Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Семантическая аннотация и многоаспектная модель данных в управлении требованиями
Аннотация:Выгода от повторного использования требований в IT-производстве ставит задачу поиска требований, учиты-вающего их семантику. Задачу предлагается решать с помощью категоризированной семантической аннотации тре-бований. Для этого используется метод категоризованной семантической аннотации, учитывающий структурные особенности формулировки требований. В качестве области применения рассматривается IT-проект по разработке и внедрению АСУ документооборотом вуза и его подразделений.
Abstract:Benefits from requirements reuse implies a problem of semantics-driven requirements retrieval. The solution employs categorized semantic annotation of requirements. Proposed is a method for semantic annotation, considering structural features of requirements wordings. The method is applied in an IT-project concerning development and deployment of computer-aided system for the university departments document workflow.
| Авторы: Сулейманова А.М. (suleymanova.ufa@gmail.com) - Уфимский государственный авиационный технический университет, кандидат технических наук, Яковлев Н.Н. (nikolay.iakovlev@gmail.com) - Уфимский государственный авиационный технический университет | |
| Ключевые слова: семантический поиск, модель данных, аспект, управление требованиями, концепт, семантическая аннотация, требование |
|
| Keywords: semantic search, Data Model, dimension, requirements management, concept, semantic annotation, requirement |
|
| Количество просмотров: 13434 |
Версия для печати Выпуск в формате PDF (5.35Мб) Скачать обложку в формате PDF (1.27Мб) |
Большинство бизнес-процессов любой современной организации подлежат полной или частичной автоматизации и информатизации на основе аппаратно-программного комплекса (АПК), который формируется, а впоследствии эволюционирует в соответствии с требованиями, предъявляемыми бизнесом. Каждая итерация развития АПК представляет собой IT-проект, результатом которого является очередной релиз АПК, и, следовательно, проистекает по всем общепринятым правилам проектного менеджмента. В научно-исследовательской работе CHAOS [1], выполненной Standish Group, указаны 10 факторов, которые не позволяют вовремя выпускать IT-проект, придерживаться установленного бюджета и предоставлять требуемую функциональность заказчику. Самые значимые из них – недостаток данных от пользователей, незаконченные требования и спецификации, изменение требований и спецификаций. Очевидно, что все три наиболее значимых фактора неудач IT-проектов связаны с требованиями, и эффективное управление требованиями (УТ) может сократить долю неудач. Требования являются одним из ключевых компонентов проекта в соответствии с международным стандартом PMBoK4 (свод знаний по управлению проектами) [2] и в соответствии с общепринятой методологией IBM Rational Unified Process, с которой разработка или эволюция ПО должны сопровождаться УТ к ПО и, как следствие, управлением ответами или реакциями на эти требования. Аналогичное условие выдвигают отечественные стандарты на информационные технологии – ГОСТ Р ИСО/МЭК 12207 и ГОСТ Р ИСО/МЭК 15288. Принципиальное отличие жизненного цикла (ЖЦ) информационной системы и материальной в том, что продукт производства информационной системы может применяться неограниченное количество раз в любой географической точке, доступной по каналу передачи данных. Особенно это актуально для информационного производства на основе сервисно-ориентированной архитектуры (СОА). Продукт производства материальной системы на стадии применения ограничен как количественно, так и в возможности перемещения. Особенностями разработки АСУ документооборотом (АСУД) вуза и его подразделений являются сбор большого массива требований по подразделениям несколькими аналитиками и реализация этих требований группой разработчиков и специалистов по внедрению. В такой ситуации повышается риск дублирования и противоречивости требований, а также неоднократной реализации одинаковых или схожих требований, то есть нерационального распределения трудовых ресурсов данного IT-проекта. Целью УТ при управлении одним проектом является предоставление возможности контроля целостности требований, то есть избежание их дублирования и противоречивости. Требования могут дублироваться и противоречить друг другу, если в проекте участвуют более одного аналитика или проект растянут во времени (1 год или более). Также при управлении несколькими проектами целью УТ является использование требования из одного проекта в одном или нескольких других проектах. Актуальность повторного использования обусловлена и ростом популярности СОА АПК, один из принципов которой – повторное использование требований и моделей. Основными задачами при этом являются произведение семантической аннотации (СА) требований и быстрый автоматизированный поиск требований, семантически близких к заданному, на основе имеющейся СА, а также оперативное представление данных о требованиях в виде отчетов. Решение этих задач выводит процедуры работы с данными о требованиях на качественно новый уровень, поэтому в работе описаны задача пересмотра модели данных требования в IT-проекте и подход к ее решению в виде многоаспектной логической модели данных и метаданных. Трудность заключается в том, что каждое требование представляет собой текст на естественном языке, вникнуть в семантику которого непросто даже человеку. При этом требование имеет несемантические атрибуты, представляющие интерес для команды проекта: трудоемкость, комментарий архитектора, статус, ссылку на уже имеющееся решение и т.п. Вместе с тем требования на систему среднего масштаба могут исчисляться сотнями, что делает практически невозможной мануальную работу с ними и предполагает необходимость автоматизации. Очевидно, что без надлежащей формализации представления требований автоматизация невозможна. К системам среднего масштаба относится АСУД вуза и его подразделений. Для разработки такой системы в Уфимском государственном авиационном техническом университете (УГАТУ) существует около 50 бизнес-правил, 350 функциональных требований, а также около 100 требований технологического характера. Рассмотрим математическую постановку задачи. Домен – это группа проектов, объединенных в семантическое пространство, то есть пересечение множеств их концептов достаточно велико. Это могут быть проекты по доработке одного и того же исходного решения либо по автоматизации схожих процессов. Проект имеет множество требований, каждое включает в себя текстовую формулировку, семантические данные, служащие координатными с точки зрения поиска, и атрибутивные данные. Все требования проекта – это модель системы, являющейся целью (планируемым результатом) проекта в терминах требований: D={d1, d2, …, dn} – множество предметных областей (доменов), nÎN; Concepti – множество концептов i-го домена, Целью настоящего исследования является разработка метода, позволяющего аналитику получить для требования Данной проблематике посвящен ряд работ. Так, в [3] описывается подход к повторному использованию требований, однако не рассматриваются методы их СА. В работе [4] предлагаются подходы к семантической аннотации процессных моделей и проектируется прототип программного средства для управления семантикой процессных моделей, однако не рассматриваются УТ, представленные в виде текста на естественном языке. В работе [5] рассматривается комплексное средство использования знаний о проекте и УТ, но в ней излагаются требования не к ПО в IT-проекте, а к инженерным сооружениям. Ни в одной из перечисленных работ не рассматривается СА требований, сформулированных на естественном языке. Подход к семантическому поиску Семантическая аннотация требований – это смена вербальной семиотической системы выражения требования на концептуальную семиотическую систему, у которой степень формализации семантики с точки зрения требования максимальна. Предлагается описывать каждое требование с помощью конечного множества концептов, то есть производить их СА. Совокупное множество концептов всех требований в проекте или группе проектов также должно быть конечным. Предлагается метод СА требования, основанный на разделении концептов требования на категории с учетом специфики инженерии требований и ее методологий. В соответствии с устоявшейся практикой требование всегда содержит такие категории, как субъект, действие, объект и обстоятельство. В рамках определенной предметной области набор категорий можно расширить, например, для АСУД вузом можно добавить такие категории, как документ, модуль, адресат. Концепты предлагается разбивать по этим категориям. В рамках одной предметной области число категорий, следовательно, и число аннотирующих концептов, всегда будет одинаково, что позволит следующее: – представлять аннотацию требования в виде вектора, а в качестве меры сходства требований использовать расстояние Хэмминга; – делать идентифицирующие семантические данные еще и координатными; – строить многомерное пространство концептов, в котором каждое требование является точкой с заданными координатами (это может служить основанием для многомерного OLAP-анализа как еще одного средства повышения качества визуализации данных о требованиях). Вектор требований – это по сути (n-1)-местный предикат, где n – число категорий требований, актуальных для данной предметной области. Категории образуют n-мерное пространство. В рамках одного проекта и всего домена число категорий постоянно. Аннотация может производиться как вручную (вводом концепта с клавиатуры или выбором из списка уже имеющихся), так и автоматически (система обрабатывает текст требования с учетом морфологизации и, если находит в тексте требования слово, уже зафиксированное ранее как концепт этого домена, автоматически подставляет значение в соответствующее поле). Отметим, что авторами предпринята попытка впервые представить метод СА для требования в IT-проекте на естественном языке, учитывающий структурную специфику требования и предусматривающий единообразную категоризацию аннотирующих концептов для всех требований в рамках проекта. Подход к логической модели данных о требованиях Обозначим множество атрибутов одного требования как Attr(R), где R – требование. Тогда A(F, U, S)={a1; a2; …; an}, nÎN, где F – область знаний (field, для данной работы перечень областей взят из [2]); U – роль пользователя (User); S – стадия ЖЦ; при Таким образом, выделены три аспекта, один из которых определяет основание для визуальной группировки атрибутов, а два других (роль пользователя и стадия ЖЦ) – может ли текущий пользователь редактировать или вводить данный атрибут на данной стадии ЖЦ, что служит основанием для многоаспектного разграничения доступа к данным о требованиях и, следовательно, повышает уровень целостности данных. В соответствии с этой метамоделью данных построена многоаспектная логическая модель данных, фрагмент которой представлен в таблице. Перспективы исследования Актуальными представляются классификация требований (например, между требованиями на исправление ошибки и требованиями на разработку функциональности), а также определение трудоемкости (не точное, а на уровне интервала) выполнения требования. Классификация при условии семантической аннотированности требования представляется типичной задачей интеллектуального анализа данных (Data Mining), где необходимо определить нужную категорию сущности в зависимости от ее дискретных либо количественных характеристик на основе прецедентов, то есть требований, трудоемкость и другие характеристики которых уже установлены опытным путем (за счет реализации).
Результатом реализации данного подхода стала система управления требованиями SemanticReq (semreq.anna-marry.ru), позволяющая вести учет требований в проектах, производить семантическую аннотацию требований с учетом их семантических категорий, а также осуществлять поиск требований на основе произведенной семантической аннотации. Система используется в проектах, связанных с автоматизацией документооборота кафедр и деканата УГАТУ. В результате использования было выявлено 6 дубликатов и 4 противоречия внутри проектов, а также найдено 5 требований, аналогичных уже реализованным, что позволило избежать дополнительных затрат на разработку. Литература 1. CHAOS // The Standish Group Report, 1995. URL: http://www.cs.nmt.edu/~cs328/reading/Standish.pdf (дата обращения: 11.11.2009). 2. Project Management Body of Knowledge v. 4 // Project Management Institute. URL: www.pmi.org (дата обращения: 14.01.2010). 3. Park Soyong. Software Requirement Text Reuse. URL: ftp://ftp.umcs.maine.edu/pub/WISR/wisr6/proceedings/ps/park2.ps (дата обращения: 18.08.2010). 4. Yun Lin. Semantic Annotation of Process Models. Facilitating Process Knowledge Management via Semantic Interoperability // Thesis for the degree of Ph.D. URL: http://ntnu.diva-portal.org/smash/get/diva2:124135/FULLTEXT01 (дата обращения: 03.01.2010). 5. David Baxter, James Gao, Keith Case et al. An engineering design knowledge reuse methodology using process modelling. URL: https://dspace.lib.cranfield.ac.uk/handle/1826/1856 (дата обращения: 23.01.2010). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
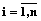 , с точки зрения векторного анализа является базисом;
, с точки зрения векторного анализа является базисом;  – множество проектов i-го домена,
– множество проектов i-го домена, 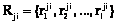 – множество требований j-го проекта i-го домена,
– множество требований j-го проекта i-го домена, 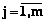 ;
; 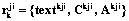 – вектор атрибутов k-го требования,
– вектор атрибутов k-го требования,  , j-го проекта i-го домена, где textkji – текстовая формулировка требования,
, j-го проекта i-го домена, где textkji – текстовая формулировка требования,  – множество концептов, а каждый концепт
– множество концептов, а каждый концепт  принадлежит суммарному множеству, то есть
принадлежит суммарному множеству, то есть 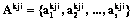 – множество несемантических атрибутов требования;
– множество несемантических атрибутов требования;  – число элементов пересечения двух множеств концептов, определяет сходство требований
– число элементов пересечения двух множеств концептов, определяет сходство требований 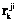 и
и 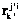 : чем больше элементов пересечений, тем сильнее сходство. Следует обратить внимание, что литера i не имеет штриха – домен для обоих требований один и тот же. Задача аналитика: задав множество
: чем больше элементов пересечений, тем сильнее сходство. Следует обратить внимание, что литера i не имеет штриха – домен для обоих требований один и тот же. Задача аналитика: задав множество 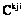 для исходного требования
для исходного требования  , найти одно или несколько требований
, найти одно или несколько требований 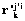 , для которых
, для которых 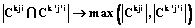 , чтобы получить доступ к
, чтобы получить доступ к 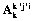 .
.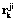 множество концептов
множество концептов | Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2760&lang= |
Версия для печати Выпуск в формате PDF (5.35Мб) Скачать обложку в формате PDF (1.27Мб) |
| Статья опубликована в выпуске журнала № 2 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Открытость структур в эволюционной модели данных
- Система корпус-менеджер: архитектура и модели корпусных данных
- Об одном подходе к реализации системы управления мастер-данными об активах
- Инфраструктурная модель профессионального Интернета (Special Web)
- Основные понятия формальной модели семантических библиотек и формализация процессов интеграции в ней
Назад, к списку статей