в том числе изменение весовых коэффициентов важности отдельных слов и их сочетаний), который зависит от выхода новых нормативных документов, выступлений должностных лиц и политических деятелей и т.д. В процессе использования известных программных продуктов для проведения дополнительных этапов анализа придется столкнуться с проблемой разнообразия лингвистических разметок. Например, большинство синтаксических парсеров на выходе представляет каждое предложение текста в виде деревьев зависимостей, которые описывают лингвистической разметкой. Лингвистическую разметку для дальнейшей классификации и назначения весовых коэффициентов необходимо модифицировать, тем самым увеличивая размерность метрики. Например, при использовании синтаксического парсера LinkGrammar при анализе предложения «Состояние труб водоснабжения очень плохое» получаем лингвистическую разметку: «("LEFT-WALL" RW:6:RIGHT-WALL Wd:1:состояние.ndnsi)(Wd:0:LEFT-WALL "состояние.ndnsi" Mg:2:труб.ndfpg)(Mg:1:состояние.ndnsi "труб.ndfpg" Mg:3:водоснабжения.ndnsg)(Mg:2:труб.ndfpg "водоснабжения.ndnsg")("[очень]")("[плохое]")(RW:0:LEFT-WALL "RIGHT-WALL"))».Дерево зависимостей данного предложения выглядит следующим образом:
Синтаксический парсер MalpParser вместо подобной XML-разметки использует построчное разбиение предложений на слова, которым приписываются характеристики в порядке, описанном в XML-файле конфигурации, который выглядит следующим образом:
В этом случае для использования сторонних систем анализа необходимо написать программы преобразования форматов представления текстовой информации, а также модифицировать предложенные форматы для внесения дополнительных характеристик, необходимых для модифицируемых методов классификации текстовых документов. Например, для жалобы «Налоговая инспекция продолжает уже два месяца кошмарить нашу фирму» синтаксический парсер LinkGrammar представит его в лингвистической разметке вида:
С точки зрения синтаксиса важными словами являются «налоговая», «инспекция» и «бизнес» – они будут помечены как синтаксически важные, и им присвоится специальный коэффициент. Также в системе из-за динамичности тезауруса, который связан с нормативными документами и с выступлениями должностных лиц, будет учитываться слово «кошмарить», которое относится к проблемам малого бизнеса, так как именно в данном контексте его использовал один из руководителей страны. Учитывая все названные замечания, модифицированная лингвистическая разметка будет выглядеть следующим образом:
В разметке указаны общие слова – com, ред- кие – rare и уникальные – uni, а также стоят пометки важности – imp или n_imp, и, если слова относятся к нормативным высказываниям, normative. Усовершенствовав разметку, можно применять метод рубрицирования, изложенный в [9].
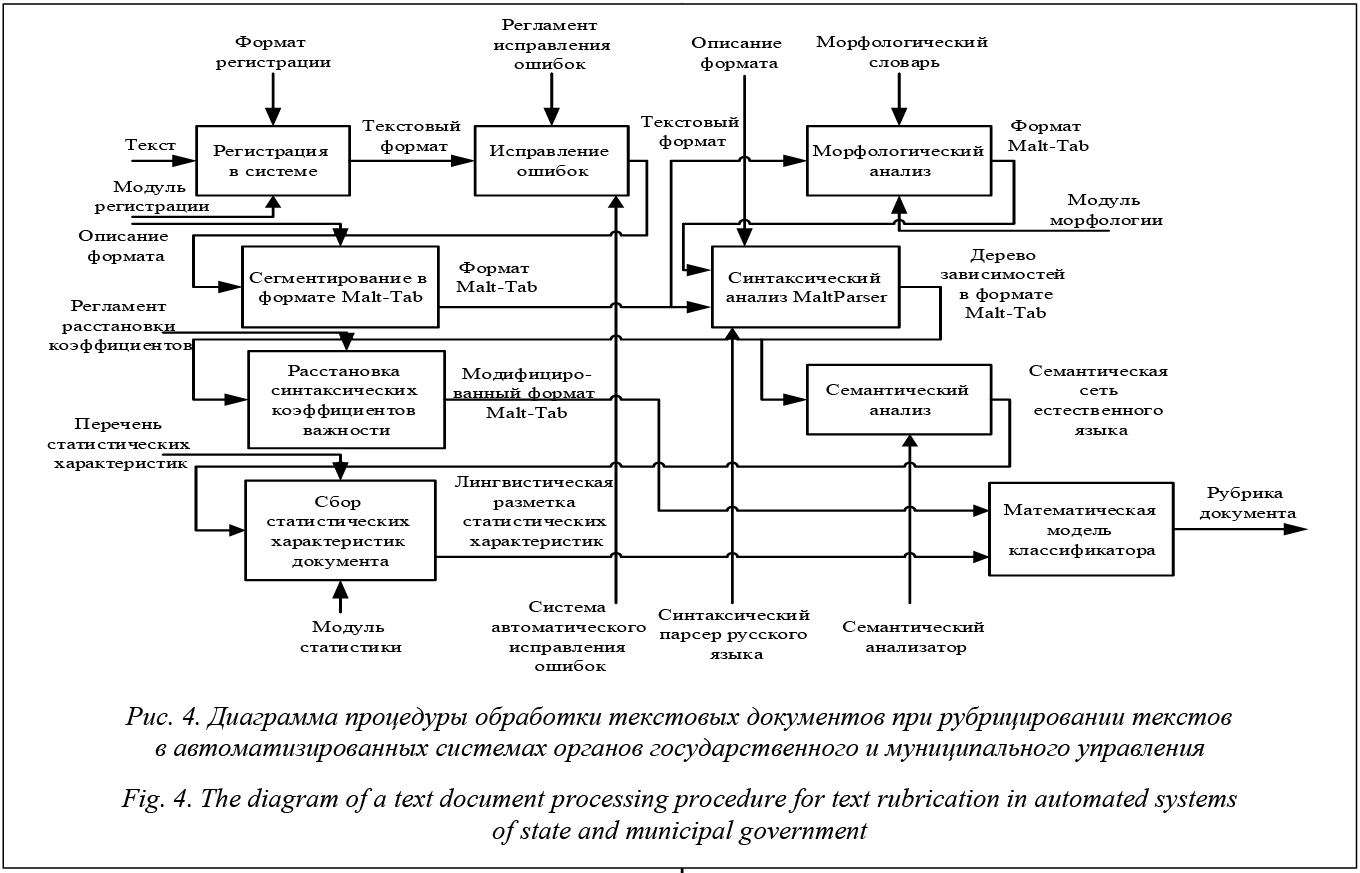
Для проверки целесообразности использования синтаксических коэффициентов важности слов в предложении был проведен эксперимент, описанный в работе [10], но с дополнительным использованием синтаксических парсеров. В эксперименте были рубрицированы 100 документов по 9 об- ластям, при этом среднее количество слов в до- кументе составляло 28. Анализ включал этапы сегментации, морфологического анализа, сбора статистических данных, рубрицирование (классификация) текстового документа. При учете синтаксических коэффициентов важности дополнительно добавлялись разметки весовых коэффициентов синтаксической важности слов и сбора статистических данных. Под сегментацией понималось разбиение текстового документа на абзацы, предложения и слова; под морфологическим анализом – нахождение лингвистических характеристик всем словам, таких как начальная форма слова, часть слова, род, число, падеж, форма и т.д.; под сбором статистических данных – подсчет частотных характеристик всех слов; под синтаксическим анали- зом – построение дерева зависимостей для всех предложений текстового документа; под разметкой весовых коэффициентов синтаксической важности слов – назначение коэффициентов исходя из синтаксической значимости слов в предложениях; под рубрицированием (классификацией) – подсчет степени принадлежности текстового документа ко всем предметным областям по математической модели метода, описанного выше, и нахождение максимума. Программирование этапов анализа и преобразования форматов представления текстовых документов осуществлялось на языке Micro- soft Visual C# под управлением ОС Microsoft Windows 8.1. БД хранятся в сетевом экземпляре Microsoft SQL Server 2008.При проведении эксперимента параметры ве- сового метода были следующие: уникальным словам приписывается вес 50, неуникальным – 10, общим – 1, порог отбора общих слов – 80 %, а синтаксические коэффициенты важности: подлежа- щее – 10, сказуемое – 10, остальные – 1.Наблюдаемое увеличение точности автоматизированного рубрицирования до 84 % подтвердило целесообразность использования синтаксических парсеров для анализа. Предполагается, что более тщательный подбор коэффициентов синтаксической важности слов и проверка синтаксических связок слов могут повысить точность приведенной на рисунке 1 процедуры. Очевидно, что при нестационарности тезауруса целесообразно для определения степени важности отдельных слов и их сочетаний применять экспертные процедуры и интеллектуальные системы, в том числе с использованием аппарата теории нечетких множеств [11–13], а также методы когнитивного моделирования [14–16]. Литература 1. Аналитическая справка о работе Аппарата администрации Смоленской области с обращениями граждан. URL: https://www.admin-smolensk.ru/obrascheniya_grazhdan/obzori_ obrascheniy/news_16096.html (дата обращения: 20.03.2017). 2. Обзор обращений граждан Администрации города Санкт-Петербурга. URL: http://gov.spb.ru/gov/obrasheniya-grazhdan/otchet-obrasheniya/?page=1 html (дата обращения: 20.03.2017). 3. Дли М.И., Какатунова Т.В. О перспективах создания виртуальных технопарковых структур // Инновации. 2008. № 2. С. 118–120. 4. Дли М.И., Какатунова Т.В. Общая процедура взаимо- действия элементов инновационной среды региона // Журнал правовых и экономических исследований. 2009. № 3. С. 60–63. 5. Учителев Н.В. Классификация текстовой информации с помощью SVM // Информационные технологии и системы. 2013. № 1. С. 335–340. 6. Андреев А.М., Березкин Д.В., Морозов В.В., Сима- ков К.В. Автоматическая классификация текстовых документов с использованием нейросетевых алгоритмов и семантического анализа // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: тр. V Всерос. науч. конф. (RCDL'2003). СПб, 2003. С. 140–149. 7. Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика. М.: Изд-во МИЭМ, 2011. 272 с. 8. Шелманов А.О. Исследование методов автоматического анализа текстов и разработка интегрированной системы семантико-синтаксического анализа: дисс. … канд. технич. наук. М., 2015. 210 с. 9. Козлов П.Ю. Методы автоматизированного анализа коротких неструктурированных текстовых документов // Программные продукты и системы. 2017. № 1. С. 100–105. 10. Козлов П.Ю. Сравнение частотного и весового алгоритмов автоматического анализа документов // Науч. обозрение. 2015. № 14. С. 245–250. 11. Круглов В.В., Дли М.И., Голунов Р.Ю. Нечеткая логика и искусственные нейронные сети. М.: Физматлит, 2001. 12. Круглов В.В., Дли М.И. Интеллектуальные информационные системы // Компьютерная поддержка систем нечеткой логики и нечеткого вывода. М.: Физматлит, 2002. 256 с. 13. Федулов А.С. Устойчивая операция аккумулирования нечетких чисел // Нейрокомпьютеры: разработка, применение. 2007. № 1. С. 27–39. 14. Дли М.И., Какатунова Т.В. Нечеткие когнитивные модели региональных инновационных систем // Интеграл. 2011. № 2. С. 16–18. 15. Borisov V.V., Fedulov A.S. Generalized rule-based fuzzy cognitive maps: structure and dynamics model. LNCS, 2004, vol. 3316, pp. 918–922. 16. Дли М.И., Какатунова Т.В. Функциональные когнитивные карты для моделирования региональных инновационных процессов // Инновационная деятельность. 2011. № 3. С. 75–83. References
|
 , RHñ, называемой семантической сетью естественного языка, где Ot – множество концептов, выделенных в тексте; At – множество ребер, связывающих концепты из Ot; LtÌ L – множество семантических отношений, выявленных в тексте и используемых в качестве меток ребер из At; Ht – множество классов, связывающих концепты из Ot по классовой семантической совместимости их наборов значений семанти- ческих характеристик;
, RHñ, называемой семантической сетью естественного языка, где Ot – множество концептов, выделенных в тексте; At – множество ребер, связывающих концепты из Ot; LtÌ L – множество семантических отношений, выявленных в тексте и используемых в качестве меток ребер из At; Ht – множество классов, связывающих концепты из Ot по классовой семантической совместимости их наборов значений семанти- ческих характеристик;  – отношение инцидентности на Ot ´ At ´ N, где N – подмножество идентификаторов участников отношений модели M2;
– отношение инцидентности на Ot ´ At ´ N, где N – подмножество идентификаторов участников отношений модели M2;  – отношение инцидентности на At ´ Lt ; Rh – отношение классовой принадлежности на Ot ´ Ht. Такая довольно громоздкая структура получается после нестрогого отождествления понятий из семантических образов отдельных предложений, в процессе которого образуются концепты [8].
– отношение инцидентности на At ´ Lt ; Rh – отношение классовой принадлежности на Ot ´ Ht. Такая довольно громоздкая структура получается после нестрогого отождествления понятий из семантических образов отдельных предложений, в процессе которого образуются концепты [8].



| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4367&lang= |
Статья в формате PDF Выпуск в формате PDF (29.80Мб) |
| Статья опубликована в выпуске журнала № 4 за 2017 год. [ на стр. 678-683 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: