Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Программный комплекс для анализа данных из социальных сетей
Аннотация:Статья посвящена проблемам извлечения и обработки данных из социальных сетей. Рассмотрены различные количественные характеристики, отношения и множества, вычислимые на основе получаемых данных. Важно, что эти характеристики являются конструктивными и могут быть эффективно вычислены или построены при помощи соответствующих алгоритмов. Количество информации, находящейся в социальных сетях, очень велико. При использовании распределенной системы извлечения и обработки данных объем увеличивается еще больше. Поэтому наиболее важной и трудной задачей является выделение той части данных, которую можно было бы достаточно эффективно обработать и которая представляла бы интерес в соответствии с поставленными целями. Для решения этой задачи предлагается применить метод определения количества влияния аудитории на отдельного пользователя. Метод основан на теории динамического социального влияния, предложенной Б. Латане. Данный подход является полезным также при решении задачи определения источника распространения информации. Задача определения количества влияния на пользователя со стороны других пользователей непосредственно связана с задачей обнаружения лидеров мнений – сравнительно популярных пользователей, которые формируют мнение остального большинства. В работе предложен один из возможных методов определения лидеров мнений. Приведено довольно подробное описание разработанного программного комплекса, позволяющего работать с информацией из социальных сетей ВКонтакте и Twitter. Он состоит из шести модулей: извлечения, обработки данных, отслеживания изменений пользовательских данных, анализа данных, построения графовых структур и модуля визуализации данных.
Abstract:The paper focuses on the problems of extracting and processing social network data. It considers various numerical characteristics, relations and sets analyzed on the basis of output data. It is important that these characteristics are constructive and can be effectively calculated or built using corresponding algorithms. The data amount in social networks is large. It becomes even larger when using distributed data extraction and processing system. That is why the most significant and difficult problem is to determine data, which could be processed effectively enough and is of interest according to the goals. To solve this task, we suggest using the method of determining the amount of audience influence on individual users. The method is based on the dynamic social impact theory proposed by B. Latané. This approach is also useful for solving the problem of determining the primary source of information. This problem is connected to the opinion leader detection problem. Opinion leaders are popular users who form the opinion of the majority. The paper describes one of the methods of opinion leader detection. The article provides a detailed description of the developed software, which processes information from social networks VKontakte and Twitter. It consists of six modules: extraction module, data processing module, user data change tracking module, data analysis module, graph construction module and data visualization module.
| Авторы: Батура Т.В. (tatiana.v.batura@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (старший научный сотрудник), г. Новосибирск, Россия, кандидат физико-математических наук, Мурзин Ф.А. ( murzin@iis.nsk.su) - Институт систем информатики им. А.П. Ершова СО РАН (зам. директора по научной работе), г. Новосибирск, Россия, кандидат физико-математических наук, Проскуряков А.В. (alexey.proskuryakov@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (аспирант), Новосибирск, Россия | |
| Ключевые слова: межличностный анализ, лидеры мнений, источник распространения информации, обработка данных на естественном языке, анализ социальных сетей |
|
| Keywords: interpersonal analysis, opinion leaders, primary source of information dissemination, natural language data processing, social network |
|
| Количество просмотров: 9158 |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
Сложно представить современный мир без социальных сетей. Это удобное средство общения между людьми, кроме того, сети открывают новые возможности для анализа потоков информации и поведения людей в процессе общения. Анализ структуры графов и текстовых данных, получаемых из социальных сетей, является наиболее эффективным методом изучения взаимодействий между их участниками. Важный элемент подобных исследований – создание программных инструментов, позволяющих извлекать из сетей данные и обрабатывать их. В статье приведено довольно подробное описание разработанного программного комплекса для извлечения, обработки и анализа пользовательских данных. Эксперименты проводились по извлечению данных из сетей ВКонтакте и Twitter, хотя модуль извлечения системы имеет возможность функционального расширения практически на любую социальную сеть в зависимости от предоставляемого API. В целом система состоит из шести модулей, в том числе модуля отслеживания изменений в пользовательских данных и модуля построения графов. Просматривать и обрабатывать невероятно большие потоки информации, которые постоянно обновляются, не только затруднительно, но и нерационально. По мнению авторов, сравнительно большая часть информации в социальных сетях представляет собой средство самовыражения, когда человек делает заметки для себя, не преследуя какие-то дополнительные цели наподобие рекламы, агитации и пр. Это предположение подтверждает официальная статистика [1], согласно которой, 40 % всех твитов можно отнести к светской беседе. Чтобы выбрать существенную информацию из большого объема разнородных данных, необходимо разрабатывать определенные критерии. В ряде случаев достаточно ограничить число отслеживаемых пользователей и, к примеру, просматривать только тех, которые пользуются большей популярностью. Их называют лидерами мнений. Это люди, чье мнение оказывает на окружающую аудиторию большое влияние, формируя таким образом мнение остального сообщества. Помимо количества подписчиков или друзей, лидера мнений характеризуют такие величины, как количество созданных сообщений, лайков, репостов и комментариев, которые собирают записи пользователя. Не менее важной задачей является определение количества влияния, оказываемого на человека со стороны его окружения. Для ее решения предлагается адаптировать к социальным сетям теорию Латане социального влияния [2, 3]. Количественные характеристики, отношения и множества, вычислимые на основе данных из социальных сетей При анализе социальных сетей целесообразно рассматривать ряд числовых и нечисловых характеристик, отношений и множеств, естественно связанных с пользователями сети и сообщениями, циркулирующими в ней. Важно, чтобы эти характеристики могли быть вычислены или построены при помощи соответствующих алгоритмов. Обозначим T сообщение (твит) социальной сети, u – пользователя сети, который может создавать и пересылать сообщения. Одноместные характеристики: Followers_Count(u) – количество людей, которые читают сообщения данного пользователя (то есть подписчиков этого пользователя); Friends_Count(u) – количество друзей данного пользователя (пользователь сам заносит некоторых людей в список друзей); Retweets(T) – количество пересылок данного сообщения. Множества: Followers(u) – подписчики данного пользователя; Friends(u) – друзья данного пользователя; Mentions(u) – имена пользователей, упоминаемые в сообщениях данного пользователя; Hashtags(u) – хэштеги, встречающиеся в сообщениях данного пользователя; Urls(u) – внешние ссылки, встречающиеся в сообщениях данного пользователя. Хэштег – это слово или набор слов, записанных без пробелов и начинающихся с символа #. Является одной из форм метаданных. Короткие сообщения в блогах или социальных сетях типа Facebook, Twitter или Instagram могут быть помечены символом # перед ключевыми словами или фразами, не содержащими пробелов. Они встречаются в любых предложениях. Например, «Эверест (Гималаи) самая высокая точка мира #12МестКоторыеЯБыХотелПосетить». Хэштеги позволяют группировать похожие сообщения. По заданному хэштегу можно найти набор сообщений, содержащих его. Числовые характеристики, ассоциированные с множествами: Count_Mentionsu(v) – количество упоминаний пользователя v пользователем u; Count_Hashtagsu(v) – количество употреблений хэштега v пользователем u; Count_Urlsu(v) – количество упоминаний внешней ссылки v пользователем u; Count_Retweetsu(u1) – количество сообщений, пересланных пользователем u, полученных от пользователя u1. При анализе процессов, происходящих в коллективах, в исследованиях по социологии, психологии, экономике часто рассматривают трехмест- ные отношения предпочтения [4]. Согласно [5], запись Трехместные отношения: Mentionsu(u1, u2) – пользователь u упоминает пользователя u1 не реже, чем u2; Hashtagsu(h1, h2) – пользователь u употребляет хэштег h1 не реже, чем хэштег h2; Urlsu(url1, url2) – пользователь u упоминает ссылку url1 не реже, чем ссылку url2; Retweetsu(u1, u2) – пользователь u пересылает сообщения, полученные от пользователя u1, не меньшее число раз, чем полученные от пользователя u2. Числовые характеристики, ассоциированные с трехместными отношениями: N_Mentionsu(u1, u2)= =Count_Mentionsu(u1) – Count_Mentionsu(u2); N_ Hashtagsu(h1, h2)= =Count_Hashtagsu(h1) – Count_Hashtagsu(h2); N_ Urlsu(url1, url2)= =Count_Urlsu(url1) – Count_Urlsu(url2); N_ Retweetsu (u1, u2)= =Count_ Retweetsu (u1) – Count_ Retweetsu(u2). Можно считать, что приведенные выше функции также позволяют определять силы влияния различных факторов. Например, функция N_Mentionsu(u1, u2) позволяет вычислить силу влияния пользователя u1 по сравнению с u2 на пользователя u, то есть силу влияния с учетом предпочтений пользователя u. Например, если пользователь u="@mursya_ru" упоминает 8 раз пользователя u1="@tadatuda" и 12 раз пользователя u2='@voischev', то N_Mentionsu(u1, u2) = 12 – 8 = 4. Теория Латане социального влияния и ее модификация Теория динамического социального влияния, предложенная Латане [2, 3], позволяет вычислить «количество влияния», оказанного на получателя информации из нескольких источников. Латане выделял три наиболее важных атрибута отношений между получателем информации и ее источниками: сила источника влияния на агента, расстояние между агентом и источником и количество источников, влияющих на получателя. Под расстоянием понимается оперативность перемещения информации от источника к агенту воздействия. Согласно теории социального влияния, уровень влияния, испытываемого агентом, может быть выражен следующей формулой: Значение постоянной b обычно принимается равным 2 в соответствии с величиной, использованной в исследованиях Латане. Большее значение этой постоянной означает, что для изменения мнения требуется большее давление, меньшее значение соответствует меньшему усилию. Значение постоянной a также обычно принимается равным 2. Большие значения a означают, что с ростом расстояния между источником и получателем требуется гораздо большая величина давления. Величина dij определяется свойствами пары агентов, она может рассматриваться как показатель легкости общения (передачи информации). При задании данной величины могут учитываться возрастные, национальные, конфессиональные и другие различия. Формула для вычисления dij может включать в себя физическое расстояние. Например, между населенными пунктами, в которых находятся агенты. Обычно учитывается то, что легкость коммуникации подчиняется закону об обратной квадратичной зависимости от физического расстояния [3]. В случае с социальными сетями возможны различные подходы, в том числе такие, когда физическое расстояние не принимается во внимание. Для анализа социальных сетей авторы предлагают модификацию формулы Латане в следующем виде:
В этой формуле учитываются все пользователи, упоминаемые u. Можно считать, что все они на него влияют. В следующей формуле учитывается влияние только наиболее упоминаемого и наименее упоминаемого пользователей:
Также можно учитывать влияние только наиболее упоминаемого и следующего за ним по частоте упоминания:
Здесь r(ui, uj) – расстояние между пользователями ui и uj. В формуле учитываются все пользователи, упоминаемые u, то есть считается, что все они на него влияют. Расстояние можно, например, задать отношением «подписчик–подписчик подписчика–подписчик подписчика подписчика» и т.д. Так как эти выкладки производятся относительно предпочтений пользователя u, уместно будет воспользоваться французской железнодорожной метрикой:
где l – заданный коэффициент; u – фиксированная выбранная точка, через которую обязательно должен проходить путь между ui и uj. Самое простое – подсчитать количество ребер. Можно, конечно, приписывать вес каждому ребру. Но, на взгляд авторов, здесь вес ребра не столь важен, так как в текущий момент времени пользователь u может не быть подписчиком, например, пользователя uj и поэтому находиться от него на далеком расстоянии, а в следующий момент времени уже стать подписчиком. Внешнее влияние, например влияние СМИ, также может быть учтено, если в основную формулу Латане добавить дополнительное слагаемое
Обычно внешний источник также моделируется как агент, но «вне окружающей среды» и с расстоянием 1 до каждого агента ввиду своей «вездесущей» природы. Величина SMi меняется в зависимости от агента, так как каждый человек испытывает различное давление СМИ. Эта величина аналогична иногда рассматриваемой «величине доверия» агента к сообщениям, получаемым из внешних источников. Для социальных сетей аналогом СМИ можно считать хэштеги и внешние ссылки. Соответственно получаем формулу
в которой учитываются все пользователи, упоминаемые u, и все хэштеги. Аналогично получаем формулу, в которой учитываются все пользователи и внешние ссылки в Интернете, упоминаемые пользователем u:
Обнаружение лидеров мнений По данным сайта Statista [6], социальная сеть ВКонтакте насчитывает 55 млн активных российских пользователей, Twitter – 8,5 млн человек [7]. Среди жителей Казахстана на долю ВКонтакте приходится 3,8 млн пользователей, Twitter используют 300 тысяч человек [8]. Количество пользователей социальных сетей постоянно увеличивается. Для сравнения: Twitter сейчас насчитывает 236 млн пользователей во всем мире [9]. Просматривать и обрабатывать огромные потоки информации, которые постоянно обновляются, не только трудно, но и нерационально. По мнению авторов, сравнительно большая часть информации в социальных сетях представляет собой средство самовыражения, когда человек делает заметки для себя, не преследуя какие-то дополнительные цели типа рекламы, агитации и пр. Это предположение подтверждает официальная статистика [1], согласно которой 40 % всех твитов можно отнести к светской беседе. Вместе с тем следует особо рассматривать пользователей Twitter, которые являются официальными представителями группы людей в сети. Например, новостные каналы (радио, телевидение, пресса), рекламные агентства, различные организации, в том числе го- сударственного уровня, и так далее. В отличие от Twitter в сети ВКонтакте существует в явном виде понятие сообщества, то есть группы людей, объединенных интересами. Безусловно, некоторая часть аккаунтов, зарегистрированых как один самостоятельный пользователь ВКонтакте, в реальной жизни может управляться группой людей. Чтобы выбрать существенную информацию из большого объема разнородных данных, необходимы критерии, позволяющие анализировать самое важное. Таким образом можно ограничить число просматриваемых пользователей. Другими словами, хотелось бы просматривать только сравнительно популярных пользователей, которые формируют мнение остального большинства. Их называют лидерами мнений. Показателем популярности здесь может выступать количество подпис- чиков пользователя. Согласно новому закону о блоггерах (№ 97-ФЗ от 05.09.14), автор с аудиторией свыше 3 000 пользователей в сутки должен заноситься в спецреестр. Но большое количество подписчиков не является достаточно точным показателем того, что пользователь – лидер мнений. Количество публикуемых сообщений тоже важно, причем созданных самим пользователем, а не просто перепостов. Кроме того, необходимо учитывать реакцию аудитории в виде количества комментариев к собранному сообщению, количества лайков и ретвитов. Таким образом, пользователя Twitter, которого можно назвать лидером мнений, характеризует следующий набор величин в терминах извлекаемых нами данных: – количество подписчиков (followers_count); – количество самостоятельно созданных твитов (statuses_count); – количество репостов сообщения пользователя (retweet_count); – количество лайков, которые собрал твит пользователя (favorite_count). Вместо количества самостоятельно созданных твитов удобнее оперировать величиной, вычисляемой как отношение самостоятельно созданных твитов к общему количеству сообщений пользователя, то есть Заметим, что перед текстом твит-сообщения может присутствовать пометка RT, означающая, что сообщение создано не лично пользователем, а является перепостом уже существующего. Это позволяет точно вычислить величину ST. Количество репостов сообщения (retweet_ count) и количество лайков, которые собрал твит (favorite_count), являются характеристиками самого сообщения, а не его автора, поэтому не могут вносить непосредственный вклад в оценку популярности пользователя. Чтобы их учесть, можно, например, применить к каждой из этих характеристик алгоритм, аналогичный вычислению индекса Хирша [10]. В итоге количеству репостов сообщения пользователя будет соответствовать коэффициент c1, а количеству лайков, которые собрал твит пользователя, – коэффициент c2. Эти два коэффицианта уже могут использоваться в качестве критерия популярности пользователя. Лидера мнений в сети ВКонтакте характеризует следующий набор величин в терминах извлекаемых данных: – количество подписчиков (getProfiles().counters. followers); – количество друзей (getProfiles().counters.friends); – количество записей пользователя (getProfiles().counters.notes); – количество лайков, собранных записью пользователя (likes_count); – количество комментариев, собранных записью пользователя (comments_count). Следует отметить, что количество друзей в се- ти ВКонтакте – более важный признак популярности пользователя, чем количество подписчиков. В сети Twitter ситуация противоположная. В сети ВКонтакте дополнительной характеристикой сообщения является количество комментариев, которые собрала запись пользователя. К ней также можно применить алгоритм, аналогичный вычислению индекса Хирша [10]. В результате получим величину c3, которая вносит вклад при оценивании популярности пользователя. Программная реализация В процессе исследований был разработан программный комплекс, содержащий модули извлечения информации из социальных сетей, обработки, анализа и визуализации данных. Все модули реализованы на языке Python для широкого круга операционных систем, на которых может работать комплекс. Программный комплекс cодержит шесть модулей: извлечения данных, обработки данных, отслеживания изменений в пользовательских данных, анализа данных, построения графовых структур, визуализации данных. Модуль извлечения данных позволяет из- влекать данные из Twitter и ВКонтакте. Для доступа к данным в каждой из них используется интерфейс прикладного программирования (API), авторизация производится при помощи протоко- ла OAuth. При использовании одного компью- тера программа позволяет в сутки выполнять от 8 до 250 тысяч запросов в зависимости от того, к какой социальной сети осуществляется запрос, и от быстродействия оборудования и пропускной способности каналов. На данный момент модуль извлечения данных имеет возможность функционального расширения практически на любую социальную сеть. Для хранения извлеченных данных используются документо-ориентированная система управления БД MongoDB и сетевое журналируемое хранилище данных Redis. Все данные Redis хранит в виде словаря, в котором ключи связаны со своими значениями. Одно из важных отличий Redis от других хранилищ данных заключается в том, что значения этих ключей не ограничиваются строками. Поддерживаются следующие абстрактные типы данных: списки строк, множества строк (коллекции неповторяющихся несортированных элементов), сортированные множества строк (коллекции неповторяющихся элементов), упорядоченных по score (вещественное число), словари, в которых и ключи, и их значения – строки. Тип данных значения определяет, какие операции (команды) доступны для него. Хранилище данных Redis поддерживает такие высокоуровневые операции, как объединение и разность наборов, а также их сортировку [11]. Данные с любого сервера Redis могут реплицироваться произвольное количество раз. Репликация – механизм синхронизации содержимого нескольких копий объекта. В процессе репликации изменения, сделанные в одной копии объекта, могут быть распространены в другие копии. Но, чтобы избежать конфликтов, необходимо понимать, в каком порядке должны применяться обновления. При выгрузке информации из социальных сетей приходится иметь дело с очень большими объемами данных. Репликация как раз полезна в таких случаях. Высокая производительность Redis обусловлена тем, что все данные хранятся в оперативной памяти. Важными условиями при выборе БД были вариабельность структуры данных и возможность изменять структуру содержимого БД. Это вызвано тем, что на начальном этапе получалось большое количество неструктурированных данных и сама структура хранения данных постепенно вырабатывалась по мере их извлечения и исследования. Кроме того, в MongoDB имеются механизмы обработки данных Map Reduce и Aggregation framework, значительно ускоряющие обработку данных в самой БД для предоставления обрабатываемых данных в требуемом формате для последующего анализа. Такой формат организации и хранения данных наиболее подходит для слабоструктурированной информации, в том числе для извлекаемой из социальных сетей. В реализованном программном комплексе для извлечения данных используются различные параметры запуска в зависимости от социальной сети. Для извлечения данных из сетей Twitter и ВКонтакте используются параметры, приведенные в таблице. Модуль обработки данных сначала производит поиск хэштегов, упоминаний пользователей и ссылок, далее – нормализацию текста сообщений. Нормализация текста сообщений осуществляется в зависимости от настроек с помощью либо стеммера Портера [12] (для большей скорости обработки), либо морфологической нормализации на основе алгоритмов АОТ [13] с использованием библиотеки PyMorphy. Модуль слежения за пользовательскими данными позволяет отслеживать изменения, вносимые пользователями в настройки своего аккаунта. В модуле анализа данных используются различные алгоритмы кластеризации и классификации данных как самих пользователей и их связей, так и их сообщений.
В модуле построения графовых структур имеется возможность построения графов, отражающих связи пользователей, а также выгрузки данных в программное средство для работы с графами Gephi [14]. Выгрузка может осуществляться в виде csv-файлов или посредством http-протокола. Реализованы оба метода. В зависимости от настроек в Gephi есть возможность отображения вершин, ребер, меток (вершин и ребер), по необходимости можно менять их величину и расцветку, масштабировать изображение с различной степенью детализации, просматривать списки вершин и ребер, ранжировать их. В числе аналитических возможностей Gephi автоматическое вычисление таких характеристик, как диаметр графа, плотность графа, модулярность, средняя длина пути между любыми двумя вершинами, метрики авторитетности вершин HITS и PageRank, центральность по собственному вектору (eigenvector centrality), средний коэффициент кластеризации и пр. Модуль визуализации данных дает возможность на основе извлеченных данных строить графики зависимостей между различными показателями. Просмотр результатов работы программы Для извлечения данных о конкретном пользователе из Twitter необходимо указать имя пользова- теля и дополнительные параметры, описание которых приведено в таблице. Например, необходимо извлечь информацию о Бахыт Сыздыковой – бывшем депутате мажилиса Республики Казахстан. В Twitter она зарегистрирована под именем @bahytsyzdykova. Часть содержимого коллекции users, в частности, с данными о пользователе @bahytsyzdykova, можно увидеть по ссылке http://www. swsys.ru/uploaded/image/2015-4-dop/3.jpg. У каждого зарегистрированного пользователя ВКонтакте есть собственный ID (идентификационный номер), который присваивается странице во время регистрации. Для запуска извлечения данных о пользователе из сети ВКонтакте необходимо указать этот ID, например 2237709. Часть содержимого коллекции messages можно увидеть по ссылке http://www.swsys.ru/uploaded/ image/2015-4-dop/4.jpg. При помощи запросов к БД можно осуществлять поиск по текстам сообщений, именам пользователей и другим сведениям среди тех данных, которые уже были извлечены. Например, при помощи запроса к БД db.messages.find({source:"vk"}) можно просматривать сообщения, извлеченные только из сети ВКонтакте. Описание извлекаемых данных В зависимости от социальной сети можно извлечь четыре типа объектов: User, Message, SocialObject, ContentObject, каждый из которых хранится в своей коллекции в MongoDB. Из Twitter извлекаются только объекты User и Message, из ВКонтакте – все четыре типа. Объекты типа User характеризуют пользователей социальной сети. Они находятся в коллекции users и имеют различные поля в зависимости от ресурса. Однако для Twitter и ВКонтакте имеются и схожие поля: source – собственно имя ресурса (ttr – Twitter, vk – ВКонтакте); name и <[first, last, middle]>_name – имя пользователя, которое он указал при регистрации; sn_id – идентификатор пользователя в социальной сети; status – последнее его сообщение (либо его состояние, которое он указал в графе «Что с вами происходит?»); birthday – дата рождения; screen_name – ник; update_date – время сохранения в БД и время последнего просмотра; [followers, friends]_count – количество подписчиков и друзей пользователя соответственно; verified – проверенный ли пользователь; в некоторых случаях это ответ на email, посланный при регистрации, в иных – проверка модератором на реальность имени и прочего. Имеются около 18 видов полей, описывающих пользователя Twitter. Приведем лишь некоторые наиболее важные из них: follow_request_sent – отправлен ли запрос на подписку этому пользователю (true/false); time_zone – временная зона; update_date – время последнего обращения системы к данным этого пользователя; protected – пользователь скрывает свои твиты, твиты показываются только его друзьям и подписчикам; listed_count – количество публичных листов, в которых состоит данный пользователь; statuses_count – количество сообщений пользователя; description – информация, которую пользователь написал о себе; favourites_count – количество избранных объектов у пользователя; url – ссылка, которую указал пользователь в своем описании; created_at – когда был создан аккаунт; default_profile – настроил ли пользователь свой аккаунт (дополнительной индивидуальностью, к примеру, картинкой в фоне); following – читает ли текущий бот искомого пользователя. Объекты типа Message характеризуют сообщения, оставленные пользователем в сети. 1) status – последнее сообщение пользователя: favorited – в избранном ли это сообщение у бота; text – текст сообщения; favorite_count – количество пользователей, которые добавили это сообщение себе в избранное; lang – язык текста; created_at – когда создано сообщение; retweeted – было ли переслано сообщение; coordinates – координаты места, откуда было отправлено сообщение; source – ресурс, с которого было создано сообщение; retweet_count – количество пересылок (репостов) сообщения; entities – сущности (которые есть также в со- общениях); все атрибуты этого объекта являются массивами, и каждый элемент является объектом, который содежит информацию о позиции в тексте: symbols : массив символов; user_mentions : массив пользователей, упоминаемых в тексте сообщения; hashtags : массив хэштегов; urls : массив ссылок; 2) lang – основной язык пользователя. Приведем поля для описания объекта типа User из ВКонтакте. 1. Поле city – выдается id города, указанного у пользователя в разделе «Контакты». Название города по его id можно узнать при помощи метода getCities. Если город не указан, то при приеме данных в формате XML в узле отсутствует тег city. 2. Поле country – выдается id страны, указанной у пользователя в разделе «Контакты». Название страны по ее id можно узнать при помощи метода getCountries. Если страна не указана, то при приеме данных в формате XML в узле отсутствует тег country. 3. Поле online – показывает, находится ли этот пользователь сейчас на сайте. Поле доступно только для метода friends.get. Возвращаемые значения: 1 – находится, 0 – не находится. Если пользователь использует мобильное приложение либо мобильную версию сайта, будет возвращено дополнительное поле online_mobile. lists – список, содержащий id списков друзей, в которых состоит текущий друг пользователя. Метод получения id и названий списков: friends.getLists. Поле доступно только для метода friends.get. Если текущий друг не состоит ни в одном списке, то при приеме данных в формате XML в узле отсутствует тег lists. screen_name – возвращает короткий адрес страницы (возвращается только имя адреса, например andrew). Если пользователь не менял адрес своей страницы, возвращается 'id'+uid, например id35828305. has_mobile – показывает, известен ли номер мобильного телефона пользователя. Возвращаемые значения: 1 – известен, 0 – не известен. Рекомендуется перед вызовом метода secure.sendSMSNotification. contacts – возвращает поля: mobile_phone – мобильный телефон пользователя; home_phone – домашний телефон пользователя; education – возвращает код и название университета пользователя, а также факультет и год окончания; universities – список высших учебных заведений, в которых учился текущий пользователь; schools – список школ, в которых учился текущий пользователь. can_post – разрешено ли оставлять записи на стене у данного пользователя. can_see_all_posts – разрешено ли текущему пользователю видеть записи других пользователей на стене данного пользователя. can_write_private_message – разрешено ли написание личных сообщений данному пользователю. activity – возвращает статус, расположенный в профиле, под именем пользователя. last_seen – возвращает объект, содержащий поле time, в котором содержится время последнего захода пользователя. relation – возвращает семейное положение пользователя: 1 – не женат/не замужем; 2 – есть друг/есть подруга; 3 – помолвлен/помолвлена; 4 – женат/замужем; 5 – все сложно; 6 – в активном поиске; 7 – влюблен/влюблена. 4. Поле counters – возвращает количество различных объектов у пользователя. Поле возвращается только в методе getProfiles при запросе информации об одном пользователе. Данное поле является объектом, который содержит следующие поля: albums – количество фотоальбомов; videos – количество видеозаписей; audios – количество аудиозаписей; notes – количество заметок; friends – количество друзей; groups – количество сообществ; online_friends – количеcтво друзей онлайн; mutual_friends – количество общих друзей (если запрашивается информация не о текущем пользователе); user_videos – количество видеозаписей с пользователем; followers – количество подписчиков. Если запрашивается информация не о текущем пользователе, то отсутствие полей friends, on- line_friends, mutual_friends, user_photos в объекте означает, что информация по ним скрыта соответствующими настройками приватности у запрашиваемого пользователя. Если при запросе данного поля оно отсутствует в ответе, то это означает, что текущий пользователь находится у запрашиваемого пользователя в черном списке. 5. Поле wall_comments – разрешено ли комментирование стены. Если комментирование стены отключено, то комментарии на стене не отображаются. 6. Поле relatives – возвращает список родственников текущего пользователя в виде объектов, содержащих поля uid и type. type может принимать одно из следующих значений: grandchild, grandparent, child, sibling, parent. 7. Поля interests, movies, tv, books, games, about – позволяют получить профильную информацию о пользователе. 8. Поле connections – позволяет получить информацию об аккаунтах пользователя на других сервисах. При указании этого поля будут приходить следующие ключи в случае наличия соответствующих записей: twitter, facebook, facebook_name, skype, livejounal. Под объектами типа ContentObject понимаются некоторые контентные объекты, такие как фотографии, видео, обсуждения групп, имеющиеся в сети ВКонтакте. Все эти объекты имеют различные наборы атрибутов в зависимости от типа объекта, к каждому из них могут привязываться объекты типа Message посредством информации из атрибута comment_for. Также для каждого такого объекта определены слеующие поля: sn_id – уникальный идентификатор записи; user – ссылка на пользователя, загрузившего эту запись; text – что пользватель написал про эту запись; created_at – когда была создана запись; views_count – количество просмотров в некотором случае; comments_count – количество комментариев; likes_count – количество лайков; video_id – идентификаторы видеоконтента в сети vk; photo_id – идентификаторы фото контента в сети vk; wall_post_id – идентификаторы записей на стене пользователя vk; type – тип [wall_post, video, photo]. Объекты типа SocialObject представляют сообщества пользователей, такие как группы, публичные страницы, встречи, и различаются свойством type. Для каждого объекта SocialObject определены следующие поля: sn_id – идентификатор группы, страницы, встречи в социальной сети vk; в некоторых случаях уместно его применение в обратном значении, таком как get_photos; private – закрыто ли это сообщество для сторонних пользователей (чтобы вступить, требуется отправить запрос администратору этого сообщества); name – видное всем пользователям имя сообщества; screen_name – «ник» сообщества; type – тип сообщества (может быть group, page, event); source – всегда равен vk. Связи между двумя пользователями либо между пользователем и сообществом (для социальной сети ВКонтакте) ввиду их большого количества хранятся в Redis для последующего быстрого извлечения. Каждая связь имеет определенный тип и соединяет между собой либо двух пользователей, либо пользователя и сообщество. Таким образом, связь – это тройка L = , где B – идентификатор начального пользователя; U – идентификатор конечного пользователя (либо сообщества, то есть группы пользователей); T – тип связи. Связи между пользователями в социальной сети Twitter имеют только 2 типа: freind и follower. Связи между двумя пользователями социальной сети ВКонтакте могут быть следующими: friend, follower, like, comment, mentions. Типы связей между пользователем и сообществом: member, admin, subscribe, request, invitation. На основании изложенного сделаем следующие выводы. В процессе анализа социальных сетей решается довольно большой круг задач и применя- ются методы из различных областей знаний. Часто решение задач одного класса связано с решением задач другого класса, поэтому к их решению целесообразно подходить комплексно. Для этого, безусловно, необходимы новые методы, алгоритмы, введение новых характеристик, которые помогли бы в решении возникающих вопросов. В рамках исследования был разработан программный комплекс для анализа данных из со- циальных сетей. Он состоит из шести модулей: извлечения, обработки данных, отслеживания изменений пользовательских данных, анализа данных, построения графовых структур и модуля визуализации данных. В данной работе также приведено довольно подробное описание извлекаемых данных. Ясно, что количество получаемой информации очень большое. При использовании распределенной системы извлечения и обработки данных объем возрастает еще больше. Поэтому сначала необходимо из всей информации выделить ту, которую можно было бы достаточно эффективно обработать и которая представляла бы интерес в соответствии с поставленными целями. К примеру, необходимо выяснить, насколько большое влияние оказывает на человека его окружение. Для решения этой задачи предлагается применить к социальным сетям теорию динамического социального влияния, предложенную Латане. Задача определения количества влияния на пользователя со стороны других пользователей непосредственно связана с задачей обнаружения лидеров мнений – относительно популярных пользователей, формирующих мнение большинства. Благодаря им информация распространяется бы- стрее и, соответственно, воздействует на более многочисленную аудиторию. Лидера мнений характеризуют следующие величины: количество подписчиков или друзей, количество созданных сообщений, количество лайков, репостов и комментариев, которые собирают записи пользователя. Эти характеристики позволяют более точно оценить популярность пользователя. Проведенные испытания созданного програм- много комплекса показали его корректную работу. Извлекаемые из сетей данные весьма интересны. Однако необходимы еще более глубокое осмысление получаемых результатов и дополнительные исследования для того, чтобы с помощью програм- много комплекса получать и анализировать действительно наиболее важную информацию. Литература 1. Twitter. URL: https://en.wikipedia.org/wiki/Twitter (дата обращения: 1.07.2015). 2. Nowak A., Szamrej J., Latané B. From private attitude to public opinion: a dynamic theory of social impact. Psychological Review, 1990, vol. 97, pp. 362–376. 3. Latané B. The psychology of social impact. American Psychologist, 1981, vol. 36, pp. 343–356. 4. Роджерс Э., Агарвала-Роджерс Р. Коммуникации в организациях. М.: Экономика, 1980. 178 c. 5. Крючков В.Н., Мурзин Ф.А., Нартов Б.К. Исследование связей в коллективах и сетях ЭВМ на основе анализа предпочтений // Проблемы конструирования эффективных и надежных программ. 1995. C. 136–141. 6. Number of monthly active VKontakte users via desktop connections in Russia from December 2012 to December 2014. The Statistics Portal. URL: http://www.statista.com/statistics/425423/ number-of-monthly-active-vkontakte-users (дата обращения: 1.07.2015). 7. Top social networks in Russia: latest numbers and trends. Russian Search. URL: http://www.russiansearchtips.com/2015/01/ top-social-networks-russia-latest-numbers-trends (дата обращения: 1.07.2015). 8. Сколько тратят казахстанские компании на рекламу в соцсетях. Forbes Kazakhstan. URL: http://forbes.kz/process/internet/skolko_tratyat_kazahstanskie_kompanii_na_reklamu_v_sotssetyah (дата обращения: 1.07.2015). 9. Number of monthly active international Twitter users from 2nd quarter 2010 to 1st quarter 2015. The Statistics Portal. URL: http://www.statista.com/statistics/274565/monthly-active-international-twitter-users (дата обращения: 1.07.2015). 10. Hirsch J.E. An index to quantify an individual's scientific research output. Proc. Natl Acad. Sci. USA. 2005, no. 102 (46), pp. 16569–16572. 11. Redis. URL: https://ru.wikipedia.org/wiki/Redis (дата обращения: 1.07.2015). 12. Willett P. The Porter stemming algorithm: then and now. Program: Electronic Library and Information Systems, 2006, vol. 40, no. 3, pp. 219–223. 13. Автоматическая обработка текста. URL: http://aot.ru (дата обращения: 1.07.2015). 14. Gephi, an open source graph visualization and manipulation software. URL: https://gephi.org (дата обращения: 1.07.2015). |
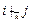 означает, что i предпочтительнее j, по мнению k. Критерии предпочтительности могут быть самыми разными: профессионализм, который можно разбить на разные виды деятельности, что породит спектр новых критериев; умение руководить людьми; коммуникабельность; восприимчивость к инновациям; психологическая устойчивость и т.д. На базе этих отношений складывается неформальная структура коллектива, важность выявления которой в ряде случаев не требует комментариев.
означает, что i предпочтительнее j, по мнению k. Критерии предпочтительности могут быть самыми разными: профессионализм, который можно разбить на разные виды деятельности, что породит спектр новых критериев; умение руководить людьми; коммуникабельность; восприимчивость к инновациям; психологическая устойчивость и т.д. На базе этих отношений складывается неформальная структура коллектива, важность выявления которой в ряде случаев не требует комментариев.
 , где Ii – количество социального давления, направленного на агента i; Oi – мнение i-го агента (±1) по отношению к данному вопросу, значение +1 соответствует поддержке, а –1 – сопротивлению предложению; Si – сила социального влияния (Si ³ 0); b – сопротивляемость агента к изменениям (b>0); dij – расстояние между агентами i и j (dij ³ 1); a – степень ослабления расстояния (a³0); N – общее число взаимодействующих агентов.
, где Ii – количество социального давления, направленного на агента i; Oi – мнение i-го агента (±1) по отношению к данному вопросу, значение +1 соответствует поддержке, а –1 – сопротивлению предложению; Si – сила социального влияния (Si ³ 0); b – сопротивляемость агента к изменениям (b>0); dij – расстояние между агентами i и j (dij ³ 1); a – степень ослабления расстояния (a³0); N – общее число взаимодействующих агентов.

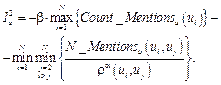
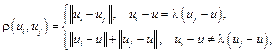
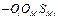 , где SMi – сила влияния внешних источников на агента i (SMi > 0); OM – мнение внешнего источника (±1). Для учета влияния масс-медиа Латане [2, 3] получил итоговую формулу
, где SMi – сила влияния внешних источников на агента i (SMi > 0); OM – мнение внешнего источника (±1). Для учета влияния масс-медиа Латане [2, 3] получил итоговую формулу .
.

 , где ST – количество самостоятельно созданных твитов; TT – общее количество сообщений пользователя.
, где ST – количество самостоятельно созданных твитов; TT – общее количество сообщений пользователя.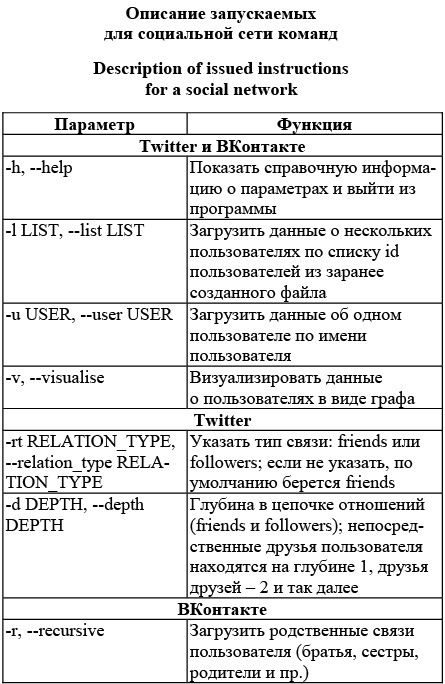
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4089&lang= |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
| Статья опубликована в выпуске журнала № 4 за 2015 год. [ на стр. 188-197 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: