Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Сравнение производительности отечественных и импортных микропроцессоров
Аннотация:В статье сравнивается производительность трех различных процессоров архитектуры MIPS – RM7000, XLP316 и 1890ВМ8Я и описываются их архитектурные особенности. Для оценки производительности процессоров при помощи языков программирования C и Assembler строится и применяется методика тестирования, включающая в себя три последовательных этапа. На первом этапе тестирования измеряется время выполнения отдельных процессорных инструкций при условии, что эти инструкции и необходимые для их работы данные лежат в кэш-памяти первого уровня. Инструкции делятся на несколько групп, для представителей каждой из которых в статье приводятся результаты. На втором этапе измеряется эффективность работы со структурой кэш-памяти первого и второго уровней. В данной статье приводятся только результаты измерений времени обращения в кэш-память второго уровня и в основную память. На третьем этапе сравниваются полученные измерения с теоретическими оценками, построенными на основе результатов первых двух этапов тестирования. Для этого используются синтетические тесты производительности. Достоинством методики является независимость результатов измерений от используемого компилятора и операционной системы. Все измерения производятся в тактах процессора средствами специальных регистров сопроцессора.
Abstract:This article provides performance comparison for three different MIPS processors (RM7000, XLP316 and 1890VM8YA) and describes their architecture details. To compare processor performance, the testing technique is developed and implemented using C and Assembler. The technique consists of three consecutive stages. At the first stage the authors measure processor instructions execution time providing that both instructions and data required are already stored in a primary cache. The instructions are divided into several groups. There are the results for members of each group. Primary and secondary cache efficiency is benchmarked on the second stage. The article provides the results for secondary cache and RAM access time only. The third stage uses synthetic performance tests. The obtained results are compared with theoretical estimations based on the results of the first two stages. The advantage of the proposed technique is in its independence from compiler and operating system specified. All measurements are carried out in clock cycles using special purpose coprocessor registers.
| Авторы: Байков Н.Д. (nknikita@niisi.ras.ru) - Федеральный научный центр Научно-исследовательский институт системных исследований РАН (ФНЦ НИИСИ РАН) (младший научный сотрудник), Москва, Россия, Годунов А.Н. (nkag@niisi.ras.ru) - Федеральный научный центр Научно-исследовательский институт системных исследований РАН (ФНЦ НИИСИ РАН) (зав. отделом), Москва, Россия, кандидат физико-математических наук | |
| Ключевые слова: микропроцессор, производительность, mips, тестирование |
|
| Keywords: microprocessor, productivity, mips, testing |
|
| Количество просмотров: 10718 |
Статья в формате PDF Выпуск в формате PDF (21.91Мб) Скачать обложку в формате PDF (0.59Мб) |
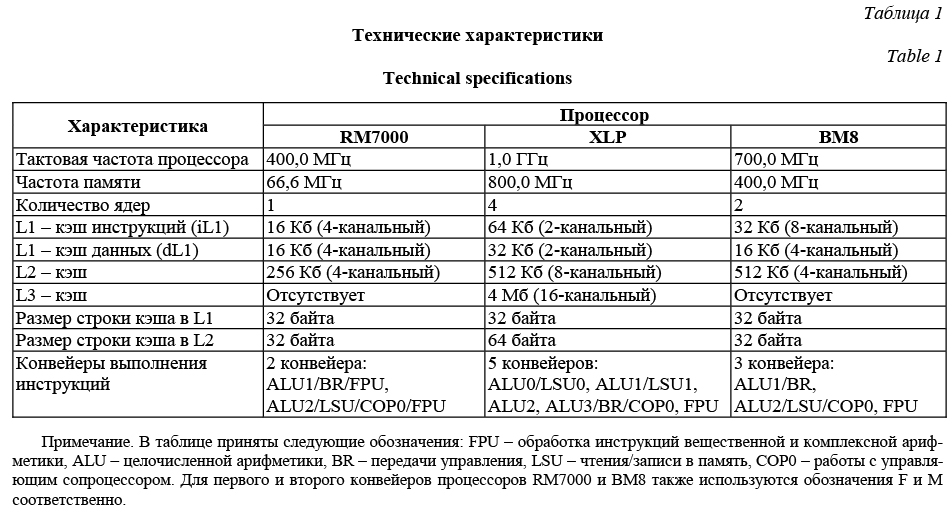
В статье сравнивается производительность процессоров архитектуры MIPS [1] – RM7000 [2], XLP316 (далее – XLP) [3] и экспериментальной версии процессора 1890ВМ8Я (далее – ВМ8) [4]. Основной целью тестирования является выявление особенностей архитектуры, оказывающих влияние на производительность процессоров, а также классов задач, на которых процессоры показывают наилучшую производительность. Результаты тестирования содержат информацию о времени выполнения как отдельных процессорных инструкций, так и некоторых модельных задач. Предлагаемая методика тестирования имеет следующие особенности: - все измерения проводились в тактах процессора с целью получить характеристику производительности, которая не зависит от тактовой частоты; - было изучено влияние кэш-памяти первого и второго уровней на производительность; - все тесты задействовали только одно ядро процессора; - при разработке использовались языки программирования Assembler и C; для их трансляции в машинный код – один и тот же компилятор на всех трех процессорах. Многие тесты производительности (Whetsto- ne [5], Dhrystone [6] и др.) реализованы при помощи языков программирования высокого уровня. Как следствие, на результаты измерений влияют и оптимизирующие возможности компилятора. В данной статье производительность процессоров и влияние компилятора на нее изучаются отдельно друг от друга. Каждый из тестируемых процессоров имеет уникальную и достаточно сложную архитектуру, и, как следствие, состояния этих процессоров в каж- дый момент времени определяются большим количеством различных параметров, осуществить полный учет которых достаточно трудно. В данной статье рассматривается упрощенная модель, согласно которой состояние процессора определяется содержимым кэш-памяти процессора и последовательностью исполняемых им инструкций. Технические характеристики Основные параметры изучаемых процессоров приведены в таблице 1. Для всех трех процессоров функциональность ALU зависит от конвейера, на котором этот блок находится. Например, операции целочисленного умножения и деления выполняются только на F-конвейере для процессоров RM7000 и ВМ8 и только на ALU2 для процессора XLP. На процессоре RM7000 инструкции вещественной арифметики не вынесены на отдельный конвейер и обрабатываются F- и M-конвейерами. Методика тестирования Тестирование процессоров проводилось в три этапа. На первом этапе измерялось время выполнения процессорных инструкций при условии, что сами инструкции и все необходимые для работы данные уже находятся в соответствующих кэшах процессоров. Тестирование охватывало четыре группы инструкций: целочисленная арифметика, вещественная арифметика, передачи управления, чтение/запись в память. В статье приводятся результаты измерений для нескольких представителей каждой из указанных групп.
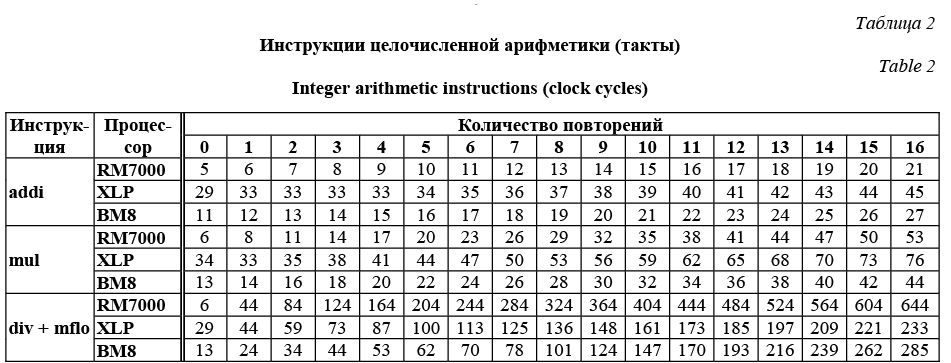
На третьем этапе сравнивалась производительность процессоров на следующих модельных задачах: функция копирования данных, метод Рунге–Кутты, метод Гаусса. Для автоматизации процесса тестирования с помощью языков программирования Assembler и C была построена тестовая система. В ее функции входили подготовка начального состояния процессора для каждого теста, а также непосредственное измерение характеристик производительности процессоров. Перед началом тестирования содержимое всех кэшей очищалось, в том числе и содержимое кэша третьего уровня на процессоре XLP. Инструкции тестовой системы размещались в кэше инструкций первого уровня и оставались там до окончания тестирования всех функций. Для инструкций каждой тестируемой функции и данных, с которыми она работает, независимо моделировались следующие ситуации: присутствие инструкций/данных в соответствующем кэше первого уровня, присутствие только в кэше второго уровня, отсутствие в кэшах всех уровней. После окончания тестирования каждой функции ее инструкции и данные удалялись из кэшей. Таким образом, в кэшах процессора одновременно могли находиться только инструкции тестовой системы и одной из тестируемых функций, а также данные, необходимые для ее работы. Кэши изучаемых процессоров организованы так, что в них можно одновременно разместить указанные инструкции и данные вне зависимости от адресов, которые они имеют в памяти, не вызывая при этом вытеснения строк (количества кэш-каналов доста- точно, чтобы при возникновении конфликтов между адресами функций или данных можно было разместить их в разных секциях соответствующего кэша). Загрузка инструкций тестовой системы и тестируемых функций в кэши происходила при помощи вызовов этих функций, а загрузка данных – при помощи операций чтения. Для исключения данных из кэшей использовалась инструкция cache. Проведенные операции позволили минимизировать влияние тестовой системы на результаты измерений и предотвратить вытеснение строк из кэшей в связи с их переполнением. В качестве средств измерения использовались регистры процессора Performance Counter Control и Performance Counter, которые позволяют регистрировать различные события во время работы программы, такие как такты процессора, промахи в кэш-память процессора и т.д. При каждом выполнении тестируемой функции тестовая система опрашивала счетчик до и после ее выполнения и сохраняла разницу этих значений. Анализ полученных результатов производился в зависимости от этапа тестирования. Для проведения первых двух этапов конструировались семейства однотипных тестовых функций. Функции одного семейства последовательно повторяли заданную инструкцию или набор инструкций заданное количество раз и отличались друг от друга только количеством повторений. Кроме указанных инструкций, функции также могли содержать какие-либо дополнительные инструкции, которые требуются для корректной работы теста, например, первоначальной инициализации используемых регистров. В частности, для каждого такого семейства конструировалась пустая тестовая функция, которая состояла только из дополнительных инструкций и характеризовала величину накладных расходов. Оценка интересующих авторов факторов проводилась на основе се- рии измерений для функций, принадлежащих одному семейству. На третьем этапе тестирования такие семейства уже не требовались и измерения проводились непосредственно для программных реализаций модельных задач. Важной технической деталью является то, что процессор XLP поддерживает внеочередное исполнение инструкций. Каждый из его конвейеров оснащен очередью, вмещающей в себя до 16 инструкций. Если в данный момент времени нет свободного конвейера, который может выполнить текущую инструкцию, она помещается в очередь к одному из них, а процессор переходит к обработке следующей инструкции. Если при этом окажется, что есть свободный конвейер для выполнения этой инструкции и она не зависит по данным от уже находящихся в очередях инструкций, процессор немедленно приступит к ее обработке, тогда как предыдущая инструкция еще будет находиться в очереди. Эта архитектурная особенность XLP позволяет избежать простоя всех конвейеров из-за высокой нагрузки на один из них. Так как указанная особенность распространяется и на конвейер, ответственный за работу с управляющим сопроцессором, повторный опрос счетчика после возврата из тестируемой функции может произойти раньше, чем будет завершена обработка всех инструкций теста, которые на данный момент находятся в очереди другого конвейера, то есть результат измерений будет некорректным. Эту проблему удается решить. Заметим, что только один из конвейеров процессора XLP способен обрабатывать инструкции работы с управляющим сопроцессором, то есть эти инструкции сохраняют порядок относительно друг друга. Добавляя загрузку результата работы тестируемой функции на один из временных регистров управляющего сопроцессора перед повторным опросом счетчика, формируем зависимость по данным между инструкциями и гарантируем, что опрос произойдет после вычисления этого результата. Наконец, для корректности итоговых результатов прерывания во время работы каждого теста были запрещены. Результаты измерений Рассмотрим процессорные инструкции. Прежде чем перейти к результатам измерений, необходимо уточнить, что будем понимать под длительностью выполнения инструкций. Тестируемые процессоры используют конвейерный способ обработки инструкций. Полное время прохождения инструкцией всех стадий конвейера не дает точного представления о производительности процессора, поскольку не учитывает параллелизм в выполнении инструкций. Более точно оценить вклад каждой от- дельной инструкции в общее время выполнения программы позволяют следующие величины [7]: - время освобождения блока выполнения кон- вейера (Repeat Rate), то есть количество тактов от момента начала стадии выполнения инструкции до момента, когда конвейер сможет начать эту стадию для следующей инструкции; - задержка результата выполнения инструкции (Latency), то есть количество тактов от момента начала стадии выполнения инструкции до момента, когда для следующих инструкций будет доступен результат выполнения. Также существует понятие пропускной способности конвейера (Pipeline Throughput). На наборе из n инструкций это отношение количества инструкций n к полному времени их прохождения по конвейеру. Стадия выполнения для инструкции может быть начата на подходящем свободном конвейере только в том случае, если доступны результаты всех инструкций, от которых она зависит. В противном случае возникает простой конвейера до получения необходимых данных. Для многих инструкций задержка результата оказывается больше времени освобождения блока выполнения. Поскольку при выполнении реальных задач нет никаких гарантий того, что результат работы таких инструкций не понадобится уже в следующей инструкции, для оценки производительности процессоров на первом этапе тестирования больше внимания уделяется измерению задержки результата. Для этого достаточно сделать инструкции тестируемых функций зависимыми. Описание результатов начнем с инструкций целочисленной арифметики. Приведем результаты для трех инструкций из этой группы: сложение с постоянным значением addi, умножение mul и целочисленное деление при помощи пары инструкций div и mflo. Инструкция mflo считывает результат целочисленного деления div из специального LO-регистра, создавая зависимость по данным между соседними инструкциями div. Для других операций, например, выполняемых при помощи инструкций andi, add, sub и т.д., тестирование проводится аналогично. Структура всех тестов одинакова и состоит из этапа инициализации, последовательности повторяющихся операций и возврата управления. Приведем пример исходного кода: li v0, C1; // Инициализация v0 addi v0, v0, C2; … // Повторяем вышестоящую инструкцию нужное … // количество раз вручную, не используя … // передачи управления jr ra; nop;
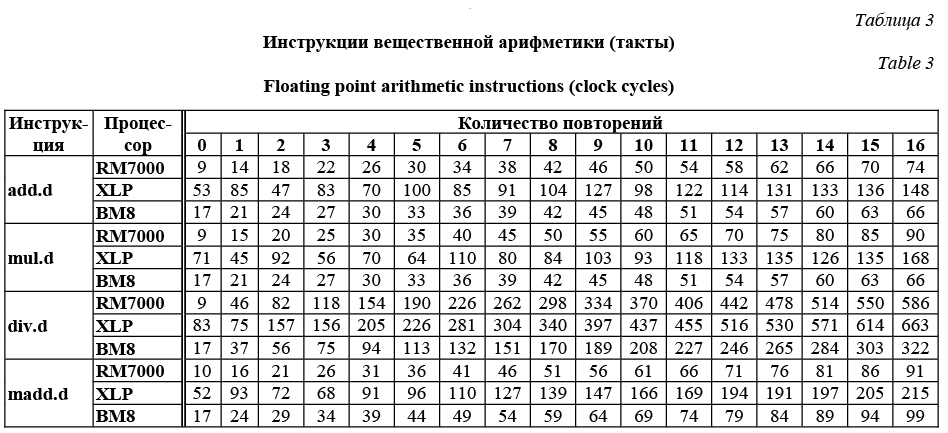
На процессоре RM7000 зависимость количества тактов от количества операций линейна для инструкции addi, а для инструкции mul и пары инструкций div, mflo почти линейна, за исключением переходов от пустых функций. Действительно, с увеличением на единицу количества повторений addi длительность теста возрастает ровно на 1 такт во всех случаях. Для инструкции mul и пары инструкций div, mflo при переходе от пустых функций длительность теста возрастает на 2 и 38 тактов процессора соответственно, а при дальнейшем увеличении количества операций – на 3 и 40 тактов за каждое повторение соответствующей операции. Отличие первого приращения от остальных указывает на то, что освобождение блока выполнения от mul и mflo происходит быстрее, чем будет доступен их результат (для возврата управления их результат не требуется). Также было обнаружено, что на процессоре RM7000 задержка получения результата инструкции mul зависит от размера аргументов. Для 16-битных аргументов она равнялась 3 тактам, а для 32-битных – 4 тактам. На других процессорах подобной зависимости не наблюдалось. Результаты процессоров ВМ8 и XLP аналогичны результатам процессора RM7000. Укажем лишь на некоторые особенности. На процессоре ВМ8 полученные значения задержки результата для инструкций addi и mul составили 1 и 2 такта соответственно, а задержка результата выполнения пары инструкций div и mflo варьировалась от 8 до 23 тактов. На процессоре XLP полученные результаты проявляют линейную зависимость лишь после нескольких повторений операции. Для инструкций addi и mul наблюдаемые значения задержки составили 1 и 3 такта. Задержка на паре div и mflo, как и в случае процессора ВМ8, не была фиксированной и требовала от 11 до 15 тактов. Большая величина накладных расходов (то есть время выполнения пу- стой функции) на процессоре XLP по сравнению с остальными процессорами частично объясняется влиянием на результат дополнительных операций с управляющим сопроцессором для предотвращения преждевременного опроса счетчика событий. Таким образом, на операциях целочисленного сложения и деления лучшую производительность в тактах процессора показал процессор XLP, а на умножении – ВМ8. Аналогичные тесты были проведены для инструкций сопроцессора вещественной арифметики. Тесты отличались только способом инициализации исходных регистров. Рассмотрим результаты для четырех видов инструкций, работающих с числами формата double: сложение add.d, умножение mul.d, деление div.d и смешанная операция умножения и сложения madd.d.
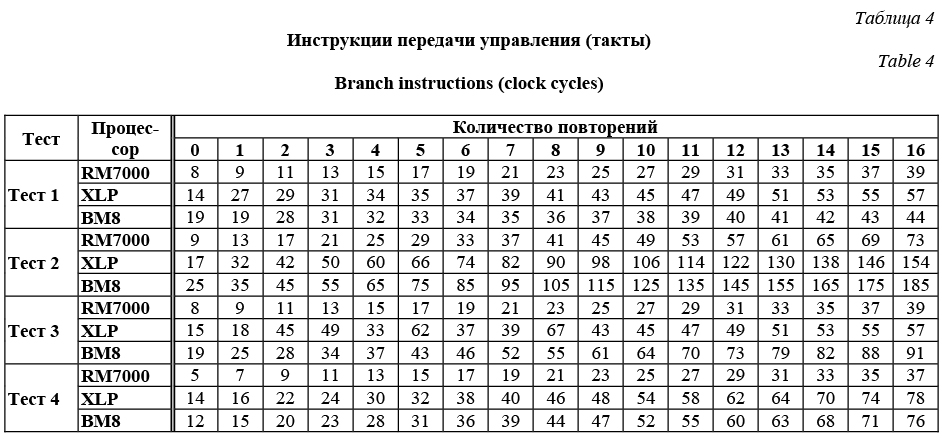
Оценивать увеличение длительности теста при увеличении количества повторений инструкций на единицу на процессоре XLP будем в среднем. Получаем приближенные значения 5,9, 6,1, 36,2 и 10,2 такта для инструкций add.d, mul.d, div.d и madd.d, соответственно. На процессорах RM7000 и ВМ8 искомые величины могут быть вычислены точно. Не считая пустых функций, длительности тестов на указанных процессорах линейно зависят от количества инструкций. На процессоре RM7000 длительность теста увеличивается на 4, 5, 36 и 5 тактов за каждую инструкцию add.d, mul.d, div.d и madd.d соответственно, а на процессоре ВМ8 – на 3, 3, 19 и 5 тактов. Для тестируемых инструкций вещественной арифметики освобождение блока выполнения конвейера происходит не позже, чем будет доступен результат работы инструкций, поэтому полученные значения совпадают с временем задержки результата этих инструкций. Таким образом, наименьшие значения задержки результата для группы инструкций вещественной арифметики наблюдались на процессоре ВМ8. В отличие от тестов целочисленной арифметики переход от пустых функций длится дольше всех последующих переходов. Причиной оказываются инструкции dmtc1, для которых задержка результата выполнения больше времени освобождения блока выполнения конвейера. В ходе отдельных тестов было получено, что для освобождения блока выполнения конвейера от инструкции dmtc1 на процессорах RM7000 и ВМ8 требуется 1 такт, а задержка результата равна 2 и 3 тактам соответственно. Перейдем к тестированию инструкций передачи управления. Эффективность выполнения этих инструкций существенно зависит от используемых алгоритмов предсказания переходов и может меняться в зависимости от ситуации. Оценка эффективности проводилась в четырех тестах: простой цикл, вложенные передачи управления, перекрест- ные передачи управления и безусловные передачи управления.
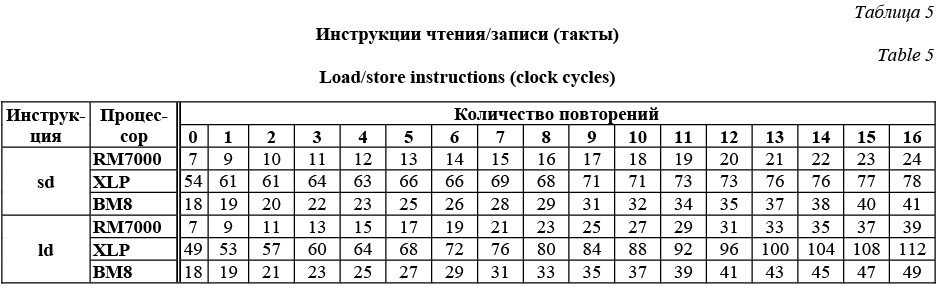
Наконец, перейдем к изучению инструкций чтения/записи. Тест инструкций чтения требовал дополнительной подготовки. Буфер, из которого считывались данные, заполнялся двойными словами, каждое из которых содержало адрес следующего. Это позволило сформировать зависимость по данным между инструкциями, которая вынуждает процессор XLP выполнять инструкции последовательно.
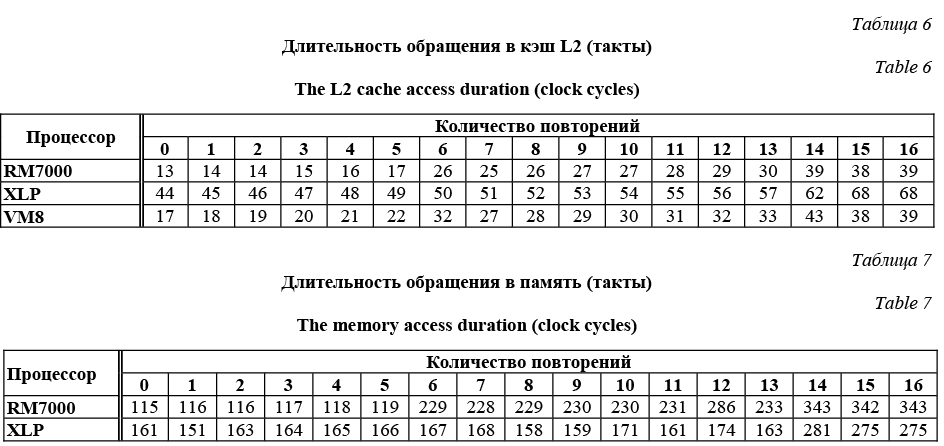
На процессоре XLP была получена наибольшая величина накладных расходов. На инструкциях записи происходит скачок длительности теста при переходе от пустой функции к функции с одной инструкцией записи и далее в среднем длительность теста возрастает приблизительно на 1 такт процессора за каждую дополнительную инструкцию записи. На инструкциях чтения прирост длитель- ности теста составил 4 такта за каждую инструкцию. Перейдем к результатам процессоров RM7000 и ВМ8. На инструкциях чтения процессоры показали одинаковый результат: длительность теста возрастает на 2 такта процессора за каждую инструкцию чтения. При тестировании инструкций записи было обнаружено, что результаты RM7000 и ВМ8 уже не совпадают. На каждую инструкцию записи процессору RM7000 требуется ровно один такт, тогда как на процессоре ВМ8 зависимость количества тактов от количества инструкций становится нелинейной и в среднем требует более одного такта процессора. Часто при выполнении инструкции чтения соседние инструкции не зависят от ее результата. Производительность в этом случае определяется временем освобождения блока выполнения конвейера. Измерения показали, что на это требуется 1 такт на всех трех процессорах. Также отметим, что на процессоре XLP имеются сразу два конвейера, способных обрабатывать инструкции чтения/записи, что также позволяет ускорить работу процессора. Время обращения к кэш-памяти Хотя влияние кэш-памяти на производительность складывается из многих факторов, ограничимся лишь измерением времени обращения к ней. Влияние других факторов (например, политики кэширования) изучаться не будет. Также отметим, что измеряемая величина не является только харак- теристикой производительности процессора, так как зависит также от используемой системы памяти. В процессе тестирования существенных разли- чий в длительности получения данных или инструкций из памяти обнаружено не было. Поэтому рассмотрим только результаты тестов для случая работы с инструкциями. Для измерений использовалось семейство тестовых функций из первого этапа тестирования для инструкции addi. При их работе чтение данных из памяти не происходит. Были рассмотрены два случая. 1. Инструкций нет в кэше инструкций первого уровня iL1, но они есть в кэше второго уровня L2. 2. Инструкций нет в кэшах iL1 и L2. В случае процессора XLP инструкции также отсутствуют в кэше L3. Поскольку инструкции и данные попадают в кэши строками, количество обращений из кэша iL1 в кэш L2 определяется количеством строк кэша iL1, требуемых для хранения функции. Тестовые функции задавались так, чтобы начало каждой из них соответствовало началу строки в кэшах первого и второго уровней. В таком случае количество требуемых для хранения функции строк кэша однозначно определяется по количеству инструкций в ней. Размер строки кэша первого уровня у всех трех процессоров одинаков – 32 байта (см. табл. 1). Поскольку на хранение одной инструкции выделяются 4 байта, в одной строке кэша помещаются ровно 8 инструкций, следовательно, для получения количества строк кэша необходимо округлить вверх результат деления на 8 количества инструкций, из которого состоит тестируемая функция.
Перейдем ко второму случаю. Его результаты приведены в таблице 7. Для процессора ВМ8 результаты отсутствуют, так как оценить длительность обращения в память в рамках используемой модели на данном процессоре не удалось. Анализ результатов проводится аналогично первому случаю. Отметим только, что на процессоре XLP размер строки кэша L2 равен 64 байтам. Как видно из таблицы 7, скачки в длительностях тестов на процессорах RM7000 и XLP происходят одновременно с увеличением количества строк кэша L2, требуемых для хранения функции. Размер этих скачков приблизительно равен 110–120 тактам для обоих процессоров. В процессе тестирования для процессора XLP также были выявлены две важные особенности, которые позволяют существенно ускорить его работу при промахах в кэш-память процессора. Было обнаружено, что процессор XLP способен обрабатывать параллельно промахи в кэш-память для различных инструкций из очереди выполнения при условии, что известны адреса данных в памяти. Если требуется, например, последовательно прочитать данные из буфера, указанная особенность позволяет добиться существенного прироста к производительности. Также было обнаружено, что при выполнении инструкций запись обращений в память не происходит. Вместо этого процессор XLP помещает записываемые данные в специальную очередь на запись, из которой они впоследствии попадают в основную память. При этом запись данных в очередь осуществляется почти так же быстро, как если бы данные находились в кэше данных первого уровня. Модельные задачи Представим результаты измерений для трех модельных задач: функция копирования данных, метод Рунге–Кутты и метод Гаусса [8]. Начнем с задачи копирования данных из одного буфера в другой (назовем их Src и Dst) при помощи функции memcpy, поддерживаемой стандартами POSIX и C99. Адреса буферов в памяти были выровнены на границу строк кэшей первого и второго уровней, а кэши данных очищены перед началом тестирования. Существует несколько реализаций функции копирования (memcpy); в данном случае использовалась реализация, которая перемещает 4 двойных слова из буфера Src в буфер Dst за одну итерацию основного цикла. Инструкции этой функции были предварительно размещены в кэше инструкций первого уровня. Рассматривались не перекрывающиеся в памяти буферы размером от 1 Кб до 8 Мб в следующих случаях: - данные обоих буферов отсутствуют в кэшах; - буфер Src предварительно прочитан (то есть, если размер кэша больше размера буфера, весь буфер находится в этом кэше после прочтения); - буфер Dst предварительно прочитан; - оба буфера были прочитаны перед началом теста.
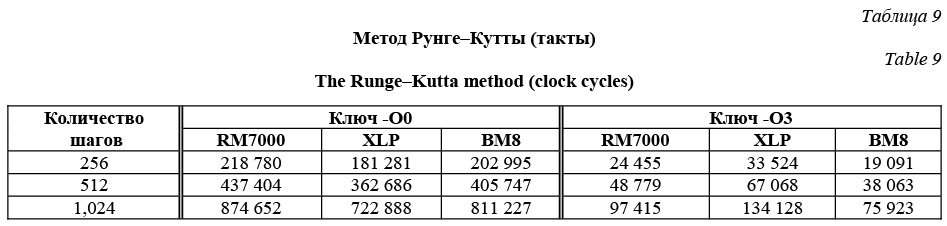
Изучим также результаты процессора RM7000 для случая, когда оба буфера находятся в кэше данных первого уровня. В таком случае инструкции записи и независимые инструкции чтения, как показало тестирование на первом этапе, должны выполняться за 1 такт процессора. Для передачи управления требуются 2 такта. Учитывая, что передачи управления и инструкции целочисленной арифметики могут быть выданы на выполнение одновременно с инструкциями чтения/записи, получаем, что копирование 4 двойных слов можно осуществить за 9 тактов. Следовательно, на копирование 1 Кб требуется 288 тактов. Соответствующий результат измерений из таблицы 8 равен 289 тактам, то есть практически совпадает с предложенной оценкой. Скачки в измерениях для процессоров XLP и ВМ8, как и в случае процессора RM7000, объясняются переполнением какого-либо из кэшей. Из данных таблицы 8 следует, что процессор ВМ8 в большинстве случаев показал большую производительность, чем процессор RM7000, но лучшие результаты в этом тесте были получены при тестировании процессора XLP, что особенно заметно при копировании буферов большого размера. Сравним результаты процессора XLP и процессора RM7000 в случае копирования 4 Кб при полном отсутствии данных в кэш-памяти. Хотя на втором этапе тестирования было получено, что количество тактов для обращения в основную память на рассматриваемых процессорах приблизительно совпадает, процессор XLP обладает рядом преимуществ, в числе которых вдвое больший размер строки кэша второго уровня, отсутствие обращений к основной памяти на инструкциях записи и параллельная обработка промахов в кэш-память. Поскольку процессор XLP обладает двумя LSU-блоками, в очередях на выполнение может находиться до 32 инструкций чтения/записи. В рассматриваемом случае этого достаточно для одновременного копирования 16 двойных слов, то есть двух строк кэша второго уровня на процессоре XLP. Таким образом, скорость копирования данных на процессоре XLP должна быть как минимум в 8 раз выше скорости копирования на процессоре RM7000, что подтверждают результаты измерений. В случае работы с некэшируемой памятью скорость копирования данных вне зависимости от общего размера буферов составила приблизительно 19 000, 36 250 и 5 800 тактов/Кб на процессорах RM7000, XLP и ВМ8 соответственно. В качестве другой модельной задачи был рассмотрен метод Рунге–Кутты 4-го порядка точности. Количество обращений к памяти в этой задаче мало. Промежуточные результаты вычислений не сохранялись, что также снизило количество обращений к памяти. Метод Рунге–Кутты применялся к осциллятору Ван-дер-Поля, который задается следующей системой уравнений:
где x – координата точки; y=dx/dt – скорость точки; µ – некий коэффициент. Уравнение рассматривалось на фиксированном по времени отрезке при разном количестве шагов по времени. Для программной реализации поставленной задачи использовался язык программирования C. В данном случае изучалась работа функций, построенных с использованием ключей компилятора -O0 и -O3, то есть при отсутствии оптимизации и с высоким уровнем оптимизации. На всех трех процессорах использовался один и тот же компилятор и, как следствие, один и тот же объектный код. Все инструкции и данные, необходимые для работы программы, предварительно размещались в соответствующих кэшах процессоров. Из таблицы 9 видно, что при отсутствии оптимизации полученные результаты на всех трех процессорах достаточно близки. Лучшую производительность в тактах процессора в этом случае показал процессор XLP. Использование оптимизации приводит к сокращению времени выполнения на всех тестируемых процессорах. Лучшую производительность в тактах процессора в этом случае показал уже процессор ВМ8. Сравним объектный код программ, полученных при разных уровнях оптимизации. Так как каждый шаг метода Рунге–Кутты требует одних и тех же операций, в обоих случаях программа имеет структуру цикла. В зависимости от уровня оптимизации в цикле используются различные наборы инструкций. Укажем количество повторений каждой из них. С ключом –O0 dmtc1 – 156, ld – 94, dmfc1 – 68, mul.d – 34, add.d – 24, sdc1 – 24, lui – 18, addiu – 17, nop – 17, move – 16, sd – 10, jr – 8, jal – 8, sub.d – 8, ldc1 – 4, lw – 3, div.d – 2, sw – 2, bnez – 1, slti – 1. С ключом –O3: mul.d – 12, add.d – 10, madd.d – 8, msub.d – 4, sub.d – 4, bnez – 1, addiu – 1. За счет оптимизации количество используемых инструкций сократилось на порядок (с 515 до 40 инструкций). Компилятору удалось избавиться от инструкций перемещения данных между регистрами, обращений к памяти и большей части передач управления. Также сократилось количество инструкций вещественной арифметики.
- каждая инструкция вещественной арифметики зависит от пары инструкций dmtc1, которые загружают ее аргументы на регистры сопроцессора вещественной арифметики; - результат каждой инструкции вещественной арифметики выгружается на регистр общего назначения при помощи инструкции dmfc1, то есть выполнение dmfc1 не начнется, пока не станет доступным результат вычислений; - в слотах задержки всех инструкций передачи управления расположены инструкции nop; - для большей части остальных инструкций время освобождения блока выполнения конвейера происходит через 1 такт процессора, а дополнительных простоев из-за задержки результата не возникает. Предположим, что все инструкции программы выполняются последовательно, если только это не инструкции передачи управления, параллельно с которыми могут выполняться только их слоты задержки. Тогда, учитывая результаты первого этапа тестирования и сделанные утверждения о структуре программы, можно формально оценить длительность такого выполнения одной итерации цикла. На процессоре RM7000 получаем:
Разница между полученной оценкой и результатом измерений составила всего 31 такт процессора, следовательно, использование нескольких конвейеров на процессоре RM7000 практически не дает прироста к производительности из-за большого количества зависимостей по данным между соседними инструкциями. Аналогичные результаты получаются на процессоре ВМ8. Для процессора XLP разница между такой оценкой и реальным результатом оказывается уже значительной, что, вероятно, является следствием особенностей его архитектуры, которые позволяют изменять порядок выполнения инструкций и за счет этого добиваться лучших результатов, несмотря на большее по сравнению с остальными процессорами время выполнения отдельных типов инструкций. При высоком уровне оптимизации, как следует из таблицы 9, для выполнения одной итерации цикла на процессорах RM7000, XLP и ВМ8 требуется 95, 130 и 74 такта соответственно. Отметим, что процессор XLP в этом случае оказался медленнее RM7000 и ВМ8, а это хорошо согласуется с результатами первого этапа тестирования для инструкций вещественной арифметики.
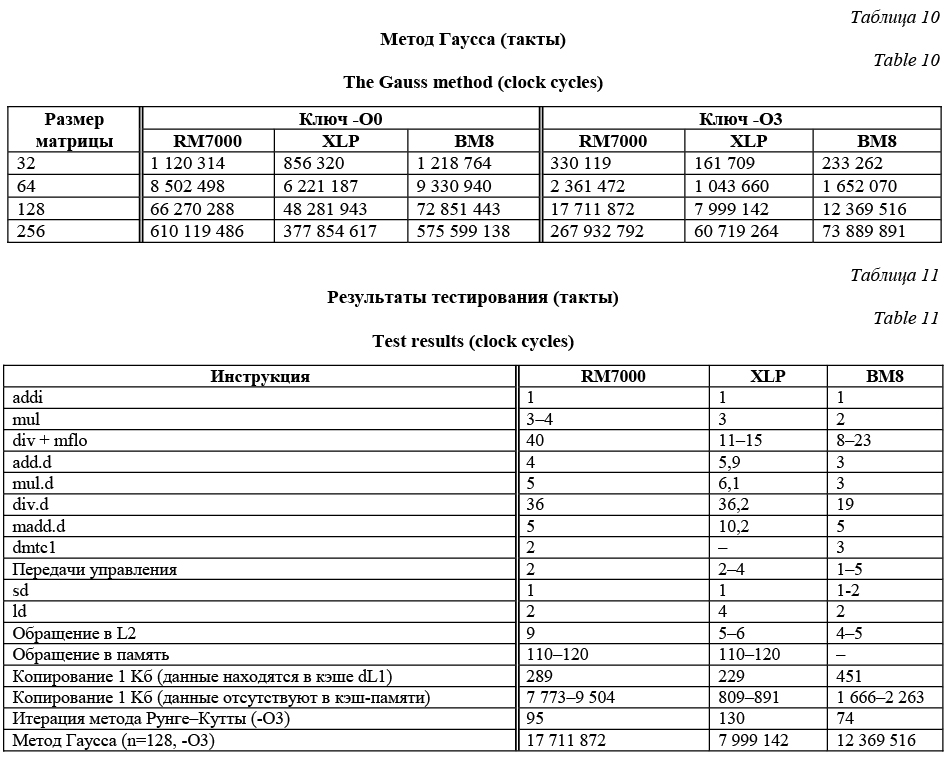
Наибольшую производительность в этом тесте показал процессор XLP в случаях как отсутствия оптимизации, так и ее высокого уровня. Результаты процессора ВМ8 при высоком уровне оптимизации оказались близкими к результатам процессора XLP. Заключение Подведем итоги проведенного тестирования. Разработанная тестовая система показала свою эффективность на практике. За исключением нескольких экспериментов, была измерена длительность выполнения многих низкоуровневых опе- раций. Благодаря этой информации обнаружено несколько технических особенностей архитектуры, влияющих на производительность при выполнении модельных задач. Основные результаты измерений (в тактах процессора) отражены в таблице 11. Проведенные измерения также показали, что среди процессоров невозможно однозначно вы- брать лидера по производительности. При опреде- ленных условиях каждый из трех процессоров может показать лучшую производительность, чем два других. Например, вычислительные задачи с небольшой долей обращений к памяти быстрее всего выполняются на процессоре ВМ8, даже если при- нять во внимание тактовые частоты процессоров. Для копирования больших объемов данных, напротив, лучше всего подходит процессор XLP, на котором большая длительность загрузки строк в кэш-память компенсируется увеличением их размера и их одновременной загрузкой. Литература 1. MIPS Architecture For Programmers, vol. III: The MIPS64 and microMIPS64 Privileged Resource Architecture, Revision 5.04, 2014. 2. PMC-Sierra. URL: https://www.pmcs.com (дата обращения: 23.03.2017). 3. NetLogic Microsystems. URL: https://www.netlogicmicro.com (дата обращения: 23.03.2017). 4. Бобков С.Г. Импортозамещение элементной базы вычислительных систем // Вестн. РАН. 2014. Т. 84. № 11. С. 1010–1016. 5. Curnow H.J. and Wichman B.A. a synthetic benchmark. Computer Jour., 1976, vol. 19, iss. 1, pp. 43–49. 6. Reinhold P. Weicker. Dhrystone: a synthetic systems programming benchmark. Communications of the ACM, 1984, vol. 27, iss. 10, pp. 1013–1030, DOI: 10.1145/358274.358283. 7. Zargham M.R. Computer architecture: single and parallel systems. Upper Saddle River, NJ, Prentice Hall, 1996, 472 p. 8. Бахвалов Н.С., Жидков Н.П., Кобельков Г.М. Численные методы. М.: Бином. Лаборатория знаний, 2003. 632 с. |


| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4309&lang= |
Статья в формате PDF Выпуск в формате PDF (21.91Мб) Скачать обложку в формате PDF (0.59Мб) |
| Статья опубликована в выпуске журнала № 3 за 2017 год. [ на стр. 409-419 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Модель и алгоритмы интерактивного оценивания знаний
- Способы инициализации многопроцессорной системы
- Особенности применения предметно-ориентированных языков для тестирования веб-приложений
- Разработка программных моделей доверенного универсального микропроцессора и микропроцессорной системы на его основе
- Особенности тестирования наборов данных в операционной системе z/OS
Назад, к списку статей