Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Построение корпуса текстов для настройки тонового классификатора
Аннотация:В работе представлен инструмент для сбора и анализа корпуса коротких текстов. Первый модуль инструмента – сбор текста (парсер). Второй модуль отвечает за обработку корпуса и состоит из двух частей: морфологической раз-метки корпуса и составления общетематического словаря эмоциональной лексики (извлечения списков наиболее часто употребляемых слов и словосочетаний с целью выделения значимых слов для положительных и отрицательных текстов); при этом для каждого слова и словосочетания рассчитывается набор статистических характеристик, свойственных для положительной или отрицательной окраски текста. Таким образом, в работе описываются инструмент для сбора и анализа корпуса коротких текстов, а также собранный с помощью этого инструмента корпус коротких текстов современного русского языка, доступный для публичного ознакомления. Более того, на основе корпуса текстов был построен словарь эмоциональной лексики.Для каждого термина или словосочетания в словаре рассчитан статистический вес значимости слова для класса положительных или отрицательных текстов. Полученные результаты используются для построения и тренировки тонового классификатора.
Abstract:The paper presents a tool for short texts corpus collecting and analyzing. The first module of the tool is a text collector (parser). The second module is a corpora processingwhich consists of two stages: corpus morphological tagging – in order to identify characteristic features of each o f the three classes of short texts; constructing a vocabulary of emotional unigram and bigrams based on the corpus. The statistical weight of each unigram and bigram was calculated depending on positive or negative class of text. Developed vocabulary does not belong to any predefined object domain. Thus, this paper presents a tool for collecting corpus. Also a corpus of modern Russian language short texts was constructed using the developed tool. It is available for public inspection. The corpus is intended to train a sentiment classifier that sorts general-topic texts into two and three classes: “positive” and “negative”; “positive”, “negative” and “neutral”. In addition, the corpus was a base for creating an emotional vocabulary. A statistical weight of the word meaning for positive or negative texts class was calculated for each term or phrase in the dictionary. The results are used to build and train a sentiment classifier.
| Авторы: Рубцова Ю.В. (yu.rubtsova@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (аспирант), Новосибирск, Россия | |
| Ключевые слова: морфологическая разметка, анализ данных социальных сетей, тоновая классификация, классификация текстов, корпусная лингвистика |
|
| Keywords: morphology tagging, social networks data analysis, sentiment classification, text categorization, corpus linguistics |
|
| Количество просмотров: 18288 |
Версия для печати Выпуск в формате PDF (12.50Мб) Скачать обложку в формате PDF (0.36Мб) |
Уже несколько лет особое внимание исследователей уделяется задаче автоматического извлечения и анализа отзывов и мнений. Зарубежные ученые публикуют труды, в которых заявляют точность классификации текстов по тональности более 82 % [1, 2]. В России в 2012 году на международной конференции по компьютерной лингвистике «Диалог» были подведены итоги двух соревнований между системами автоматического анализа текста: синтаксических анализаторов (парсеров) и систем анализа тональности текстов (sentiment analysis). Соревнование по анализу тональности было проведено совместно с Российским семинаром по оценке методов информационного поиска (РОМИП) [3].
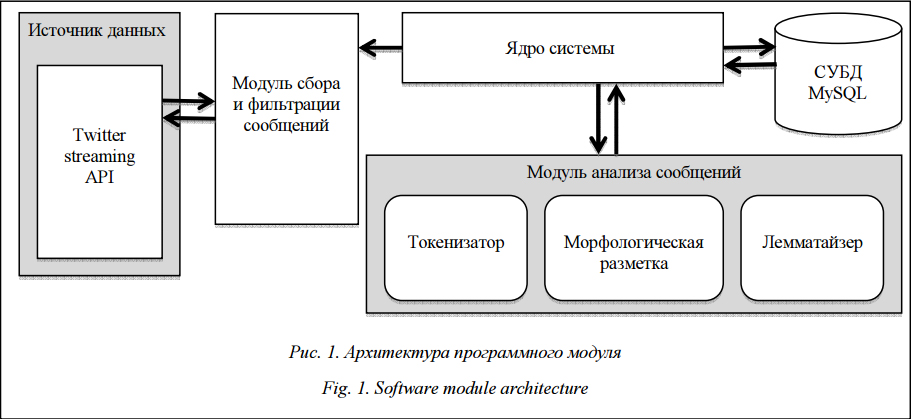
Живой интерес к задаче автоматического извлечения и анализа отзывов связан с тем, что, с одной стороны, пользователи ежедневно публикуют сотни тысяч мнений в социальных сетях, блогах, на форумах, специализированных площадках. С другой, эти мнения необходимо обрабатывать в полном объеме. Поэтому системы, автоматически распознающие мнение в текстах, востребованы специалистами, разрабатывающими рекомендательные системы, экспертные системы, человеко-машинный интерфейс для программного обеспечения, маркетологами и аналитиками, проводящими маркетинговые исследования, а также политологами, оценивающими тональность новостей и др. В работе описываются разработка програм- много комплекса (парсера) и реализация метода построения и первичного анализа корпуса размеченных текстов, предназначенного для тренировки классификатора по тональности, который автоматически классифицирует общетематические тексты на два и три класса: положительные и отрицательные тексты; положительные, нейтральные и отрицательные. После сбора коллекции текстов работа с корпусом включает два этапа: – морфологическая разметка корпуса с целью выявления характерных признаков для каждого из трех классов текстов; – составление общетематического словаря эмоциональной лексики: извлечение списков наиболее часто употребляемых слов и словосочетаний с целью выделения значимых слов для положительных и отрицательных текстов; при этом для каждого слова и словосочетания рассчитывается набор характеристик и производится взвешивание согласно статистическим мерам. Обзор существующих корпусов и текстовых коллекций для задачи классификации текстов по тональности Одним из средств организации текстовой информации для ее последующего автоматизированного анализа является создание корпусов текстов. Корпус текстов – это коллекция категорированных текстов, собранных по определенной мето- дике и представленных в электронном виде. Ка- тегоризация текстов может проводиться как по интегральным характеристикам каждого текста (например принадлежность текста к определенной тематике), так и по специфическим характерис- тикам отдельных терминов (например слово- формы, леммы, морфемы). Более того, эта коллекция текстов должна быть организована в виде базы данных, чтобы иметь возможность практического использования корпуса в целях научного анализа. В последние годы проводится достаточно много исследований в области классификации текстов согласно их тоновой окрашенности. Много работ посвящено тоновой классификации отзывов на продукты и фильмы [1, 4], а также анализу блогов или новостей. Другими словами, изучались достаточно длинные тексты, принадлежащие некоторой заранее определенной предметной области. Иногда для работы использовались тексты отзывов, размеченные самим автором отзыва по пяти- или десятибалльным шкалам [2]. Таким образом, существующие в открытом доступе коллекции на русском языке, подготовленные для задачи автоматической классификации отзывов на два или три класса, объединены одной тематикой, например, коллекция отзывов о фильмах с оценками пользователей (РОМИП 2011, [3]). Для предыдущих исследований [1–4] разрабатывались тренировочные корпусы текстов, обладающие следующими параметрами: – корпусы отзывов с оценками, вручную проставленными автором отзыва; – узкотематические корпусы отзывов (отзывы на фильмы или на книги); – корпусы общезначимых новостей (длинные тексты, состоящие из нескольких абзацев). Однако интернет-пользователи не всегда пишут конструктивные и структурированные отзывы на товары или услуги, детально обдумывая плюсы и минусы, выставляя оценки. Значительно чаще пользователь оставляет спонтанный эмоциональный отзыв в социальных сетях или микроблоге. Распространение смартфонов еще больше способствует увеличению сиюминутных отзывов и эмоциональных заметок в социальных сетях. Например, человек после просмотра фильма, который ему не очень понравился, с помощью смартфона тут же, не выходя из кинотеатра, может предупредить своих друзей о том, что на этот фильм не стоит тратить время. Короткие заметки пишутся чаще и потенциально имеют большее влияние на друзей пользователя, чем развернутые рецензии незнакомых людей. Поэтому для товаров, услуг, медийных персон и значимых событий важно собирать, отслеживать и классифицировать отзывы не только со специализированных сайтов-отзывов, но и из социальных сетей. Все доступные коллекции на русском языке являются коллекциями отзывов, принадлежащими одной определенной предметной области, но не общетематическими коллекциями коротких текстов (микроблогов) или сообщений из социальных сетей. Поэтому для задачи классификации текстов из социальных сетей по тональности был собран корпус коротких текстов на основе микроблоговой платформы twitter. Twitter – это социальная сеть и сервис микроблогинга, который позволяет пользователям писать сообщения в реальном времени. Зачастую сообщение пишется с мобильного устройства прямо с места событий, что добавляет сообщению эмоциональности. Из-за ограничения платформы длина твиттер-сообщения не превышает 140 символов. В связи с этой особенностью сервиса (короткие сообщения публикуются в реальном времени) люди используют аббревиатуры, сокращают слова, используют смайлики, пишут с орфографическими ошибками. Так как twitter имеет особенности социальной сети, его пользователи могут активно выражать свое мнение относительно разнообразных тем: от качества мультиварок до экономических и политических событий в мире. Классификацию на уровне коротких фраз и выражений, а не абзацев или целых документов, проводили Wilson, Wiebe и Hoffmann [5]. В своей работе авторы показали, что важно определить окраску (положительная или отрицательная) отдельно взятого предложения, а не всего текста. В длинном документе мнение автора об объекте может меняться с положительного на отрицательное и наоборот; автор может отрицательно высказываться о мелких недочетах, но в целом оставаться положительно настроенным по отношению к объекту. Другими словами, не всегда длинный документ или отзыв однозначно можно классифицировать как положительно или отрицательно окрашенный. Метод сбора корпуса текстов для задачи тоновой классификации Корпус собирается на основе русскоязычных постов микроблоговой платформы twitter. Корпус создается для решения задачи классификации текстов по тональности на 2 и 3 класса. Для тренировки тонового классификатора корпус должен быть размечен на положительную, нейтральную и негативную коллекции, каждая из которых содержит примерно одинаковое количество текстов. Корпус должен быть достаточно представительным, чтобы на его основе строить словарь эмоционально окрашенных терминов. «Достаточно представительный корпус» означает, что добавление новых твитов к коллекции повлечет за собой добавление очень небольшого числа новых терминов. Метод, описанный в [6], показал эффективность использования смайликов (специальных символов-иконок, обозначающих эмоции в письменных сообщениях) для автоматической классификации текстов на положительные и отрицательные. С высокой точностью можно определить эмоцию сообщения, если автор указал символ, обозначающий эмоции. Поэтому прежде всего были составлены словари символов, обозначающих положительное и отрицательное отношение автора. Для составления словарей символов, обозначающих эмоции, использовался ресурс Wikipedia (http://en.wikipedia.org/wiki/List_of_emoticons). Но не все символы, перечисленные в статье Wikipedia, вошли в словарь символов, например, символы ;) или :-p не вошли в словарь, так как не определяют однозначно эмоцию автора. Пример иконки, означающей положительную эмоцию, – :), негативную – :(. Так как длина сообщения ограничена 140 символами, было сделано допущение, что выражение эмоции в виде смайлика относится ко всему сообщению, а не к его отдельной части. В соответствии с письменным обозначением эмоций был произведен поиск позитивно и негативно окрашенных сообщений и сформированы две коллекции. Эти коллекции будут использованы для последующего анализа позитивно и негативно окрашенных сообщений и выявления закономерностей позитивного и негативного сообщения. Для формирования коллекции нейтральных сообщений были взяты сообщения новостных аккаунтов микроблогов.
Фильтрация коллекции. Для чистоты эксперимента была проведена фильтрация собранной коллекции: – из коллекции твитов удалены тексты, содержащие одновременно и положительные, и отрицательные символы эмоций; такие тексты нельзя автоматически отнести ни к коллекции положительных сообщений, ни к коллекции негативных; – удалены малоинформативные твиты, длина которых менее 40 символов.
– положительных сообщений (114 991 запись); – негативных сообщений (111 923 записи); – нейтральных сообщений (107 990 записей). Была построена БД текстов микроблогов для последующей обработки и анализа корпуса. Каждый текст в корпусе имеет следующие атрибуты: – дата публикации; – имя автора; – текст твита; – класс, к которому принадлежит текст (положительный, отрицательный, нейтральный); – количество добавлений сообщения в избранное; – количество ретвитов (количество копирований этого сообщения другими пользователями); – количество друзей пользователя; – количество пользователей, у которых пользователь в друзьях (количество фоловеров); – количество списков (листов), в которых состоит пользователь.
Для построения словаря эмоциональной лексики необходимо, чтобы коллекции документов содержали достаточно большое количество лемм. Несмотря на богатство и разнообразие русского языка, далеко не все слова используются для общения в социальных сетях. Одна из задач этой работы состояла в том, чтобы собрать достаточно представительный корпус для построения словаря эмоциональной лексики. Чтобы проверить, является ли корпус достаточно представительным, три коллекции объединили в одну, после чего было произведено вычисление количества уникальных терминов в зависимости от размера коллекции. Рисунок 3 показывает, что при небольшом количестве твитов добавление к коллекции новых сообщений влечет за собой увеличение числа уникальных терминов. Но после достижения цифры в 340 000 уникальных терминов добавление новых твитов к коллекции не влечет за собой значительного увеличения уникальных терминов. Таблица 1 Соотношение коллекций по их объемам в корпусе текстов, собранных на основе русскоязычных постов социальной сети Twitter Table 1 Correlation of collections according to their volumes in a text corpus based on Russian posts on Twitter
Морфологическая разметка текстов. Чтобы изучить влияние лингвистических признаков текста при классификации коротких текстов по тональной окрашенности, была произведена морфологическая разметка коллекций. Цель разметки корпуса – выявить закономерности распределения частей речи между «положительной» и «отрицательной» коллекциями. Существует несколько морфологических анализаторов для русского языка. Например, mystem – морфологический анализатор Яндекса, который угадывает нормальные формы слов, даже если этих слов нет в словаре системы [9]. Mystem не разрешает морфологической омонимии, выдавая в качестве результата все возможные парадигмы. Другой морфологический анализатор Myaso (http://nlpub.ru/Myaso) – это языконезависимый инструмент морфологической разметки текстов, построенный на основе скрытых марковских моделей с использованием удаленной интерполяции и алгоритма Витерби. К сожалению, текущая реализация Myaso имеет два серьезных недостатка: – таггер аварийно завершает работу при обнаружении в тексте слова, отсутствующего в словаре; – несмотря на то, что разметка текста выполняется достаточно быстро, единовременная инициализация анализатора занимает продолжительное время (около минуты). Для разметки тренировочного корпуса был выбран TreeTagger для русского языка [10]. TreeTagger – это вероятностный инструмент для разметки текстов, разрешающий морфосинтаксические неоднозначности русского языка. Анализ морфологической разметки показал, что в зависимости от того, выражает ли автор свой настрой или нет, он склонен использовать различные части и формы речи для построения предложений. Так, например, авторы твитов, содержащих положительные эмоции, часто используют глаголы 3-го лица единственного числа в настоящем времени в пассивном залоге совершенного вида – «Vmip3s-p-e», в свою очередь, авторы негативно окрашенных твитов чаще всего используют в своих сообщениях глаголы женского рода в единственном числе в прошедшем времени в активном залоге совершенного вида – «Vmps-sfafea» (http://www.swsys.ru/uploaded/image/2015/2015_dop/2.jpg). Был проведен анализ биграмм частей речи. С точки зрения попарного использования частей речи авторы положительных твитов чаще всего используют связку «глагол мужского рода совершенного вида в пассивном залоге в единственном числе в прошедшем времени + количественное числительное» – «Vmps-smpsp Mc» (таблица обозначений частей речи: http://corpus.leeds.ac.uk/mocky/ru-table.tab). Авторы негативных твитов часто пользуются связкой «неодушевленное существительное женского рода множественного числа в винительном падеже + местоимение в третьем лице множественного числа в дательном падеже» – «Ncfpan P-3-pdn» (см. http://www.swsys.ru/uploaded/ image/2015/2015_dop/3.jpg). Построение словаря эмоциональной лексики Алгоритмы классификации текстов методами векторного анализа с применением n-граммных моделей показывают достаточно точные результаты классификации [1, 2]. Для таких алгоритмов классификации и требуется предварительно размеченный тренировочный корпус, на основе которого происходит обучение. Для построения векторной модели текста создается словарь униграмм и биграмм. В предложенном методе в качестве однословных униграмм выделялись все слова документа, за исключением предлогов, знаков препинания (таких как запятая, точка с запятой, двоеточие, тире, точка; восклицательные и вопросительные знаки были оставлены), имен собственных, значимых событий (например олимпиада). Все ссылки на другие документы были объединены одним словом «Link», и их вес рассчитывался исходя из встречаемости «Link» во всех текстах коллекции. Словарь униграмм. Существуют различные подходы к извлечению оценочных слов из текстов и определению их веса в коллекции. В работе [11] авторы предложили использовать тезаурус для расширения словаря оценочных слов, собранного вручную. В корпусной лингвистике широко применяются методы извлечения терминов, основанные на значимости этого термина для коллекции, например на мере TF-IDF:
где tf – частота встречаемости термина в коллекции (положительных или отрицательных твитов); T – общее число сообщений в положительных и отрицательных коллекциях; T(ti) – число сообщений в положительной и отрицательной коллекциях, содержащих термин [12]. Однако методы извлечения терминов, основанные на мере TF-IDF, на коллекции текстов из разных классов показали результаты хуже, чем методы, основанные на мере RF (Relevance Frequency – релевантная частота) [13]. Основной смысл меры RF в том, что вес слова вычисляется на основе информации о распределении этого слова в текстах коллекции и учитывает принадлежность текстов коллекции к определенным классам (положительные, отрицательные, нейтральные) (табл. 2). Таблица 2 15 самых значимых слов для коллекции положительных твитов и негативных твитов Table 2 15 the most important words for a collection of positive and negative tweets
В работе [13] показано, что мера RF дает лучшие результаты бинарной классификации при вычислении веса слова с учетом принадлежности слова к разным классам. Поэтому для каждого слова каждой из коллекций вычислялся вес этого слова по мере RF. Обозначим a количество твитов, содержащих слово и относящихся к определенному классу, с – количество твитов, содержащих слово и не принадлежащих к классу С. Тогда значимость слова для класса С вычисляется по формуле
Построенный словарь состоит из 22 000 униграмм и их весов. Словарь не принадлежит к какой-либо заранее определенной предметной области и может быть использован для классификации как отзывов на товары, книги, так и новостных текстов. Словарь биграмм. Помимо словаря употребления отдельных слов в коллекциях, был построен словарь биграмм. Веса биграмм также рассчитывались на основе меры RF (табл. 3). Таблица 3 Пример значимых биграмм для коллекций положительных и негативных твитов Table 3 An example of important bigrams for a collection of positive and negative tweets
В результате работы был создан программный комплекс для сбора и анализа коротких сообщений на русском языке. С помощью программного комплекса построен корпус текстов, собранных на основе постов социальной сети twitter. Корпус автоматически размечен на три класса: положительные, негативные, нейтральные (коллекции содержат 114 991 положительный твит, 111 923 негативных твита и 107 990 нейтральных). Каждый текст в корпусе содержит атрибуты, позволяющие сделать выводы об актуальности высказывания и силе его воздействия на читателей, значимости сообщения (например, количество подписчиков пользователя или копирований данного сообщения пользователями площадки). Программный комплекс позволяет проводить морфологическую разметку текстов. На основе морфологической разметки были выявлены закономерности зависимости тоновой окраски сообщения от используемых в нем частей речи. На основе корпуса была проведена работа по построению словаря n-грамм, в который вошли как отдельные термины, так и биграммы. Корпус представлен в виде базы данных и доступен для публичного ознакомления по ссылке http://study.mokoron.com. В перспективе проведение экспериментов и тренировка тонового классификатора с помощью вышеописанного корпуса, а также сбор нового корпуса коротких текстов и проверка тонового классификатора на текстах, собранных в другой временной промежуток, когда интернет-пользователей волнуют другие темы. Литература 1. Pang B., Lee L., Shivakumar V. Thumbs up? Sentiment Classification using Machine Learning Techniques. Proc. of the Conf. on Empirical Methods in Natural Language Processing, Univ. of Pennsylvania, 2002, pp. 79–86. 2. Pang B., Lee L. Seeing stars: exploiting class relationships for sentiment categorization with respect of rating scales. Proc. of ACL, 43rd Meeting of the Association for Computational Linguistics. Ann Arbor: ACM, 2005, pp. 115–124. 3. Российский семинар по оценке методов информационного поиска (РОМИП). URL: http://romip.ru/ru/collections/ imhonet-films.html (дата обращения: 2.08.2014). 4. Chetviorkin I., Loukachevitch N. Cross-domain opinion word extraction model. Proc. 6th Russian Young Schientists Conf. in Information Retrieval. Yaroslavl, 2012, pp. 5–15. 5. Wilson T., Wiebe J. and Hoffmann P. Recognizing contextual polarity in phreselevel sentiment analysis. Proc. of Human Languages Technologies Conf. Conference on Emperical Methods in Natural Language Processing (HLT/EMNLP 2005). Vancouver, CA, 2005. 6. Read J. Using Emoticons to Reduce Dependency in Machine Learning Techniques for Sentiment Classification. In: Proc. of the Student Research Workshop at the 2005 Annual Meeting of the Association for Computational Linguistics. Ann Arbor, Michigan, 2005, pp. 43–48. 7. Рубцова Ю.В. Метод построения и анализа корпуса коротких текстов для задачи классификации отзывов // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: RCDL’2013: тр. XV Всерос. науч. конф., Ярославль, 2013. С. 269–275. 8. Reed J.W., Jiao Y., Potok T.E., Klump B.A., Elmore M.T., Hurson A.R. TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams. Proc. Machine Learning and Applications, (ICMLA '06). 2006, pp. 258–263. 9. Segalovich I. A Fast Morphological Algorithm with Unknown Word Guessing Induced by a Dictionary for a Web Search Engine. MLMTA, 2003, pp. 273–280. 10. Schmid H. Probabilistic part-of-speech tagging using decision trees. Proc. of the Intern. Conf. on New Methods in Language Processing. 1994, pp. 44–49. 11. Hu M., Liu B. Mining and Summarizing Customer Reviews. KDD, Seattle, 2004, pp. 168–177. 12. Salton G., Buckley C. Term-weighting approaches in automatic text retrieval. Journ. of Information Processing and management, 1988, no. 24 (5), pp. 513–523. 13. Lan M., Tan C.L., Su J., Lu Y. Supervised and Traditional Term Weighting Methods for Automatic Text Categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, vol. 31, no. 4, pp. 721–735. |


 , (1)
, (1) . (2)
. (2)| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3962&lang= |
Версия для печати Выпуск в формате PDF (12.50Мб) Скачать обложку в формате PDF (0.36Мб) |
| Статья опубликована в выпуске журнала № 1 за 2015 год. [ на стр. 72-78 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Применение байесовской сети в задаче классификации структурированной информации
- Метод частотно-морфологической классификации текстов
- Методы автоматической классификации текстов
- Интеллектуальная система автоматического определения категории потенциальных адресатов текста
- Трансдуктивное обучение логистической регрессии в задаче классификации текстов
Назад, к списку статей