Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Комбинирование классификаторов на основе теории нечетких множеств
Аннотация:В статье рассматривается применение методов теории нечетких множеств для решения задачи комбинирования простых классификаторов с целью улучшения качества классификации и расширения вида классифицируемых объ-ектов. Эффективность предложенных алгоритмов оценивается на задаче распознавания текста. Даются рекомендации по применимости рассмотренных алгоритмов.
Abstract:Fuzzy set approach for combining of multiple classifiers is introduced. Proposed algorithms are evaluated on the optical character recognition task. Advices on usage of considered algorithms are given.
| Авторы: Багрова И.А. (sytnik@complexsys.ru) - ООО «Комплексные системы», г. Тверь, Пономарев С.А. (sytnik@complexsys.ru) - ООО «Комплексные системы», г. Тверь, Россия, Сорокин С.В. (sergey@tversu.ru) - Тверской государственный университет, Тверь, Россия, Сытник Д.А. (sytnik@complexsys.ru) - ООО «Комплексные системы», г. Тверь, кандидат технических наук | |
| Ключевые слова: распознавание текста, нечеткие множества, классификация |
|
| Keywords: optical character recognition, fuzzy sets, classification |
|
| Количество просмотров: 14317 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
При разработке системы распознавания печатных кириллических символов авторы столкнулись с необходимостью создания специального классификатора, который должен распознавать множество начертаний символов, различающихся шрифтом, размером и стилем. Создание и обучение подобного классификатора в виде одной монолитной системы, скажем, одной искусственной нейронной сети, весьма сложно. Популярным подходом при решении сложных задач классификации является применение принципа «разделяй и властвуй», который получил распространение как в системах распознавания [1], так и в других задачах анализа данных, например, в алгоритме Matrixnet, применяемом поисковой системой Яндекс. Этот подход предполагает создание и обучение набора простых классификаторов, распознающих определенные типы объектов, и последующее комбинирование результатов их работы. Одной из наиболее распространенных технологий создания простых классификаторов являются искусственные нейронные сети. Классификаторы такого типа имеют по одному выходу на каждый распознаваемый класс, при этом одновременно несколько выходов могут иметь ненулевые значения. Интерпретация этих значений часто проводится в рамках теории вероятности, однако сложность в данном случае состоит в том, что выходы нейронных сетей не соответствуют базовому положению теории вероятности о том, что сумма вероятностей должна равняться 1. Для решения этой проблемы применялись различные способы, позволяющие по выходу сети определить вероятность принадлежности объекта тому или иному классу [2]. В статье рассматривается альтернативный подход к интерпретации результатов работы такого классификатора. Авторы предлагают опираться не на теорию вероятностей, а на теорию нечетких множеств, введенную Заде [3]. В этом случае выход нейронной сети может быть непосредственно интерпретирован как нечеткое подмножество множества распознаваемых классов, где каждый выход сети указывает степень принадлежности каждого конкретного объекта данному классу, представляемую числом в диапазоне [0, 1]. Определение 1. Нечетким подмножеством (множеством) A (в) X называется совокупность упорядоченных пар вида
где μA(x) представляет собой степень принадлежности x к A. Отметим, что, в отличие от вероятностной интерпретации, в данном случае не требуется, чтобы сумма выходных значений классификатора равнялась 1. Неопределенность, моделируемая в рамках теории нечетких множеств, позволяет рассматривать значение каждого выхода как степень близости классифицируемого изображения к эталону соответствующей буквы, использованному при обучении нейронной сети. Такая интерпретация является более естественной, чем предлагаемая в рамках теории вероятностей. Таким образом, выходом каждого классификатора является нечеткое подмножество множества распознаваемых символов. Результаты вычислений отдельных классификаторов могут комбинироваться с использованием тех или иных операций с нечеткими множествами. Это приводит к архитектуре сложного классификатора в виде дерева, листьями которого являются простые классификаторы, а внутренние узлы соответствуют операциям комбинирования. Алгоритмы комбинирования, основанные на теории нечетких множеств Рассмотрим результаты применения некоторых механизмов теории нечетких множеств для комбинирования выходов классификаторов, в частности t- и s-нормы. Треугольные нормы, или t-нормы, являются известным механизмом агрегирования информации, применяющимся для вычисления пересечения нечетких множеств. Определение 2. Отображение T: [0, 1]´[0, 1]→ →[0, 1] называется t-нормой, если для любых x, y, z, wÎ[0, 1] выполняется следующее: · граничные условия: T(0, 0)=0, T(1, x)=T(x, 1)=x; · симметричность: T(x, y)=T(y, x); · ассоциативность: T(x, T(y, z))=T(T(x, y), z); · монотонность: T(w, y)≤T(x, z), если w≤x и y≤z. В качестве примеров t-норм рассмотрены операции произведения TP(x, y)=xy и взятия минимума TM(x, y)=min{x, y}. Соответствующие алгоритмы комбинирования состоят в вычислении t-нормы над входными нечеткими множествами и в дальнейшем будут обозначаться TP и TM соответственно. Объединение нечетких множеств вычисляется с помощью s-норм (или t-конорм). Определение 3. Треугольной t-конормой (t-конормой, s-нормой) называется отображение S: [0,1]´[0,1]→[0,1], удовлетворяющее следующим условиям: · граничные условия: S(1, 1)=1, S(0, x)=S(x, 0)=x; · симметричность: S(x, y)=S(y, x); · ассоциативность: S(x, S(y, z))=S(S(x, y), z); · монотонность: S(w, y)≤S(x, z), если w≤x и y≤z. В качестве примера s-нормы рассмотрена операция взятия максимума SM(x, y)=max{x, y}. Алгоритм комбинирования SM состоит в вычислении этой s-нормы над входами. Наряду с операциями объединения и пересечения нечетких множеств рассмотрены еще две операции. В работе [4] предлагается другой способ нечеткой интерпретации выхода двух нейронных сетей. Если выход одной из сетей есть x1, а другой x2 (считаем, что x1≤x2), то авторы предлагают рассматривать результат комбинации как нечеткий интервал [x1, x2], к которому затем применяется центроидный метод дефаззификации, что дает значение (x1+ x2)/2. Чтобы расширить эту технику на большее число комбинируемых классификаторов, воспользуемся результатами [5], согласно которым модальное значение несимметричного нечеткого множества, построенного на основе ряда наблюдаемых значений x1, …, xn, есть их среднее арифметическое (x1+…+xn)/n. Данный алгоритм обозначим Avg. Кроме того, авторами предложен алгоритм выбора наиболее уверенного эксперта. Последняя операция осуществляется путем выбора эксперта с минимальной энтропией функции принадлежности:
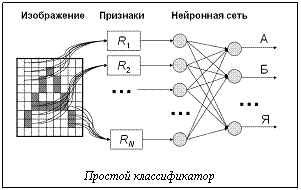
где x – элемент; X – множество элементов; μ(x) – уровень принадлежности элемента x множеству, Этот алгоритм обозначим Entropy. Методика тестирования Изучение алгоритмов классификации проводилось в рамках системы распознавания печатного текста. Для оценки эффективности предлагаемых методов было создано по 18 простых классификаторов, обученных распознавать следующие начертания шрифтов: Arial 14 и 18 pt, Times New Roman 14 и 18 pt. Системе распознавания текста, классификатор которой был построен путем той или иной комбинации указанных простых классификаторов, предлагалось распознать набор из 300 случайно выбранных из словаря слов средней длины 8,65 символа. Изображение каждого слова генерировалось с помощью функции печати текста операционной системы заданным шрифтом (который мог быть одним из приведенных выше плюс Arial 16 pt и Times New Roman 16 pt). Оценивалось число правильно распознанных слов. Работа использованного простого классификатора осуществляется в два шага (см. рис.). Сначала по исходному изображению вычисляются признаки. Значение каждого признака является функцией от яркостей некоторого подмножества пикселей изображения. В результате получается вектор значений признаков, который поступает на вход нейронной сети. Каждый выход сети соответствует одной из букв алфавита, а получаемое на выходе значение рассматривается как уровень принадлежности буквы нечеткому множеству. В данном случае использовались классификаторы, у которых число признаков равнялось 50, а нейронная сеть не содержала скрытых слоев. Как показали практические эксперименты, такая архитектура позволяет решать задачу распознавания символов одного начертания.
Комбинирование классификаторов, обученных распознавать одинаковые символы Рассмотрим задачу комбинирования результатов работы нескольких классификаторов, обученных распознавать символы одинакового начертания. Для проверки использовались группы классификаторов, обученных распознавать определенный шрифт, выходы которых комбинировались с помощью одного из 5 алгоритмов, описанных выше. Системе распознавания предлагалось прочитать текст, написанный тем же шрифтом, что использовался для обучения простых классификаторов. Результаты тестирования приведены в таблице 1. Таблица 1 Число распознанных слов при использовании классификаторов, обученных распознаванию символов одного начертания
Уже первые тесты показали низкую надежность использования произведения для комбинирования результатов классификации. В случае шрифта Times New Roman в результате работы классификатора с умножением в большинстве случаев для всех букв получались уровни принадлежности, очень близкие к 0, что не позволяло в дальнейшем получить корректное прочтение слова. Этот эффект также зависит от числа комбинируемых классификаторов: если их несколько, проблема стоит не так остро. Лучшие результаты показали алгоритмы выбора классификатора с наименьшей энтропией и наименьшего среднего. Комбинирование классификаторов, обученных распознавать символы разного размера Несмотря на то, что изображение буквы перед классификацией масштабируется до фиксированного размера (в данном случае 15´15 пикселей), начертания одних и тех же букв при использовании шрифтов разных размеров могут отличаться. На это влияют и погрешности, возникающие при масштабировании, и различия в самих шрифтах. В рассматриваемом примере использовалась двухуровневая схема построения классификатора. На первом уровне комбинировалось по 18 простых классификаторов, распознающих шрифты Arial 14 pt и Arial 18 pt. Два полученных в результате нечетких множества комбинировались алгоритмом второго уровня. В данном случае на примере шрифта Arial 18 pt выяснялось, насколько полученная система в целом сохраняет свои возможности по распознаванию шрифтов первого уровня (табл. 2). Кроме того, на шрифте Arial 16 pt проверялось, сможет ли она читать шрифт промежуточного размера, который не использовался при обучении простых классификаторов (табл. 3). Таблица 2 Число распознанных слов, написанных шрифтом Arial 18 pt
Примечание: в скобках дано изменение по сравнению с результатами из таблицы 1. Таблица 3 Число распознанных слов, написанных шрифтом Arial 16 pt
Таблица 4 Общее число слов, распознанных в данной группе тестов (из 600 слов теста)
Отметим, что во многих случаях добавление дополнительных классификаторов, обученных распознаванию шрифта Arial 14 pt, улучшило распознавание шрифта Arial 18 pt. В случае одноуровнего классификатора алгоритм выбора по лучшей энтропии показывал хорошие результаты, но его эффективность в качестве алгоритма для второго уровня оказалась низкой, особенно при распознавании шрифта, не использовавшегося для обучения сетей. Алгоритм вычисления среднего уровня принадлежности сохранил достаточно высокие позиции в качестве алгоритма как для первого, так и для второго уровня. Однако в обобщении на неизвестный шрифт и, как следствие, в общем итоге он уступил s-норме максимум, использованной на обоих уровнях. Комбинирование классификаторов, обученных распознавать различные начертания символов Для третьей группы тестов использовались шрифты одинакового размера, но разных начертаний, а именно шрифты Arial 14 pt и Times New Roman 14 pt. В этом случае также применялась двухуровневая схема, при которой на первом уровне обобщались классификаторы для одинаковых шрифтов, а второй уровень объединял полученные для двух шрифтов оценки. При этом оценивалось, сможет ли классификатор выбрать правильный шрифт из двух возможных. Результаты представлены в таблицах 5–7. Таблица 5 Число распознанных слов, написанных шрифтом Arial 14 pt
Примечание: в скобках дано изменение по сравнению с результатами одноуровнего классификатора соответствующего типа (таблица 1). Таблица 6 Число распознанных слов, написанных шрифтом Times New Roman 14 pt
Примечание: в скобках дано изменение по сравнению с результатами из таблицы 1. Таблица 7 Общее число распознанных слов (из 600 слов теста)
Примечание: в скобках дана разница по сравнению с гипотетическим классификатором, всегда выбирающим набор сетей, соответствующий использованному шрифту, и комбинирующим их соответствующим алгоритмом. Очевидно, что строка, соответствующая использованию алгоритма Entropy для шрифта Times New Roman, в точности повторяет результаты распознавания этого шрифта алгоритмами первого уровня, тогда как для шрифта Arial его результаты оказались плохими. При попытке применить Arial для комбинирования классификаторов, предназначенных для распознавания все более и более различающихся символов, эффективность этого алгоритма снижалась. Лучшей в данном случае оказалась комбинация, в которой на первом уровне использовалась t-норма минимум, а на втором производилось усреднение уровня возможности. Такая структура классификатора обеспечила максимальное суммарное число распознанных слов и сравнительно небольшие потери по сравнению с идеальным классификатором, не ошибающимся при выборе шрифта. Эта же конфигурация обеспечила и минимальное среднее число ошибок (то есть минимальное число удалений, вставок или замен, необходимых для получения правильного слова из предложенного системой распознавания варианта) для слов, которые не были найдены классификатором. Оно составило 1,22 для Arial и 1,99 для Times New Roman (без учета алгоритма Entropy, который показал более высокий результат на шрифте Times New Roman). Такой результат позволяет надеяться, что большинство ошибок может быть исправлено при использовании информации о частоте сочетаний букв и проверке по словарю. Использование на первом уровне минимума может показаться нелогичным, однако стоит вспомнить, что в рамках теории нечетких множеств эта операция используется для вычисления пересечения нечетких множеств. В данном случае получено обобщенное мнение экспертов, высокий результат в котором может быть только у альтернативы, достаточно высоко оцененной всеми. В то же время при использовании максимума ставшая лучшей альтернатива может иметь низкие оценки части экспертов. Это может говорить о том, что классифицируемый образ далек от образов обучающей последовательности для данной группы экспертов и вынесенное заключение является плохо обоснованным. Использование одного классификатора в пределах слова Таким образом, задача комбинирования классификаторов, распознающих схожие начертания символов, может быть успешно решена с помощью рассмотренных простых алгоритмов комбинирования. Однако результаты объединения с их помощью классификаторов, распознающих символы различных начертаний, нельзя признать удовлетворительными. Для улучшения работы было решено использовать информацию о распознавании других букв слова. Исходя из предположения о том, что слово, как правило, пишется символами одного шрифта, предложим следующий алгоритм. 1. Выполнить распознавание всех букв слова, запоминая на верхнем уровне классификатора, какому из классификаторов второго уровня отдавалось предпочтение при прочтении каждой буквы. 2. Определить классификатор второго уровня, который был выбран наибольшее число раз. 3. Выполнить повторное распознавание слова, используя определенный в п. 2 классификатор; использовать полученный вариант прочтения как окончательный. Указанный алгоритм имеет смысл при использовании на верхнем уровне такого алгоритма комбинирования, который выбирает один из нескольких входных векторов. В данном случае это алгоритмы TM, SM и Entropy. В таблицах 8–10 приведены результаты тестирования эффективности этого алгоритма при выборе между классификаторами, обученными распознавать шрифты Arial и Times New Roman. Методика тестирования полностью соответствует использованной ранее. Таблица 8 Число распознанных слов, написанных шрифтом Arial 14 pt
Примечание: в скобках дано изменение по сравнению с результатами из таблицы 1. Таблица 9 Число распознанных слов, написанных шрифтом Times New Roman 14 pt
Примечание: в скобках дано изменение по сравнению с результатами из таблицы 1. Таблица 10 Общее число распознанных слов для шрифтов размера 14 pt (из 600 слов теста)
Примечание: в скобках дана разница по сравнению с гипотетическим классификатором, всегда выбирающим набор сетей, соответствующий использованному шрифту, и комбинирующим их соответствующим алгоритмом. Можно видеть, что в данном случае алгоритм второго уровня TM, невзирая на распознаваемый шрифт, отдавал предпочтение классификатору для шрифта Arial, а SM – Times New Roman. В результате оба эти алгоритма не справились с поставленной задачей. Лучший результат был показан алгоритмом Entropy – ему удалось правильно различить почти все предложенные примеры для обоих шрифтов. Проведенные эксперименты показали, что подход, опирающийся на теорию нечетких множеств, наряду с другими методами может использоваться для комбинирования выходов нескольких классификаторов с целью улучшения их работы. При этом необходимо отметить следующее. · Использование t-нормы TP(x, y)=xy представляется нецелесообразным в связи с проблемами вычислительного характера. · Алгоритм вычисления среднего значения уровня принадлежности весьма эффективен в широком спектре возможных условий применения, но может быть превзойден алгоритмами, лучше адаптированными к конкретной задаче. · Алгоритм выбора нечеткого множества с минимальной энтропией может давать довольно хорошие результаты, но может оказаться и непригодным при комбинировании информации от разнородных классификаторов в отсутствие дополнительной информации. · Необязательно алгоритм, показавший высокие результаты в составе более простого классификатора, окажется лучшим выбором при комбинировании этого классификатора с другими. Выбор оптимальной архитектуры в значительной степени определяется рассматриваемой задачей и имеющимися простыми классификаторами. Рассмотренные в статье несложные способы комбинирования позволяют достичь хороших результатов при объединении простых классификаторов, обученных распознавать достаточно похожие друг на друга объекты. В случае выбора классификаторов, распознающих существенно различающиеся объекты, эффективность рассмотренных методов может быть улучшена за счет использования контекстной информации. При отсутствии такой информации представляется целесообразной разработка более сложных методов. Возможными направлениями решения этой проблемы могут быть создание отдельного классификатора, определяющего тип классифицируемого образа, на основании заключения которого производится выбор из имеющихся классификаторов, а также анализ близости классифицируемых образов к образам обучающих последовательностей классификаторов, возможно, реализованный в виде дополнительного выхода классификатора, оценивающего принадлежность образа к группе неизвестных. Литература 1. Ян Д.Е. Исследование, развитие и реализация методов автоматического распознавания рукописных текстов в компьютерных системах: дисс. … канд. физ.-мат. наук. М., 2003. 2. Denker J.S., leCun Y. Transforming Neural-Net Output Levels to Probability Distributions. AT&T Bell Labs Technical Memorandum, November, 1990. 3. Zadeh L.A., The concept of a linguistic variable and its application to approximate reasoning // Information Sciences, 1975, № 8, pp. 199–249; № 9, pp. 43–80. 4. Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O. Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms / Engineering Letters, 2006, 13:2. 5. Панфилов С.А. Методы и программный комплекс моделирования алгоритмов управления нелинейными динамическими системами на основе мягких вычислений. Дисс. … канд. технич. наук. Тверь, 2005. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
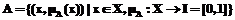 ,
,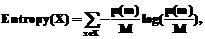
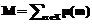 .
.
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2627 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
- Разработка теоретических основ классификации и кластеризации нечетких признаков на основе теории категорий
- Некоторые вопросы количественной оценки производительности детекторов границ
- Инструментальная система для решения задач многокритериального выбора
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
Назад, к списку статей