Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод распределенного анализа свойств верифицируемых моделей
Аннотация:Программные системы с каждым днем становятся все более сложными и комплексными, поэтому необходимо наличие таких инструментов, которые позволяли бы относительно легко выполнять проверку их работы на соответствие заданным спецификациям, особенно, когда речь идет о больших и распределенных программных системах. Однако зачастую на пути верификации данного рода систем встает проблема комбинаторного взрыва, из-за которой возникает резкий рост временной сложности во время верификации при относительно невысоком увеличении объема верифицируемых систем. И, как показывает практика, использование только существующих на сегодняшний день методов борьбы с данной проблемой, таких как абстракция, интерпретация и верификация «на лету», зачастую может оказаться недостаточным для ее преодоления. Логика подсказывает, что и процесс выполнения больших распределенных программных систем, и процесс верификации должны осуществляться распределенным образом. В статье подробно рассмотрен и проанализирован предлагаемый автором метод для преодоления проблемы комбинаторного взрыва в дополнение к уже имеющимся методам. Идея его состоит в использовании алгоритма распределенной верификации автоматов Бюхи для логики линейного времени (LTL). Применение данного алгоритма позволяет повысить эффективность и быстродействие всего процесса верификации за счет разделения вычислительной нагрузки на заданное количество вычислительных узлов. Несмотря на то, что идея разделения вычислительной нагрузки не является инновационной и подобные средства уже присутствуют в таком инструменте формальной верификации методом проверки на моделях, как Spin, предложенный алгоритм демонстрирует на практике более высокую эффективность работы, чем в Spin, что подкрепляется рядом наглядных примеров.
Abstract:Due to every day complexity and complication growth of software systems, we need some useful tools to check matching their specifications, especially for large distributed software systems. However, verification of this kind of systems is often followed by the “combinatorial explosion” problem, which causes a sharp growth of temporal complexity during verification at rather low volume increase of verifiable systems. Nowadays there are some methods to overcome this problem, such as abstraction, interpretation and verification “on the fly”. Nevertheless, practically, the usage of only existing methods can be often not enough to solve this problem. The logic prompts that we should carry out the process of executing large distributed software systems, as well as a verification process in a distributed way. The article offers and analyses a method for overcoming the problem of “combinatorial explosion”. It can be used as additional for already existing methods. The idea of the method consists in using the algorithm of Buchi automata distributed verification for linear temporal logic (LTL). This algorithm can help to increase efficiency and speed of the verification process due to division of computations between the number of computing knots. Despite the fact that the idea of distributed computations is not innovative and similar tools are already presented in a model checking tool Spin, the theoretical material of the article is supported by the set of examples which shows on practice that the proposed algorithm is more efficient than one presented in Spin.
| Авторы: Шипов А.А. (a-j-a-1@yandex.ru) - Московский технологический университет (МИРЭА) (старший инженер-программист), Москва, Россия, кандидат технических наук | |
| Ключевые слова: ctl, ltl, формула временной логики, автомат бюхи, spin, верификация |
|
| Keywords: ctl, ltl, temporal logic formula, Buchi automaton, spin, verification |
|
| Количество просмотров: 9691 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
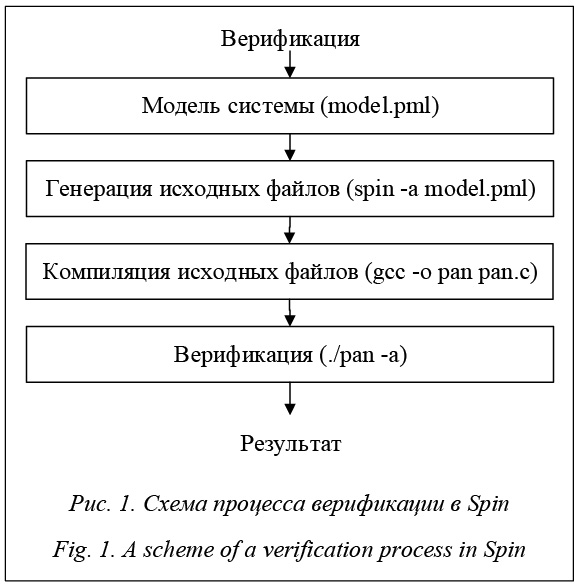
В последнее время широкое распространение в области верификации получил метод Model Checking [1, 2], или метод проверки на моделях. Суть его заключается в верификации свойств системы, представленных в виде формул временных логик LTL или CTL [3, 4]. При этом верифицируемая модель может быть задана либо явно – путем перечисления всех состояний и соединяющих их ребер, либо неявно – путем задания булевых функций, определяющих отношение переходов и множество начальных состояний. Однако при верификации больших информационных систем, в том числе и распределенных программных систем, зачастую приходится иметь дело с крайне большим числом состояний вычислительного процесса для их моделей. Например, для программы, одновременно выполняющей 10 потоков, каждый из которых может находиться в одном из 5 состояний, общее число состояний вычислительного процесса может достигать 510 = 9765625. Данная проблема называется комбинаторным взрывом и может стать непреодолимым препятствием на пути верификации тех или иных ее свойств. С каждым днем программные и технические системы становятся все более сложными и объемными, а степень их распределенности может измеряться сотнями и даже тысячами вычислительных узлов. В таких условиях полная верификация подобных систем становится весьма затруднительной или в принципе невозможной даже с применением уже существующих методов борьбы с комбинаторным взрывом. Идея предлагаемого в статье метода базируется на том, что процесс верификации должен проводиться аналогично процессу выполнения, то есть в данном случае распределенно. Это позволяет сформулировать новый алгоритмический подход для преодоления проблемы комбинаторного взрыва. Инструмент формальной верификации Spin Spin, или Simple Promela Interpreter – инструмент формальной верификации для анализа корректности больших распределенных программных систем c конечным числом состояний. Модели анализируемых систем в Spin задаются в виде взаимодействующих асинхронных процессов, а формальная спецификация проверяемых условий – формулами LTL. Система Spin, как видно из названия, базируется на C-подобном языке Promela. Promela, или Protocol Meta Language – язык для моделирования распределенных программных систем в виде взаимодействующих асинхронных процессов. Задача его – предоставление пользователю возможности построения модели распределенной программной системы и ее последующей проверки относительно всех аспектов работы и взаимодействия параллельных процессов, в связи с чем в языке существуют только три типа объектов спецификации: процессы, каналы обмена данными, переменные простых типов. Также в языке Promela есть возможность задания требований к системе в виде формул времен- ной логики LTL, а в Spin предусмотрена возможность их быстрой интерпретации в автоматы Бюхи. Следует заметить, что все формулы логики LTL в Spin и Promela лишены оператора X (neXt), который определяет состояние системы в следующий момент времени. Система Spin также предоставляет пользователю следующие опции для ускорения процесса верификации: редукция частичных порядков [5], абстракция данных [5], хэширование битовых состояний (вместо полных состояний хранится лишь их хэш, что снижает требования к объему памяти и уменьшает полноту системы) [6], ускорение проверки «корректности в слабом смысле», или Weak Fairness [7]. В отличие от аналогов Spin не выполняет верификацию самостоятельно, а генерирует программу на языке Си, которая выполняет это вместо него. Общая схема верификации для Spin и соответствующие ей этапы приведены на рисунке 1.
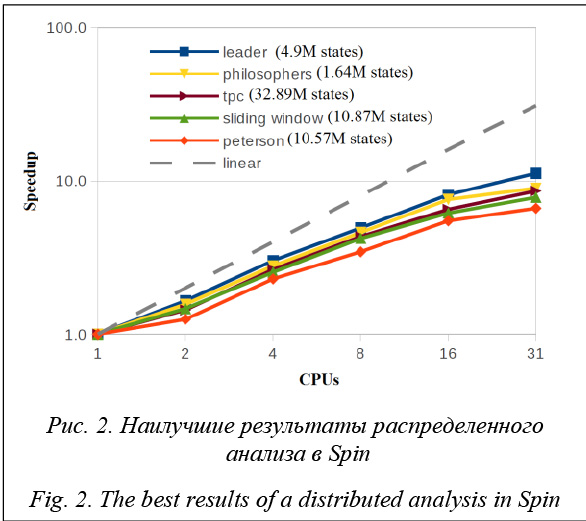
За счет такого подхода достигаются экономия памяти и повышение производительности, но в то же время усложняется весь процесс верификации, что может сказаться на общем времени его выполнения, особенно в случае, когда исходная модель достаточно велика и занимает большое количество строк программного кода на языке Promela. С 1995 года регулярно проводятся семинары Spin для пользователей данной системы и просто для тех, кто занимается исследованиями в области верификации больших распределенных програм- мных систем. В 2001 году Ассоциация вычислительной техники (ACM) вручила автору Spin награду System Software Award, что лишь подтвердило практическую значимость данной системы. Распределенная верификация в Spin. На сегодняшний день для верификатора Spin, помимо простого последовательного алгоритма, разработано несколько распределенных алгоритмов анализа, которые позволяют ускорять процесс верификации для больших распределенных программных систем: - распределенный поиск в глубину, или Multi-Core Depth-First Search; - распределенный поиск в ширину, или Multi-Core Breadth-First Search. Более подробно принцип работы данных алгоритмов рассматривается в [8, 9]. В этих работах описано тестирование пяти программных систем, для которых выполнен как последовательный, так и распределенный анализ данных систем без верификации конкретных свойств. Наилучшие результаты показал алгоритм поиска в ширину (рис. 2).
Серой пунктирной линией (linear) на рисунке 2 обозначено предельно возможное ускорение, которое соответствует числу используемых вычислительных узлов (CPUs). Эффективность описываемых алгоритмов, как заявляют авторы представленных работ, прямо пропорциональна числу анализируемых состояний модели и в идеальном случае коэффициент ускорения может составить порядка 99 % от числа используемых вычислительных узлов. Однако при достаточно больших размерах тестируемых выше моделей систем, измеряемых миллионами состояний, фактически коэффициент ускорения остается весьма далеким от числа используемых вычислительных узлов. Так, например, для модели алгоритма телефонной коммуникации TPC ускорение на тридцати одном вычислительном узле не превысило значения 10, хотя число состояний модели было более 32 миллионов. А алгоритм Петерсона для взаимного исключения четырех взаимодействующих процессов на четырех вычислительных узлах показал ускорение всего в 2.3041 раза. В таблице 1 показаны среднестатистические значения ускорения распределенного алгоритма поиска в ширину Spin относительно линейного на одном, двух, трех и четырех вычислительных узлах. Для каждого из шести представленных тестов использовались 1 400 случайно сгенерированных пар автоматов модели и условия соответствующих размеров. Таблица 1 Ускорение для распределенного алгоритма поиска в ширину Table 1 Breadth first search distributed algorithm activation
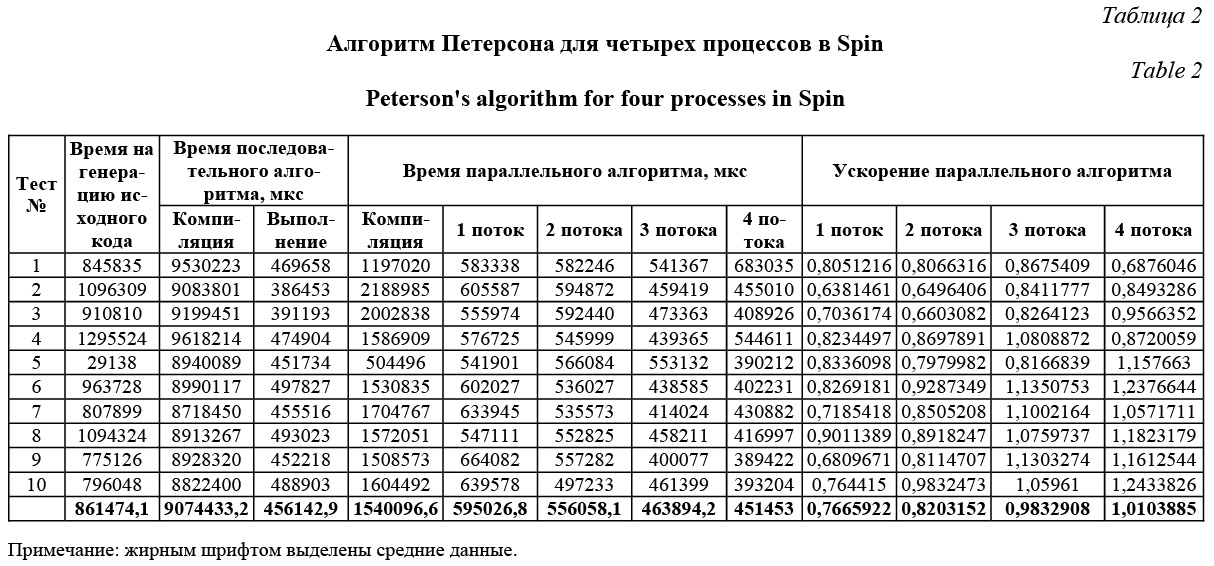
Таким образом, использование распределенного алгоритма анализа для относительно небольших моделей в Spin является крайне неэффективным, что лишний раз подтверждает необходимость его использования только для больших програм- мных систем. Для наиболее полного представления работы распределенного алгоритма в Spin автором была выполнена еще одна оценка. В ее основе был тот же алгоритм Петерсона для четырех процессов, только в данном случае его анализ уже проводился относительно следующего условия: «Если первый процесс начал свое выполнение, то когда-нибудь он войдет в критическую секцию». В целом было проведено десять тестов, для которых, помимо оценки ускорения распределенного алгоритма относительно последовательного, была также выполнена оценка времени, которое требуется на генерацию исходных кодов и их компиляцию. Результаты, представленные в таблице 2, показывают, что лишь анализ на основе четырех потоков в среднем позволяет получить ускорение, которое больше единицы, но совсем незначительно. Таким образом, для получения существенного ускорения в Spin для моделей относительно небольших разме- ров требуется выполнять анализ на значительно большем числе вычислительных узлов.
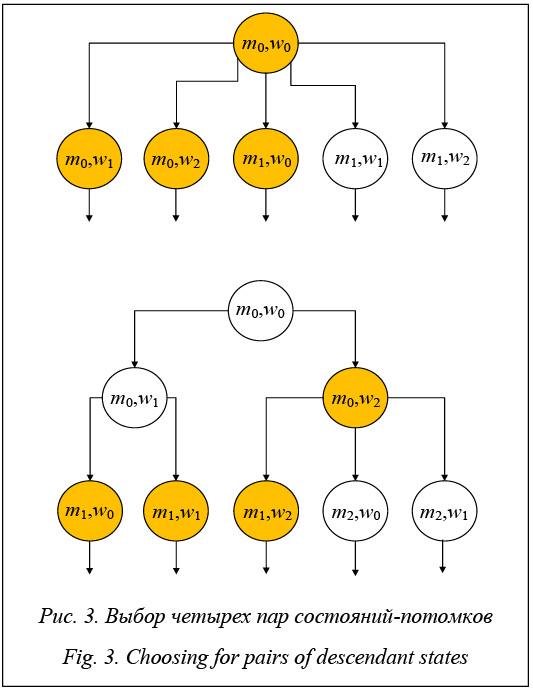
Дополнительную информацию по алгоритмам распределенного анализа в Spin можно найти в работах [10–12]. Распределенный алгоритм верификации автоматов Бюхи Алгоритм распределенного анализа, предлагаемый в работе, используется применительно к автомату Бюхи, на базе которого будут сформулированы как модель анализируемой системы, так и проверяемое условие, изначально заданное в терминах LTL. Предложенный автором подход позволяет добиться более существенных результатов в сравнении с алгоритмами распределенного анализа, рассмотренными ранее для Spin, что на практике демонстрируют представленные в работе примеры. Распределенный метод верификации автоматов Бюхи состоит из двух этапов, каждый из которых выполняется распределенным образом на заданном количестве вычислительных узлов: поиск допустимых состояний и поиск циклов из допустимых состояний. Стоит отметить, что на данных этапах не происходит фактического построения синхронной композиции автоматов модели системы M (Model) и проверяемого условия W (Watchdog), а выполняется лишь процесс их синхронной работы, то есть посещение всех достижимых пар состояний из начальной пары , что позволяет существенно экономить расходуемую память. Поиск допустимых состояний. Поиск допустимых состояний в композиции M и W начинается с поиска из их начальной пары состояний множества из таких N пар состояний-потомков, что любая непройденная пара состояний будет достижима хотя бы из одной пары состояний этого множества, где N – число используемых вычислительных узлов. Пример выбора состояний для двух произвольных различных случаев, где N=4, представлен на рисунке 3.
Желтым цветом на рисунке 3 обозначены те самые четыре пары состояний. Для нахождения этих пар используется алгоритм поиска в ширину. Если в процессе поиска встречается допустимая пара состояний, то она заносится в общий список найденных допустимых пар или, если требовалось найти только одну пару допустимых состояний, первый этап заканчивается. Если первый этап не был прекращен, создаются N потоков, каждый из которых использует одну из найденных пар состояний в качестве начальной и выполняет из нее алгоритм поиска в глубину. Все потоки работают с одной общей областью памяти, что позволяет каждому из потоков знать, какие пары состояний еще свободны, а какие уже заняты другими потоками. Алгоритм поиска в глубину на данном этапе позволяет достичь наименьшей конкуренции между потоками и наибольшего распределения нагрузки. В зависимости от поставленной цели потоки осуществляют поиск либо всех допустимых пар состояний, которые будут также занесены в общий список допустимых пар состояний, либо одной пары, встретившейся любому из потоков, после чего дальнейший поиск прекращается. Поиск циклов из допустимых состояний. Поиск циклов из найденных допустимых пар состояний также выполняется распределенным образом, однако алгоритм, который будет выбран для этого, напрямую зависит от того, сколько таких пар было найдено на предыдущем этапе. Рассмотрим первый случай, если число допустимых пар больше или равно N. В этом случае все найденные пары состояний делятся на N групп, которые должны быть максимально равны между собой. Затем каждая из групп передается соответствующему потоку, который поочередно для всех пар в группе проверяет наличие циклов алгоритмом поиска в глубину. Во втором случае, когда число найденных допустимых пар состояний меньше N, выбирается иной алгоритм для достижения максимальной эффективности распределенного анализа. В этом случае для каждой допустимой пары состояний выполняется практически тот же самый алгоритм, что был описан на предыдущем этапе. Для текущей допустимой пары выполняется поиск N пар состояний-потомков, как и на первом этапе. Далее из каждого потомка в соответствующем потоке будет выполнена попытка достичь исходной допустимой пары состояний алгоритмом поиска в глубину. Если хотя бы одному из потоков это удается, анализ текущей допустимой пары состояний прекращается и начинается анализ следующей пары. Выбор одной из двух альтернатив поиска циклов в каждом отдельном случае обосновывается неэффективностью использования каждой из них в качестве единственной. Если первый алгоритм будет использоваться при числе допустимых пар состояний меньшем, чем N, то будет простаивать как минимум один вычислительный узел. В то же время, если второй алгоритм будет использоваться, когда число допустимых пар состояний больше или намного больше N, то будет тратиться большое количество времени на создание и синхронизацию потоков для каждой анализируемой пары, что может сделать его крайне неэффективным. Таким образом, только совместное использование двух данных подходов к распределенному поиску циклов может гарантировать наибольшую эффективность. В конце выводится либо подтверждение успешной верификации заданного свойства, либо информация обо всех найденных контрпримерах – вычислительных последовательностях, где свойство не выполняется. Суперлинейное ускорение. В некоторых случаях использование алгоритма распределенной верификации автоматов Бюхи позволяет достигать суперлинейного ускорения, то есть такого ускорения, значение которого превышает число используемых вычислительных узлов и соответствующее им число потоков. Достижение подобного эффекта возможно только в случае обнаружения контрпримеров и лишь при задаче поиска не всего их числа, а любого первого встретившегося. Рассмотрим пример суперлинейного ускоре- ния, достигаемого за счет первого этапа работы ал- горитма (рис. 4).
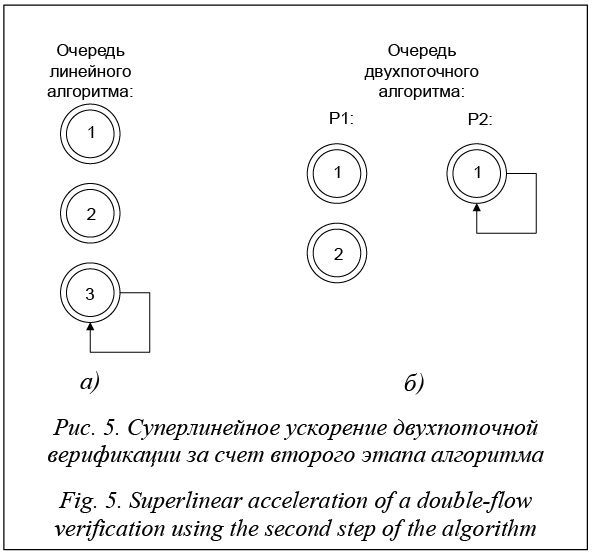
На рисунке 4а внутри состояний обозначены цифры, соответствующие номеру шага, на котором они будут обрабатываться, так, например, допустимое состояние будет обрабатываться на последнем, десятом шаге. Если же обработка данного автомата будет осуществляться на двух вычислительных узлах, как показано на рисунке 4б, то потребуется всего три шага на то, чтобы найти допустимое состояние. Еще один шаг потребуется в обоих случаях, чтобы найти цикл из найденного допустимого состояния. Таким образом, для выполнения верификации в случае с линейным алгоритмом потребуется одиннадцать шагов, а в случае двухпоточного анализа – четыре, что позволяет получить коэффициент ускорения больше двух. Эффект суперлинейного ускорения может достигаться также и за счет второго этапа алгоритма (рис. 5).
Очевидно, что суперлинейное ускорение может достигаться за счет того, что линейному алгоритму (а) может потребоваться больше шагов для нахождения допустимого состояния с циклом, чем параллельному (б). В данном случае, если условиться, что время на поиск цикла или его отсутствия для всех допустимых состояний будет равным, двухпоточному алгоритму потребуется всего один шаг, а последовательному – три, что позволяет получить коэффициент ускорения на втором этапе, превышающий два. Результаты. В таблице 3 показаны среднестатистические значения ускорения распределенного алгоритма верификации автоматов Бюхи относительно последовательного для случая поиска всех контрпримеров на одном, двух, трех и четырех ядрах. А в таблице 4 для более полного представления работы алгоритма приведены аналогичные данные, но только для случая поиска алгоритмом не всех контрпримеров, а любого из них. Таблица 3 Распределенный алгоритм верификации автоматов Бюхи (все контрпримеры) Table 3 A distributed algorithm of Buchi automata verification (all counterexamples)
Таблица 4 Распределенный алгоритм верификации автоматов Бюхи (один контрпример) Table 4 A distributed algorithm of Buchi automata verification (one counterexample)
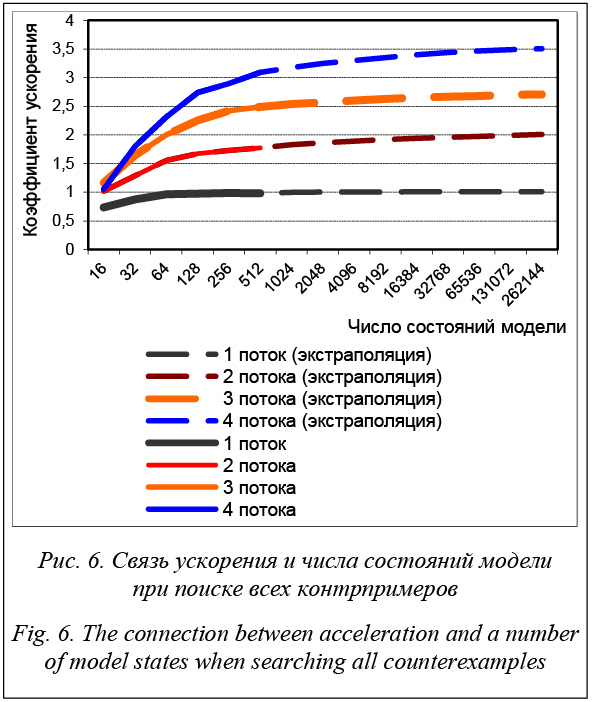
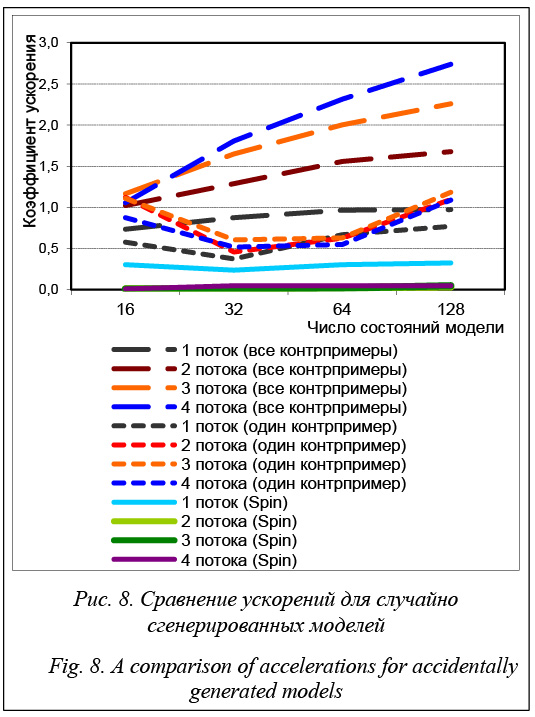
Следует отметить, что предлагаемый подход может быть использован для произвольного числа вычислительных узлов, потому предел в четыре ядра в нашем случае обусловлен лишь ограниченностью автора в вычислительных ресурсах. Для каждого из двух подходов к поиску допустимых состояний было выполнено шесть тестов, в которых использовались 1 400 случайно сгенерированных пар автоматов модели и условия, соответствующих размеров. Полученные в результате данные показывают, что даже на относительно маленьких автоматах использование описанного выше алгоритма позволяет получить существенное ускорение, которое, как видно из графика на рисунке 6, с ростом числа состояний модели стремится к значению числа используемых потоков.
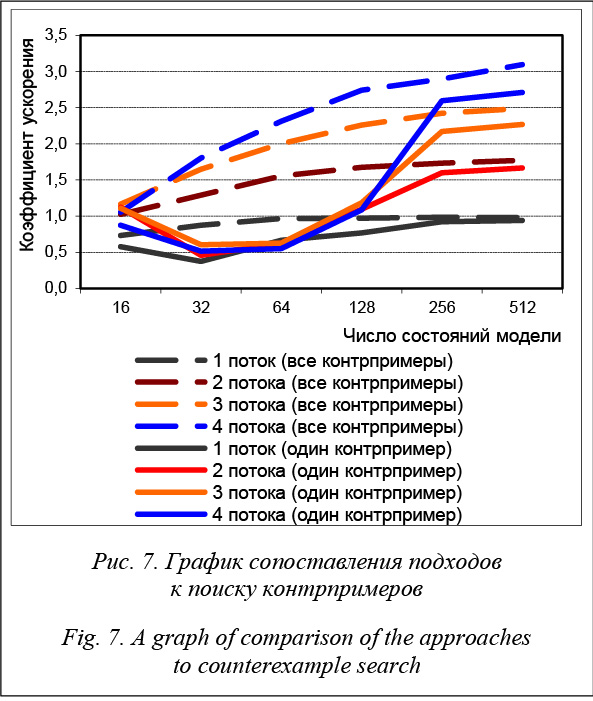
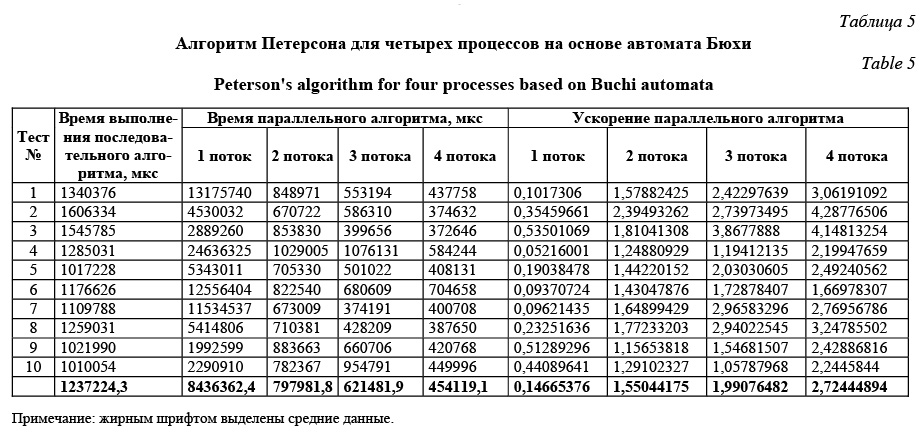
Сопоставление времен выполнения каждого из подходов показывает, что поиск всех контрпримеров длится в среднем в 6,5 раза дольше, чем поиск одного контрпримера при использовании того же числа потоков. Из рисунка 7 видно, что существенные отличия в ускорениях между данными подхо- дами возникают лишь при крайне маленьких раз- мерах модели (меньше 256 состояний). Это можно обосновать тем, что в случае поиска только одного контрпримера второй этап алгоритма дает значительно меньший прирост скорости, чем в случае поиска всех контрпримеров, поскольку его работа прекращается сразу же после нахождения любым из потоков допустимого состояния с циклом. А так как линейному алгоритму в случае с моделью не- большого размера на втором этапе нужно прове- рить лишь весьма малое число допустимых состояний на наличие циклов и не требуется тратить время на создание потоков, он оказывается более эффективным. Помимо представленных выше тестов, в работе так же, как это было сделано для Spin, выполнена верификация алгоритма Петерсона для четырех процессов и аналогично проведено десять тестов. Результаты тестов представлены в таблице 5. Они показывают, что за счет алгоритма распределенной верификации автоматов Бюхи в среднем удается добиться весьма значительного ускорения, которое в некоторых случаях сопоставимо с числом потоков, а в некоторых даже является суперлинейным. В целом результаты, полученные для распределенного алгоритма верификации автоматов Бюхи, можно охарактеризовать следующим образом: коэффициент ускорения постоянно стремится к значению числа используемых для анализа потоков при увеличении размеров анализируемой системы, однако для модели конкретного размера существует такой предел числа потоков, после которого ускорение начнет падать. Сравнение со Spin
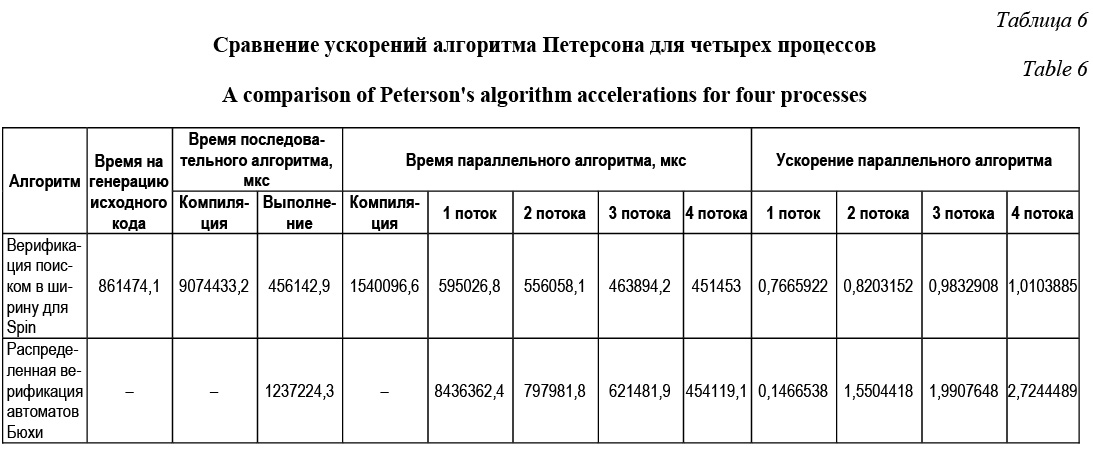
Нетрудно заметить, что в данном случае на моделях небольших размеров распределенный алгоритм поиска в ширину в Spin полностью уступает распределенному алгоритму верификации автома- тов Бюхи, не показывая ускорения относительно последовательной версии. Также выполним сравнение времен и ускорений, полученных в обоих случаях при верификации алгоритма Петерсона четырех процессов относительно одного и того же условия. В таблице 6 дано сравнение средних значений десяти тестов для каждого из алгоритмов.
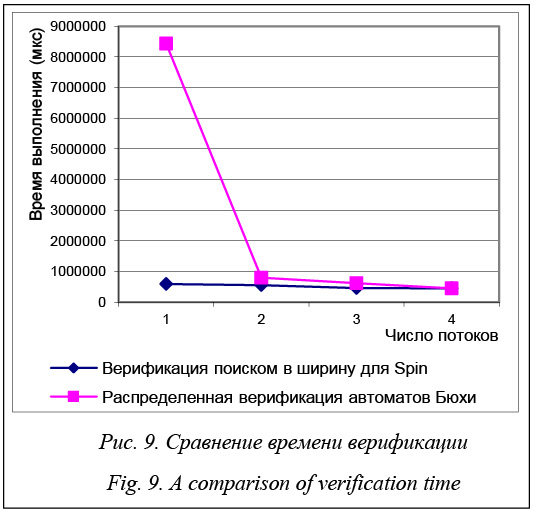
Очевидно, что алгоритм распределенной верификации автоматов Бюхи является более эффективным с точки зрения демонстрируемого ускорения в зависимости от числа потоков. И хотя без учета этапов генерации и компиляции Spin демон- стрирует меньшее время выполнения, из графика, представленного на рисунке 9, видно, что верификация модели алгоритма Петерсона четырех процессов на пяти потоках у алгоритма распределенной верификации автоматов Бюхи займет меньше времени. В целом после выполненных сравнений можно с уверенностью утверждать, что алгоритм распределенной верификации автоматов Бюхи является весьма эффективным способом ускорения процесса анализа больших распределенных програм- мных систем и во многом превосходит методы распределенного анализа, представленные в Spin. В заключение отметим, что идея использования алгоритмов распределения вычислительной нагрузки не является новой, однако эффективность многих из существующих сегодня в области верификации моделей систем крайне низкая и это зачастую приводит к отказу от их использования в пользу обычных последовательных алгоритмов. В статье предложен и рассмотрен новый метод распределенного анализа, существенно снижающий проблему комбинаторного взрыва за счет распределения вычислительной нагрузки на несколько вычислительных узлов во время верификации. Эффективность метода была показана на ряде конкретных примеров, а его сравнение с распределенным алгоритмом анализа одного из ведущих инструментов формальной верификации Spin показало наличие ряда преимуществ, позволяющих сделать подобные алгоритмы главным инструментом в борьбе с проблемой комбинаторного взрыва. Автор убежден, что использование предложенного метода позволит в большинстве случаев эффективно снижать проблему комбинаторного взрыва при верификации больших распределенных программных систем, особенно при совместном использовании с уже существующими методами. Литература 1. Карпов Ю.Г. Model Checking. Верификация параллельных и распределенных программных систем. СПб: БХВ-Петер-бург, 2010. 552 с. 2. Кораблин Ю.П. Семантика языков распределенного программирования: учеб. пособие; [под ред. В.П. Кутепова]. М.: Изд-во МЭИ, 1996. 102 с. 3. Kroger F., Merz S. Temporal logic and State Systems. Springer, 2008, 436 p. 4. Manna Z., Pnueli A. The temporal logic of reactive and concurrent systems: specification. 1992, 427 p. 5. Кларк Э.М., Грамберг О., Пелед Д. Верификация моделей программ. Model Checking. М.: Из-во МЦНМО, 2002. 416 с. 6. Holzman G.J. An analysis of bitstate hashing. Proc. 15th Intern. Conf. Protocol Specification, Testing, and Verification, 1998, pp. 301–314. 7. Olderog E.-R., Apt K.R. Fairness in parallel programs: the transformational approach. ACM Transactions on Programming Languages and Systems, 1988, vol. 10, no. 3, pp. 420–455. 8. Holzmann G.J., Bosnacki D. The design of a multi-core extension of the SPIN model checker. IEEE Transactions on Software Engineering, 2007, vol. 33, iss. 10, pp. 659–674. 9. Holzmann G.J. Parallelizing the Spin Model Checker. Series Lecture Notes in Comp. Sc., 2012, vol. 7385, pp. 155–171. 10. Barnat J., Brim L. Parallel breadth-first search LTL model-checking. Proc. 18th IEEE Intern. Conf. on Automated Software Engineering (ASE'03), 2003, pp. 106–115. 11. Barnat J., Brim L. Distributed LTL model-checking in SPIN. Lecture notes in comp. sc., 2001, vol. 2057, pp. 200–216. 12. Lerda F., Sisto R. Distributed-memory model checking with SPIN. Lecture notes in comp. sc., 1999, vol. 1680, pp. 22–39. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4148 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 53-61 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Верификация моделей систем на базе эквациональной характеристики формул LTL
- Построение моделей систем на базе эквациональной характеристики формул LTL
- Эквациональная характеристика формул LTL
- Метод ограничений верифицируемых моделей
- Унифицированное представление формул логик LTL и CTL системами рекурсивных уравнений
Назад, к списку статей