Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Интеллектуальная система автоматического определения категории потенциальных адресатов текста
Аннотация:Статья посвящена описанию программного комплекса – интеллектуальной системы автоматического определения категории потенциальных адресатов текста. Основная функция рассматриваемой системы – классификация текстов на основании возрастных категорий их потенциальных читателей. Автором сделан обзор существующих работ по схожей тематике – классификации документов на естественном языке. Особое внимание уделено исследованиям, посвященным выявлению характеристик авторов или адресатов текста. Сделан вывод о высокой актуальности разработок в данном направлении в связи с их востребованностью в качестве элементов поисковых систем, систем электронного обучения и т.д. В статье описан подход к моделированию текста, в рамках которого текст представляется в виде набора признаков. Выбор классификационных признаков осуществлен на основании анализа текстов, входящих в Национальный корпус русского языка. На основе разработанной модели создан программный комплекс, состоящий из трех подсистем: модуля семантикосинтаксического анализа, модуля хранения текстов и модуля классификации. Модуль классификации использует нейронную сеть типа многослойный персептрон. Разработанная интеллектуальная система успешно протестирована на текстах, возрастная категория читателей для которых определена на основании мнений экспертов.
Abstract:Automatic text classification is an important task of information retrieval and natural language processing. The article describes the intelligent system for automatic identification of the categories of text potential recipients. The main function of the system is text classification based on text addressee category. The author provides an overview of existing work on similar subjects, which is document classification in natural language. Particular attention he gives to research related to the identification of text authors’ or recipients’ characteristics. There is a conclusion that developments in this field are highly relevant due to the demand for them as elements of the search engines, elearning systems, etc. The paper presents an approach to text modeling when the text is presented as a set of features. A selection of classification features based on the analysis of texts belonging to the Russian National Corpus. The intelligent system based on the proposed mathematical model of the text consists of three subsystems: a semanticsyntactic parsing module, a text storage module and a classification module. The classification module uses a neural network belonging to the type of multi-layer perceptron. The developed intelligent system has been successfully tested on texts with potential recipients’ category defined on the basis of expert opinion.
| Авторы: Глазкова А.В. (a.v.glazkova@utmn.ru) - Тюменский государственный университет (старший преподаватель), Тюмень, Россия, кандидат технических наук | |
| Ключевые слова: классификация текстов, обработка естественного языка, нейронная сеть, извлечение информации, по |
|
| Keywords: text categorization, natural language processing, neural network, data mining, software |
|
| Количество просмотров: 10548 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
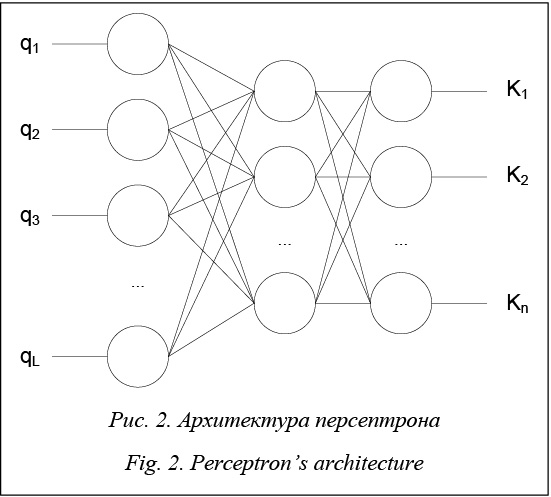
Решение задач автоматической классификации текстов в последние годы стало одним из приоритетных направлений развития исследований в областях информационного поиска и искусственного интеллекта. Средства автоматической классификации текстов находят применение не только при отборе наиболее релевантных результатов поисковых запросов, но и при решении таких прикладных задач, как фильтрация спама, составление персональных подборок новостей, автоматическое аннотирование, снятие неоднозначности при автоматическом переводе, определение языка текста. Задача классификации текстов подразделя- ется на две подзадачи: обучение классификато- ра и непосредственная классификация текстов. Наибольшую трудность при этом составляет первая подзадача, от успешности решения которой в итоге зависит достоверность проведенной классификации. Для обучения классификатора прежде всего проводится построение модели текста – представление в виде набора признаков. Решение задачи поиска классификационных признаков зависит от тематики текстов и цели классификации. Выделению значимых классификационных признаков посвящены работы многих исследователей. Например, проблема выявления наиболее информативных признаков описана в работе [1]. В статье [2] рассмотрена задача выделения дифференцирующих признаков при классификации текстовых сообщений. При этом авторами исследования описан метод классификации текстов на естественных языках, основанный на методе взаимной информации. В работе [3] выделены типы признаков на основании шкал, в которых они измеряются, приводятся примеры признаков каждого типа, а также обсуждаются возможные методы их анализа. На основании выбранных признаков выделяются тематические классы, на которые будут подразделяться тексты, подлежащие классификации, и проводится обучение классификатора, которое бывает трех видов: с учителем, без учителя и смешанное. Самым качественным считается обучение с учителем, однако оно осуществимо только в случае, когда возможно заранее получить выборку объектов со знанием их классов. Обучение с учителем использует байесовские и линейные методы, методы, построенные на применении деревьев решений или нейронных сетей. Модификации и применению классических методов решения задачи классификации текстов посвящены работы [4–6]. В настоящее время все большую распространенность в качестве средства решения слабоформализуемых задач приобретают искусственные нейронные сети. Рост популярности нейросетевых технологий обусловлен способностью нейронных сетей относить объект, представленный в виде набора классификационных признаков, к соответствующей ему категории на основании найденных скрытых закономерностей в данных обучающей выборки. При наличии достаточного числа примеров, по которым производится обучение, классифи- каторы, использующие нейронную сеть, часто являются оптимальным решением задач, слабо поддающихся формализации. Среди работ, представленных за последнее время, применению нейросетевых технологий в интеллектуальных системах классификации различных объектов посвящены статьи [7–9]. Перспективы и основные аспекты применения нейросетевых классификато- ров, а также использования нейронных сетей как составной части систем искусственного интеллекта рассмотрены в работе [10]. В рамках задач автоматической классификации текстов все большую актуальность приобретают проблемы установления характеристик автора и адресата текста, механизмы решения которых реализуются в поисковых системах, системах определения плагиата, построения авторских профилей (выявления возрастных, гендерных и других характеристик автора), электронных библиотеках и каталогах. Подходы к решению задачи установления характеристик автора текста довольно широко ос- вещаются в работах российских и зарубежных ученых. Так, методы идентификации авторства подробно рассмотрены в статье [11]. Различные подходы к выявлению характеристик автора предложены в работах [12–15]. В статье [16] описывается процесс формирования комплексной модели авторского текста. Задача определения адресата текста в настоящее время затрагивается преимущественно зарубежными исследователями. Например, в работах [17–19] рассмотрена задача разработки диалоговых систем, в контексте которой проанализированы признаки, характеризующие текст с точки зрения его ориентации на различные категории читателей. В настоящее время раз- работка средств решения задачи выявления характеристик адресата текста становится все более актуальной в связи с введением возрастных ограничений на контент интернет-ресурсов, развитием систем электронного обучения, а также с малой освещенностью данной проблемы в работах российских ученых. Данная работа посвящена описанию програм- много комплекса – интеллектуальной системы автоматического определения категории потенциальных адресатов текста, которая классифицирует тексты общей тематики на основании возрастной категории их предполагаемых читателей. В рамках исследования классификация текстов осуществляется по двум возрастным категориям – тексты, адресованные взрослым читателям, и тексты детской литературы, что обусловлено аналогичным делением текстов, входящих в обучающую выборку. Представление текстов Пусть имеются текст Т и множество категорий K={K1, K2, …, Kn}, с которыми он может быть соотнесен. В процессе классификации текст T представляется в виде набора (вектора) классификационных признаков: Т={qj}, 1≤j≤L, где qKj – классификационный признак; L – общее число классификационных признаков. Соответственно категория может быть представлена в следующем виде: Ki={qKj, wKj}, 1≤j≤L, 1≤i≤n, где wKj – весовой коэффициент классифика- ционного признака. Весовые коэффициенты характеризуют степень влияния каждого признака на вероятность отнесения объекта к той или иной категории. Предлагаемый подход подробно описан в работе [20], в данной статье сделан акцент на описании программной реализации. Для дальнейшего представления текста в виде набора признаков был проведен анализ текстов, входящих в Национальный корпус русского языка [21], с целью выявления базовых признаков, на основании которых может быть проведена класси- фикация [22]. Для выявления данных признаков использовались две выборки – художественные тексты различных жанров (историческая про- за, приключения, документальная проза и т.д., кроме детской литературы, – всего 5 902 документа, 9 332 659 предложений, 94 538 056 слов) и детская литература (всего 632 документа, 547 735 предложений, 4 742 627 слов). Были выявлены классификационные признаки, отражающие лексические (например, частотность слов или наличие специальных терминов) и синтаксические (частотность частей речи, сложность структуры предложений и синтаксических конструкций) особенности текста. Диапазон значений выделенных признаков может состоять из пары бинарных значений, конечного упорядоченного или неупорядоченного множества значений или бесконечного множества количественных значений. Программная реализация Интеллектуальная система разработана в среде Visual Studio 2010 на языке C#. Программный комплекс позволяет вводить или загружать и редактировать текст, предназначенный для классификации. Далее система проводит анализ полученного текста с целью нахождения значений классификационных признаков. Выявленные значения признаков используются в качестве основания для отнесения текста к той или иной категории – определения его возрастной аудитории. Данные о текстах, поступающих в систему, и сопоставленных им категориях могут быть сохранены в реляционной БД.
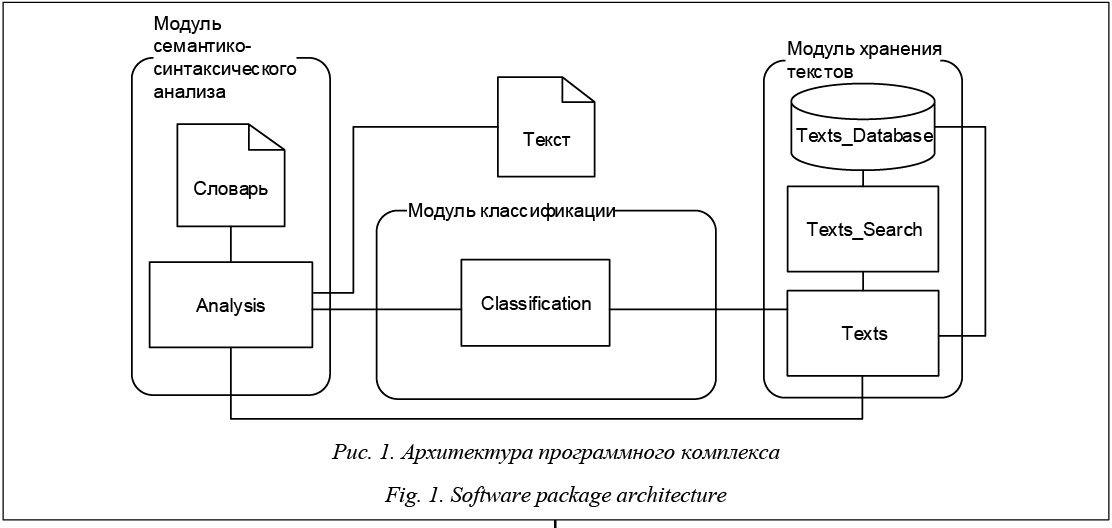
Основная функция модуля семантико-синтаксического анализа состоит в представлении текстов в виде наборов характеризующих их признаков. Загрузка текста для анализа осуществляется из БД или из файла формата .xml или .txt. После загрузки или создания документа пользователю предлагается провести анализ текста на основании его лексических и синтаксических характеристик. В процессе анализа текст разбивается на предложения, а также представляется в виде модели bag-of-words – множества пар лексем и соответствующих им частотностей. Результатом проведенного анализа текста является набор значений классификационных признаков, который впоследствии может быть использован при работе модуля классификации. Данные о тексте, а также соответствующие ему значения характеристик могут быть сохранены в БД. Модуль классификации осуществляет опре- деление соответствия текста существующим категориям. Соотнесение текста с категориями выполняется на основе классификационных признаков, полученных в ходе работы модуля семантико-синтаксического анализа. Для компьютерной реализации классификации была использована нейронная сеть – многослойный персептрон. Использование данного типа сети обусловлено ее способностью к решению слабоформализуемых типов задач на основании имеющихся примеров и выявлению закономерностей в связи входных и выходных данных.
Обучение персептрона производилось по алгоритму обратного распространения ошибки. Модуль хранения текстов предназначен для добавления информации, организации хранения данных в реляционных таблицах БД, организации взаимодействия всех модулей системы. В БД предусмотрена возможность хранения значений признаков различных типов. Хранение данных о текстах, поступающих в систему, и назначенных им категориях осуществляется в БД, использующей систему управления БД Microsoft SQL Server 2012 Express. Поиск информации о текстах по заданным критериям организован при помощи SQL-запросов. Проверка результатов Для обучения и тестирования нейронной сети использовались тексты, входящие в «Базу данных метатекстовой разметки Национального корпуса русского языка» [23]. База содержит заведомо качественные и максимально разнообразные тексты на русском языке, возрастная категория потенциальных читателей которых (взрослая или детская) определена на основании мнений экспертов. Объем обучающей выборки – 532 текста художественной литературы для взрослых и 510 текстов детской литературы. Точность классификации для обучающей выборки составила 98 %, для тестовой – 72 %. В заключение отметим следующее. Автоматическая классификация текстов является важной задачей информационного поиска и обработки естественного языка. В данной статье задача классификации рассмотрена на примере отнесения текстов к той или иной возрастной категории адресатов и представлена интеллектуальная система, протестированная на русскоязычных текстах. В перспективе разработанный программный комплекс может найти практическое применение в поисковых системах (для отбора релевантного контента), системах обучения, электронных библиотеках и каталогах, системах автоматического реферирования и рецензирования. Литература 1. Мангалова Е.С., Агафонов Е.Д. О проблеме выделения информативных признаков в задаче классификации текстовых документов // Вестн. Томск. гос. ун-та. Сер.: Управление, вычислительная техника и информатика. 2013. № 1 (22). С. 96–103. 2. Поляков И.В., Соколова Т.В., Чеповский А.А., Чеповский А.М. Проблема классификации текстов и дифференцирующие признаки // Вестн. Новосиб. гос. ун-та. Сер.: Информационные технологии. 2015. № 2. С. 55–63. 3. Колесникова С.И. Методы анализа информативности разнотипных признаков // Вестн. Томск. гос. ун-та. Сер.: Управление, вычислительная техника и информатика. 2009. № 1. С. 69–80. 4. Виноградов С.Ю. Применение байесовской сети в задаче классификации структурированной информации // Программные продукты и системы. 2013. № 2. С. 155–158. 5. Кубарев А.И., Кукушкина О.В., Поддубный В.В., Шевелев О.Г. Построение таблиц стилей текстовых произведений с использованием алгоритмов классификации на основе деревьев решений // Вестн. Томск. гос. ун-та. Сер.: Управление, вычислительная техника и информатика. 2012. № 4. С. 79–88. 6. Фальк В.Н., Шаграев А.Г., Бочаров И.А. Трансдук- тивное обучение логистической регрессии в задаче классификации текстов // Программные продукты и системы. 2014. № 2. С. 114–118. 7. Головко В.А., Крощенко А.А. Применение нейронных сетей глубокого доверия для выделения семантически значимых признаков // Открытые семантические технологии проектирования интеллектуальных систем (OSTIS-2015): матер. конф. 2015. С. 481–486. 8. Станкевич Л.А., Сонькин К.М., Нагорнова Ж.В., Хоменко Ю.Г., Шемякина Н.В. Классификация электроэнцефало- графических паттернов воображаемых движений пальцами руки для разработки интерфейса мозг–компьютер // Труды СПИИРАН. 2015. № 3. С. 163–182. 9. Палюх Б.В., Шпрехер Д.М., Богатиков В.Н. Диагностирование электромеханических систем на основе нейросетевых технологий // Программные продукты и системы. 2015. № 3. С. 5–11. 10. Мелихова О.А. Нейронные сети как составная часть систем искусственного интеллекта // Информатика, вычислительная техника и инженерное образование. 2015. № 1. С. 40–51. 11. Батура Т.В. Формальные методы установления авторства текстов и их реализация в программных продуктах // Программные продукты и системы. 2013. № 4. С. 286–295. 12. Argamon S., Koppel M., Pennebaker J., Schler J. Automatically profiling the author of an anonymous text. Communications of the ACM, 2009, no. 2, pp. 119–123. 13. Burger J., Henderson J., Kim G., Zarella G. Discriminating gender on twitter. Proc. Conf. on Empirical Methods in Natural Language Processing, 2011, pp. 1301–1309. 14. Gillam L. Readability for author profiling? Proc. CLEF, 2013, Valencia, Spain, 4 p. 15. Орлов Ю.Н., Осминин К.П. Определение жанра и автора литературного произведения статистическими методами // Прикладная информатика. 2010. № 2. С. 95–108. 16. Муха А.В., Розалиев В.Л., Орлова Ю.А., Заболеева-Зотова А.В. Автоматизированный подход к определению авторства текста // Изв. ВолгГТУ. 2013. № 14. С. 51–54. 17. Akker R. op den, Traum D. A comparison of addressee detection methods for multiparty conversations. Proc. of methods for multiparty conversations. Amsterdam, 2009, pp. 99–106. 18. Baba N., Huang H.-H., Nakano Y.I. Addressee identification for human-human-agent multiparty conversations in different proxemics. Proc. 4th Workshop on Eye Gaze in Intelligent Human Machine Interaction. ICMI. 2012, Santa Monica, USA, 6 p. 19. Lee H., Stolcke A., Shriberg E. Using out-of-domain data for lexical addressee detection in human-human-computer dialog. Proc. North American ACL/Human Language Technology Conf. Atlanta, 2013, pp. 215–219. 20. Глазкова А.В., Захарова И.Г. Подход к моделированию задачи автоматической классификации текстов (на примере их отнесения к определенной возрастной аудитории) // Вестн. Тюмен. гос. ун-та. Сер.: Физ.-мат. моделирование. Нефть, газ, энергетика. 2014. № 7. C. 205–211. 21. Национальный корпус русского языка. 2015. URL: ruscorpora.ru (дата обращения: 08.10.2015). 22. Глазкова А.В. Проверка информативности классификационных признаков в задаче автоматической классификации текстов на естественном языке // Открытые семантические технологии проектирования интеллектуальных систем (OSTIS-2015): матер. конф. 2015. С. 541–544. 23. База данных метатекстовой разметки Национального корпуса русского языка (коллекция детск. лит-ры). 2014. URL: ruscorpora.ru (дата обращения: 08.10.2015). |
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4182&lang=&lang=&like=1 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
| Статья опубликована в выпуске журнала № 3 за 2016 год. [ на стр. 85-89 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Сравнение нейросетевых моделей для классификации текстовых фрагментов, содержащих биографическую информацию
- Извлечение аспектов из текстов научных статей
- Разработка нейронной сети для оценки исправности гидроагрегата по результатам вибромониторинга
- Об уточнении принципа организации контроля качества программных продуктов
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
Назад, к списку статей