Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Реализация процесса поиска решения по модифицированному алгоритму Rete для нечетких экспертных систем
Аннотация:В работе рассматриваются основные понятия теории нечетких продукционных экспертных систем. Нечеткие продукционные экспертные системы базируются на наборе правил, представленном в терминах лингвистических переменных. В качестве механизма нечеткого вывода предлагается разработанная модификация алгоритма Rete для нечеткой базы правил. Разработанная модификация обеспечивает ускорение процесса работы системы за счет однократного вычисления одинаковых условий в правилах, а также позволяет формулировать правила и заключения на ограниченном естественном языке. Разработанная формальная модель дерева решений модифицированного алгоритма Rete для нечеткой продукционной базы знаний состоит из множеств вершин-условий, вершин-следствий, отношений между вершинами и отношений для описания правил нечеткой экспертной системы. Созданный алгоритм обрабатывает правила нечеткой базы правил и преобразует их в формат формальной модели дерева решений модифицированного алгоритма Rete. На каждом этапе работы алгоритма выполняется построение нечетких оценок истинности вершин дерева решений с помощью нечетких операторов, что позволяет формулировать условия и следствия в базе правил, а также результаты работы алгоритма поиска решения на ограниченном естественном языке. Также одинаковые условия объединяются при построении дерева решений, что обеспечивает ускорение обработки дерева решений по сравнению с последовательным просмотром правил экспертной системы. Рассмотрен пример работы нечеткой продукционной экспертной системы, функционирующей на основе предложенной модификации алгоритма Rete, показана эффективность предложенного метода.
Abstract:The paper considers the basic concepts of fuzzy production expert systems. Fuzzy production expert systems are based on a set of rules presented in terms of linguistic variables. The authors suggest the developed Rete algorithm modification for a fuzzy rule base as a fuzzy inference tool. This modification accelerates systems operation due to a single computing of the same conditions in the rules. It also formulates the rules and conclusions in the limited natural language. The modified Rete algorithm formal decision tree model for a fuzzy production knowledge base consists of a set of vertex-conditions, vertexsolutions, the relationship between vertices and relations to describe the fuzzy expert system rules. The created algorithm processes the rules from the fuzzy rule base and converts them into the decision tree modified Rete algorithm formal model. Rete algorithm modification is different from a classical algorithm as it is used for fuzzy variables. Therefore, each stage of the algorithm includes building the decision tree vertices fuzzy truth values using fuzzy operators. This allows formulating the conditions and consequences in the rule base, as well as the solutions in the limited natural language. The same conditions are combined during decision tree construction. It accelerates decision tree processing comparing to sequential viewing of expert system rules. The paper describes an operating example of the production fuzzy expert system, which works on the basis of the proposed Rete algorithm modification. It also displays the effectiveness of the proposed method.
| Авторы: Михайлов И.С. (fr82@mail.ru) - Национальный исследовательский университет «Московский энергетический институт», Москва, Россия, кандидат технических наук, Зо Мин Тайк (zawgyi86@gmail.com) - Национальный исследовательский университет «Московский энергетический институт» (аспирант), Москва, Россия | |
| Ключевые слова: модификация алгоритма rete, алгоритм rete, нечеткая база правил, нечеткая экспертная система |
|
| Keywords: rete algorithm modification, rete algorithm, fuzzy rule base, fuzzy expert system |
|
| Количество просмотров: 8869 |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
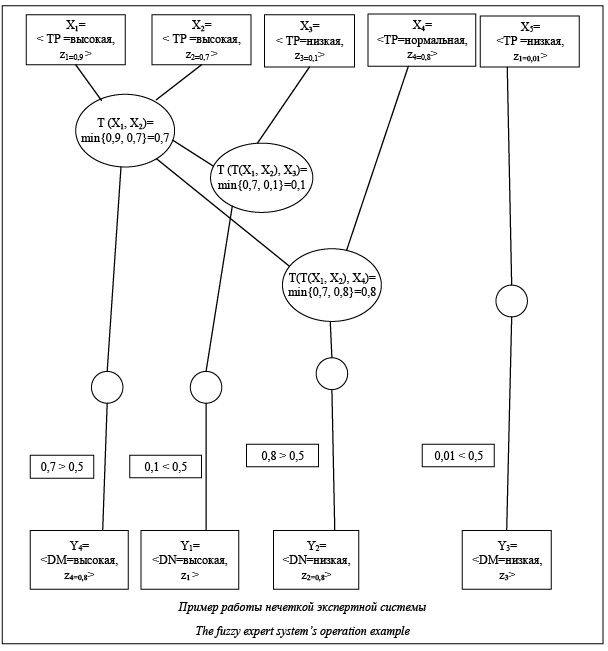
Использование экспертных систем для решения объемных, трудно формализуемых задач в различных предметных областях приобретает все большую актуальность. Эти задачи характеризуются, как правило, отсутствием или сложностью формальных алгоритмов решения, неполнотой и нечеткостью исходной информации, нечеткостью достигаемых целей [1]. Данные особенности обусловили необходимость использования знаний в процессе решения этих задач и разработки экспертных систем, осуществляющих сбор и управление этими знаниями, принимающими решения об оптимальном способе достижения целей в условиях неполноты и нечеткости. При этом знания должны поступать в систему от человека-эксперта в предметной области. Знания человека-эксперта о решении задач в таких условиях также имеют нечеткий характер. Для их формализации успешно применяется аппарат теории нечетких множеств и нечеткой логики [2]. Нечеткие понятия в данном случае формализуются в виде нечетких и лингвистических переменных, а нечеткость действий в процессе принятия решения – в виде нечетких алгоритмов. Экспертные системы, способные формально представлять нечеткую информацию и обрабатывать ее в рамках нечетких алгоритмов, получили название нечетких экспертных систем [3]. Наиболее широко применяемой моделью знаний экспертных систем является продукционная модель в силу своей простоты обработки и понятности конечному пользователю [4]. Нечеткие экспертные системы базируются на наборе правил, в которых используются лингвистические переменные и нечеткие отношения для описания состояния и поведения исследуемого объекта [5]. Правила, представленные в таком виде, наиболее приближены к естественному языку, поэтому нет необходимости в услугах отдельного специалиста – инженера по знаниям для создания и редактирования правил [6]. Они могут быть отредактированы самим экспертом практически без специальной подготовки [7]. В данной работе поставлена задача разработки и реализации модифицированного алгоритма Rete для нечеткой продукционной базы правил, а также разработки нечеткой продукционной экспертной системы, механизм вывода которой будет функционировать на основе созданной модификации этого алгоритма. Необходимо создать формальную модель дерева решений модифицированного алгоритма Rete. При работе решателя нечеткой продукционной экспертной системы все правила из базы правил применяются последовательно. При этом заново анализируются все условия, которые содержатся в данных правилах. Разрабатываемый алгоритм позволит проверять каждое условие только один раз. Таким образом будет обеспечено ускорение работы решателя нечеткой ЭС и, следовательно, быстрее будет найдено решение. Нечеткая экспертная система с использованием формальной модели дерева решений модифицированного алгоритма Rete Нечеткая экспертная система использует для вывода решения вместо булевой логики совокупность нечетких функций принадлежности и правил. Поведение исследуемой системы описывается на ограниченном естественном языке в терминах лингвистических переменных [8]. Входные и выходные параметры системы рассматриваются как лингвистические переменные, а описание процесса задается набором правил [9]. Формальная модель базы правил разработанной экспертной системы имеет вид L1 : A11 и/или A2 и/или ... и/или A1m® B11 и/или ... и/или B1n, L2 : A21 и/или A22 и/или ... и/или A2m® B21 и/или ... и/или B2n, (1) … Lk : Ak1 и/или Ak2 и/или ... и/или Akm® Bk1 и/или ... и/или Bkn, где Ai,j, i = 1, 2, …, k, j = 1, 2, …, m – нечеткие высказывания, определенные на значениях входных лингвистических переменных; Bi,j, i = 1, 2, …, k, j = 1, 2, …, n – нечеткие высказывания, определенные на значениях выходных лингвистических переменных. Эта совокупность правил носит название нечеткой базы знаний [3]. В общем случае нечеткий вывод решения выполняется за четыре этапа: фаззификация, непосредственный нечеткий вывод, композиция и дефаззификация. Этап фаззификации заключается в преобразовании с помощью функций принадлежности µ точных входных данных в нечеткие значения лингвистических переменных. На этапе непосредственного нечеткого вывода вычисляется значение истинности для условий каждого правила по правилам вычисления Т-норм, Т-конорм и отрицаний. Вычисления осуществляются на основе набора правил нечеткой базы знаний. Этап композиции состоит в формировании значений выходных лингвистических переменных для каждого сработавшего правила. На этапе дефаззификации выполняется преобразование нечетких значений выходных лингвистических переменных в точные значения. В данной работе вычисления T-норм и T-конорм осуществляются по правилам TM(x, y) = = min{x, y} и ^M(x, y) = max{x, y}. Отрицание утверждения вычисляется по правилу классического отрицания Ø(x) = 1 – x. В настоящее время алгоритм Rete является эффективным алгоритмом сопоставления с образцом для продукционных экспертных систем [10]. Rete стал основой многих популярных экспертных систем, включая CLIPS, Jess, Drools, BizTalk Rules Engine и Soar. Классический алгоритм работы экспертных систем заключается в проверке применимости каждого правила вывода к каждому факту базы знаний при необходимости его выполнения и переходе к следующему правилу с возвратом в начало базы знаний в случае исчерпания всех правил [11]. Даже для небольшого набора правил и фактов такой метод работает неприемлемо медленно. Алгоритм Rete обеспечивает более высокую эффективность [12]. При использовании Rete экспертная система выполняет формирование специального графа, узлам которого соответствуют части условий правил. Путь от корня до листа образует полное условие некоторой продукции. В процессе работы каждый узел хранит список фактов, соответствующих условию. При добавлении или модификации факта он обрабатывается графом, при этом отмечаются узлы, условиям которых данный факт соответствует. При выполнении полного условия правила, когда система достигает листа графа, правило выполняется. В большинстве случаев скорость работы систем с использованием алгоритма Rete возрастает на порядки. Однако данный алгоритм реализован для экспертных систем с классическими продукционными правилами. В работе рассматривается модификация алгоритма Rete для работы с нечеткой базой правил. Граф модификации Rete-алгоритма для нечетких экспертных систем формируется таким образом, что в каждом случае проверяется не точное значение условия правила, а значения лингвистических переменных в данном правиле. Формальная модель дерева решений будет иметь вид M = (X, R, P, Y), (2) где X – множество вершин-условий графа; Y – множество вершин-следствий графа; R – множество отношений между вершинами; P – множество отношений для описания правил нечеткой экспертной системы. Каждая вершина-условие представляет собой условия из правил нечеткой базы знаний: X = {
|
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4083&lang= |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
| Статья опубликована в выпуске журнала № 4 за 2015 год. [ на стр. 142-147 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: